这是要导入的模块

一、数据规整化 – 合并数据集
- pd.merge :连接dataframe的行,实现的是数据库的连接操作
- concat: 沿一条轴将多个对象堆叠到一起
- combine_first:可以将重复数据编接在一起,用一个对象中的值填充另一个对象中的缺失值!
1.pd.merge合并数据集
(1)两个有相同列名的dataframe
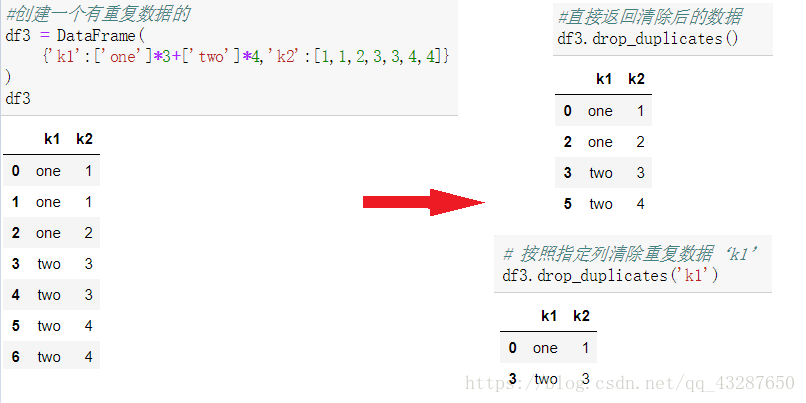
# 创建两个dataframe
df1 = DataFrame(
{
'key':list('bbacaab'),
'data1':range(7)
}
)
#通过字典来创建
df2= DataFrame(
{
'key':list('abd'),
'data2':range(3)
}
)
print('df1:\n',df1)
print('df2:\n{}'.format(df2))

# merge 连接 采用的是‘inner'连接的方式,取交集部分,没有交集的会舍弃掉
pd.merge(df1,df2)
# 默认情况下merge会将重复的列当作键来合并,建议使用on 来指定以什么来合并
pd.merge(df1,df2,on='key')
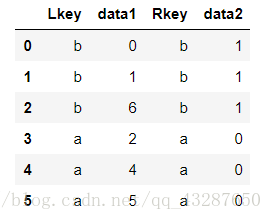
(2)两个无相同列名的dataframe进行合并


# 进行合并,以不同的列
pd.merge(df3,df4,left_on='Lkey',right_on='Rkey')
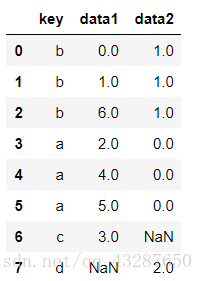
3.pd.merge参数 how = outer 作为合并参数取并集
pd.merge(df1,df2,how='outer')
(4)pd.merge() 参数:how=‘left’ 作为合并参数,以左边为主
pd.merge() 参数:how=‘right’ 作为合并参数,以右边为主
(5)以多个列名进行合并

pd.merge(df_left,df_right,on=['key1','key2'],how='outer')
df_left 指定以key1进行连接,df_right指定以key2进行连接,以取并集的方式连接
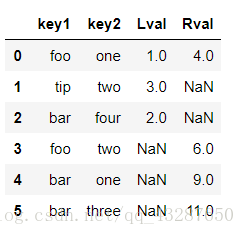
pd.merge(df_left,df_right,on=['key1','key2'],how='inner')
df_left 指定以key1进行连接,df_right指定以key2进行连接,取交集
总结:pandas.merge(df1,df2,on=’ ‘,how=’ ')
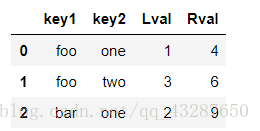

2.concat连接数据
语法:pandas.concat([s1,s2,…],axis=0或1,join=’ ',keys=[ ])
- 创建三个series,并用concat进行连接,结果是直接将之进行拼接
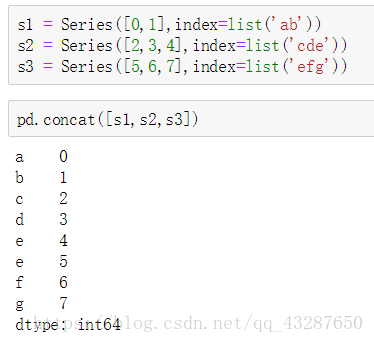
-
axis默认为0,竖着连接,数据直接拼接在后面;
-
axis=1时,横着连接,没有数据的显示nan
-
参数:join=‘inner’ 交集 ; join=‘outer’ 并集

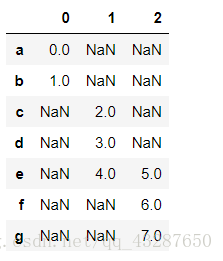
pd.concat([s1,s4],axis=1,join='outer') # 默认的连接方式,并集
pd.concat([s1,s4],axis=1,join='inner') # 交集
- 参数keys:连接时给层次索引
# 连接时给层次索引
s5 = pd.concat([s1,s2,s3],keys=['one','two','three'])

3.pd.combin_first()合并重叠数据
如果左边有值,显示左边的数据;
如果左边是nan,右边有值,则显示右边的数据;
如果左边和右边都是nan,则显示nan
语法:
s1.combine_first(s2)
s1 是左边的数据集,s2是右边的数据集。Series和Dataframe都可以使用
二、数据规整化–重塑与轴向选择
主要用于重塑表格型数据的结构
- stack :将列旋转为行
- unstack:将行旋转为列
1.series和DataFrame的相互转化
(1)对于一个层次化索引的series,可以使用unstack 将其转化为一个dataframe:
unstack()有两个参数:0或1
为0时:是默认的参数,将最外层的行索引转化为列索引
为1时:将最内层的行索引转化为列索引
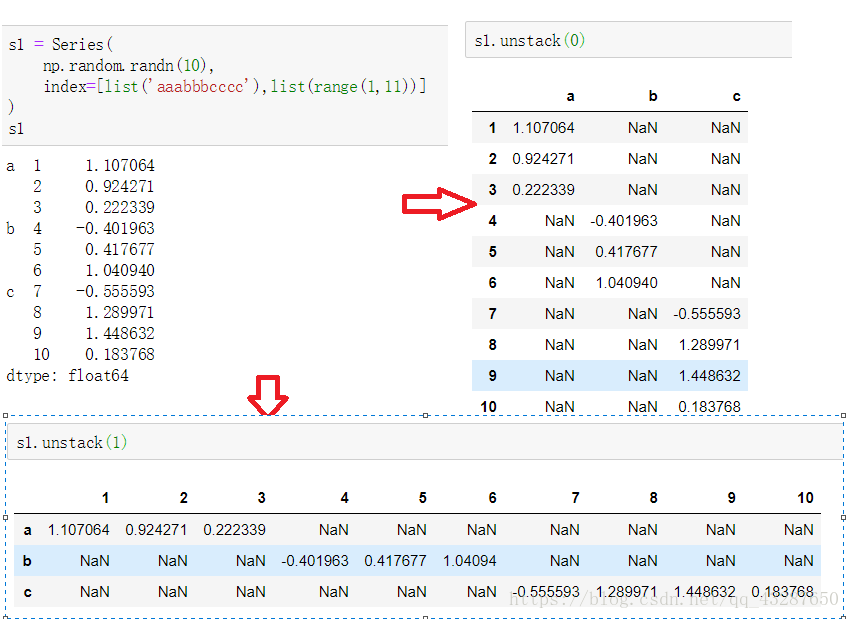
注意:unstack除了使用参数1,0来指定列,还可以通过索引的名称来进行指定,例如:
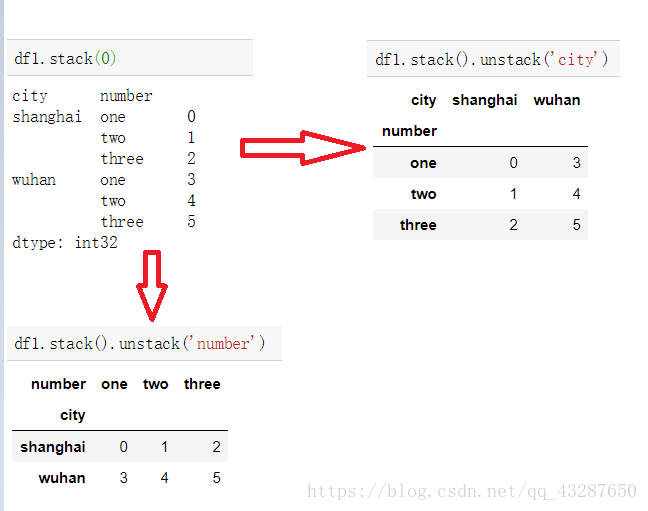
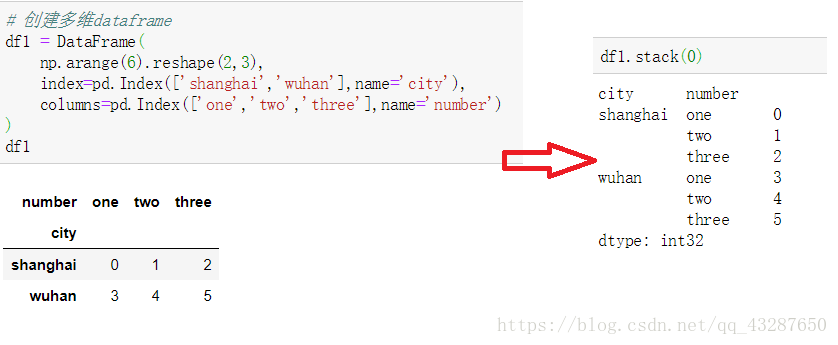
(2)对于一个多层次的DataFrame,使用df.stack()将之转化为series
stack 没有参数1,只有参数0
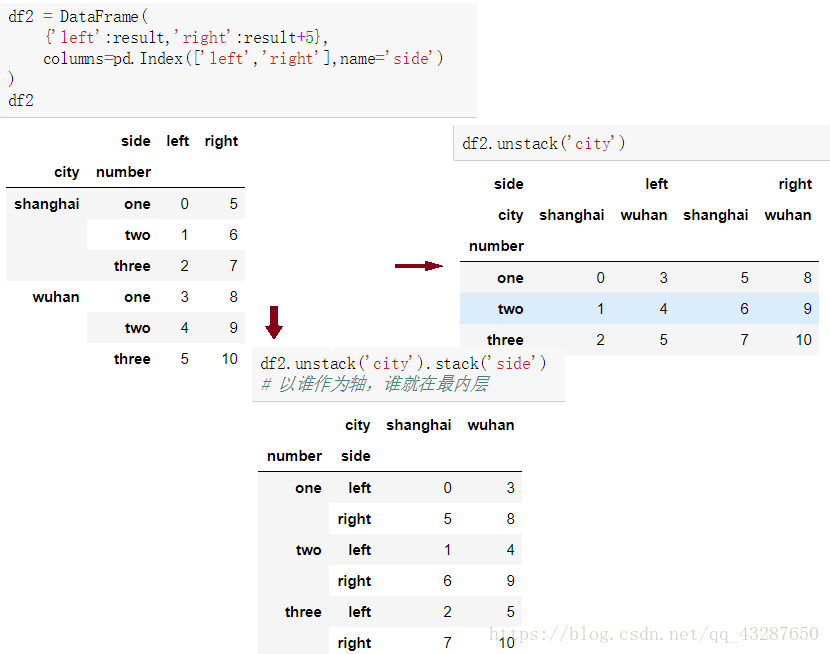
(3)对dataframe进行unstack和stack的时候,指定哪个索引名称旋转,哪个索引就会旋转为最低级别。
三、数据规整化-数据转换
1.清除重复数据
语法:xx.drop_duplicates()
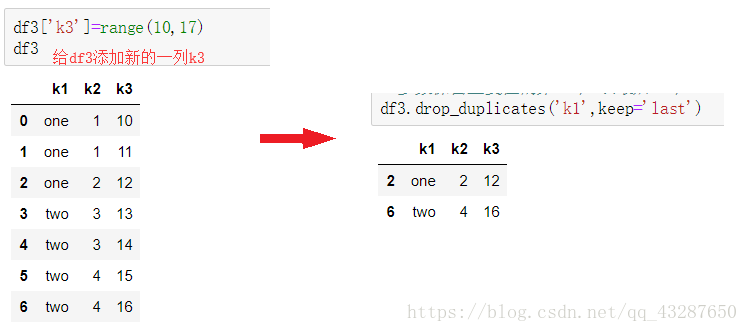
(1)按指定列清除重复数据
(2)保留重复值的第一个或最后一个。
keep=‘first’(默认) :保留重复值的第一个数据
keep=‘last’ :保留重复值的最后一个数据
2.利用函数和映射进行转换
步骤:
1、先编写一个映射
2、再利用map函数来进行映射
准备一个有映射的数据集:
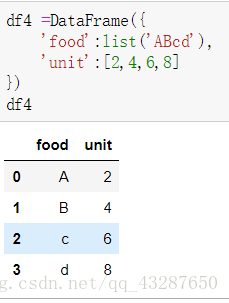
接下来我们要将以下的数据一一映射到上面的数据集中:
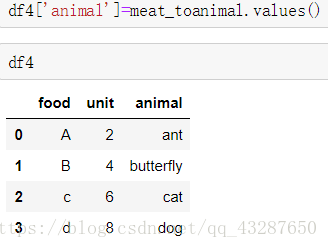
先试试直接将meat_toanimal 中的值直接添加到df4中,看似没有问题,但实际上只是扩展了一列,并没有进行一一映射。
现在,我们要来进行一一映射啦:
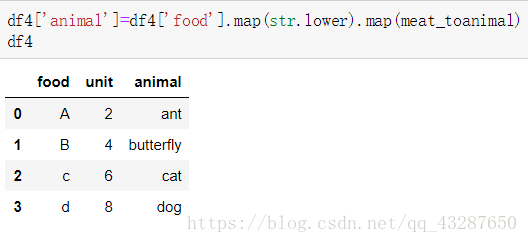
第一种方法:读取df4中的food列,将他们全部转化为小写的abcd,再和meat_toanimal进行一一映射。
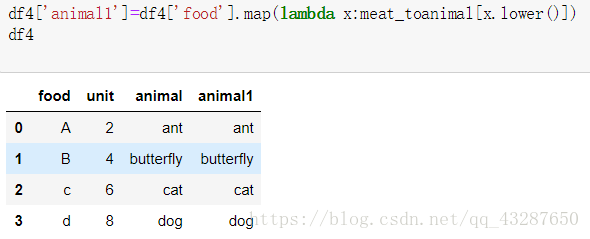
第二种方法:直接传入一个能使用此功能的函数

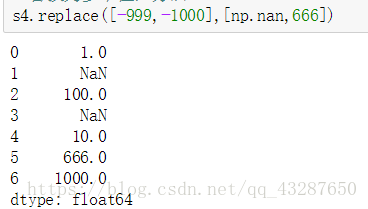
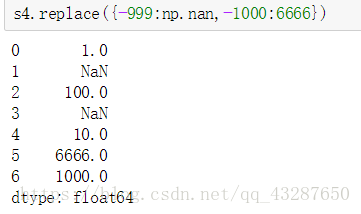
3.替换值
利用fi11na方法填充缺失数据可以看做值替换的一种特殊情况。虽然前面提到的map可用于修改对象的数据子集,而 replace则提供了一种实现该功能的更简单、更灵活的方式。
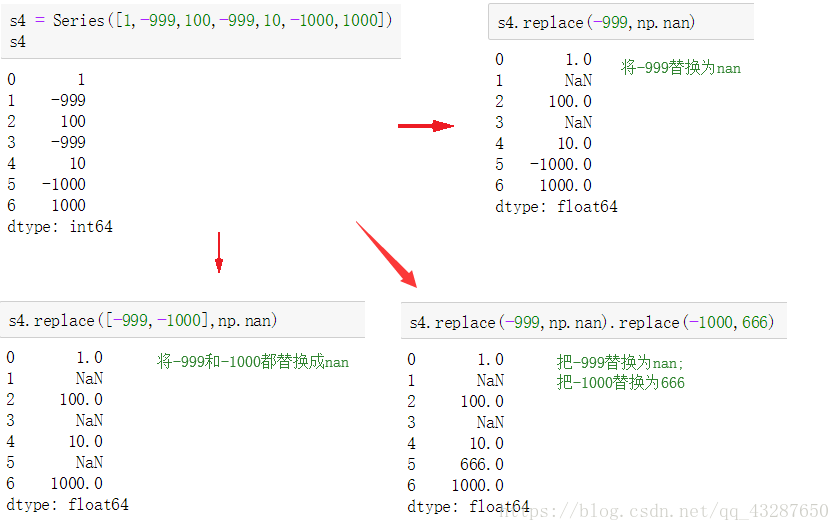
语法:xx.replace(原数据,替换的值)
注意:替换后原数据还是不变的
同时替换多个值的方法:
方法一:
方法二:
4.数据拆分
(1)cut:等分区间
语法:pandas.cut(数据,分箱,right=’ ',labels=[])
right默认为True,左闭右开,当right='False’的时候,就是左开右闭
labels:给区间取名称
【例1】
可以看到ages 按照bins进行cut,被分成了四个区间,返回的是区间而不是值,第一个数据17因为不在任何一个区间内,因此得到的是nan
一般来说,我们都要对分箱后的结果进行统计

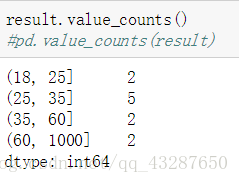
看看使用参数right的结果,right=‘False’ 区间变成左开右闭
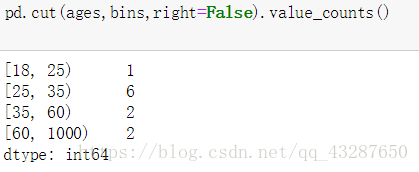
咱们给区间取个名儿吧~ labels=[]

【例2】前面的那个例子是我们自己定义了一个bins区间,当然我们也可以写上一个数字,表示自动将区间平均分为几等分
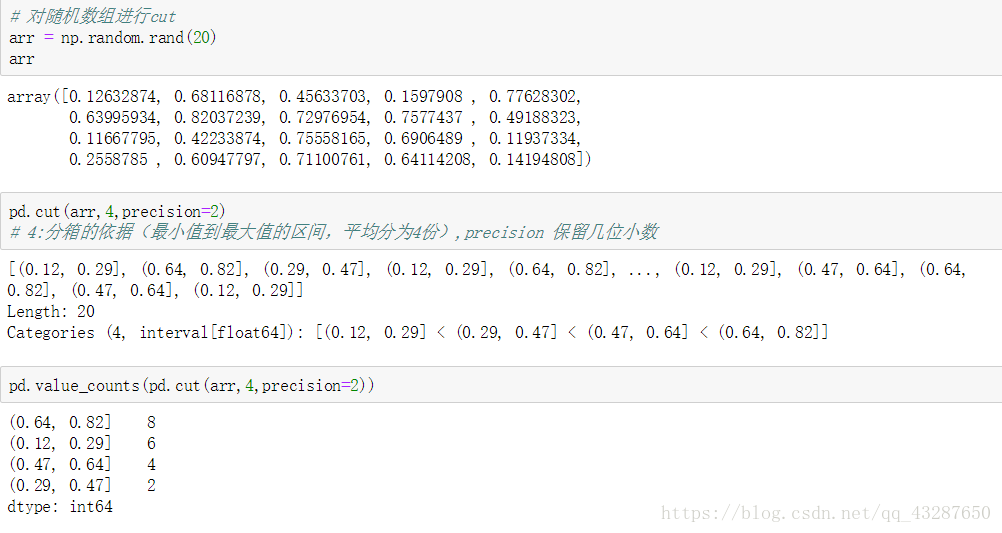
(2)qcut:等分值
如果不想等分值,可以定义份数:pd.qcut(x,q) q参数 如果是列表,范围是在0-1之间
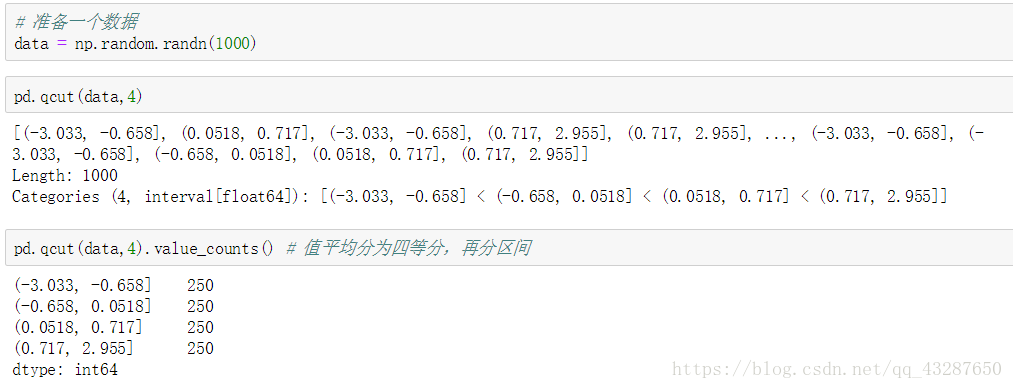
这是等分为4段的例子:

(重要)连续数据不等分 会根据 如:q=[0,0.1,0.3,0.6,1],每2个数的差值进行比例计算,把最大值和最小值插值的区间按照这个比例进行划分
这是把值分为1份、2份、3份、4份

5.检查和过滤异常值
异常值的过滤或变换运算在很大程度上其实就是数组运算。
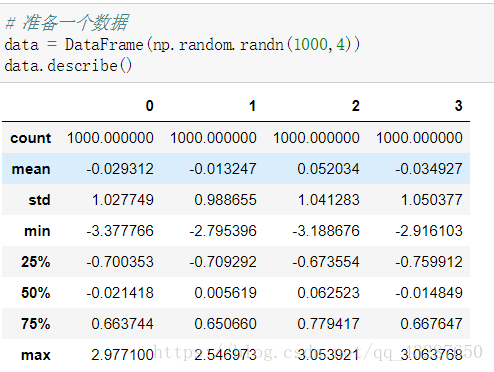
【案例】想过滤绝对值大于3的数
我们先准备一个数据集,统计看看大概情况:
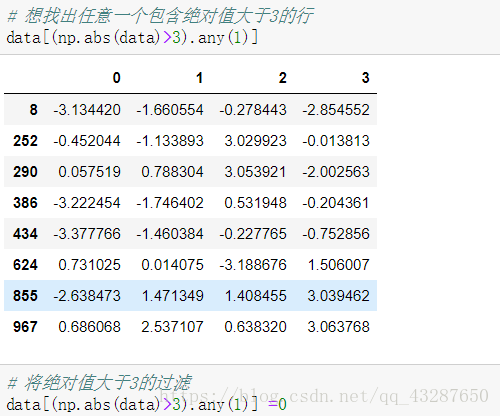
把包含绝对值大于3的行数据都过滤掉
看!最大值和最小值的绝对值都小于3了
这只是举了一个绝对值的例子,当然要结合其他的数组运算灵活使用哦~
四、 Pandas中的数据加载、存储与解析

1.读取
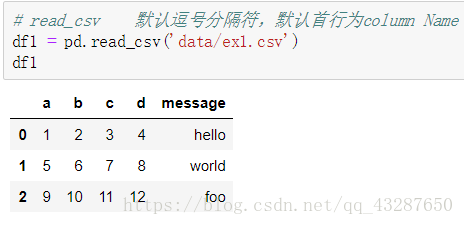
读写文本格式的文件 :read_csv()
(1)直接读取:默认分割符是‘,’,默认首行为列名
read_csv(‘文本名称’)
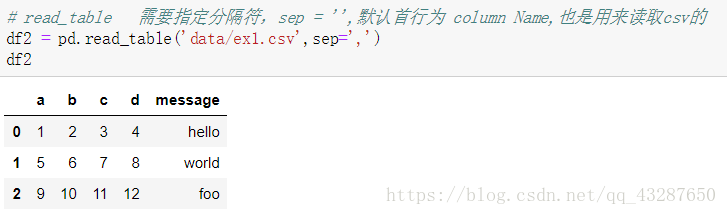
也可以用read_table进行读取,但是需要指定分隔符
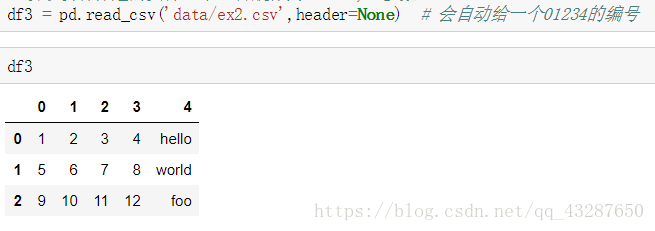
(2)读取没有列名的文件,加入参数header=None
(3)给没有列名的文件取个列名
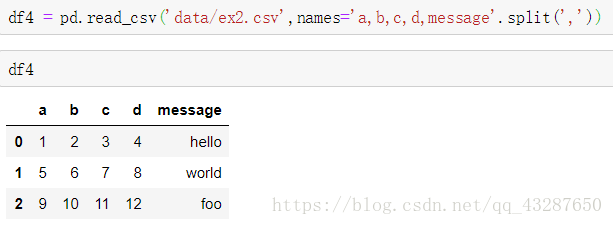
(4)给没有列名的文件取个列明,并将其中一个变为行索引
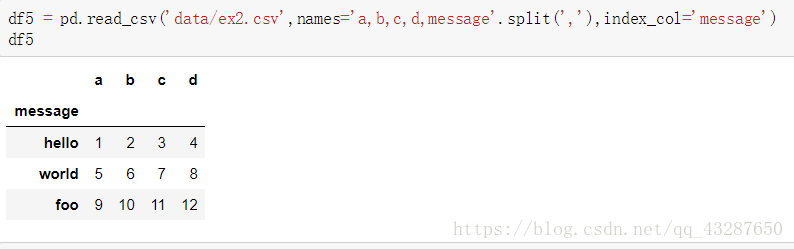
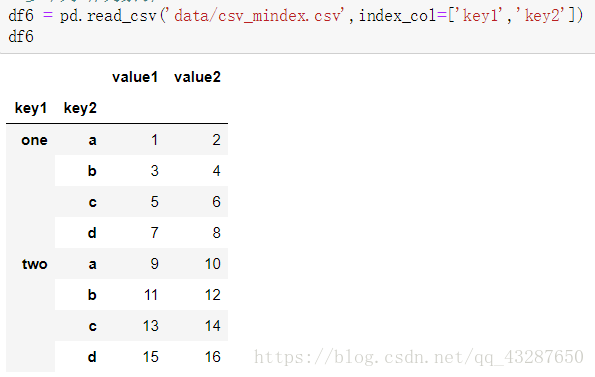
- 多个列作为行索引
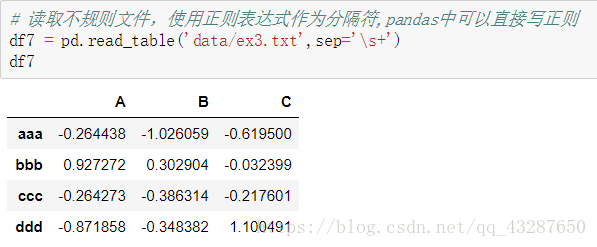
(5)读取不规则文件,使用正则表达式
这个文件是中间有很多空格
(6)跳行读取 ,skiprows参数
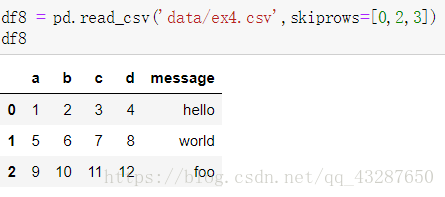
(7)读取有缺失值的文件,na_values = [‘null’]

2.写入csv
语法:xx.to_csv() ,默认逗号分割
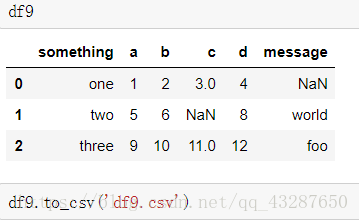
(1)直接保存数据
将df9 直接保存到csv文件里
预览一下保存的内容
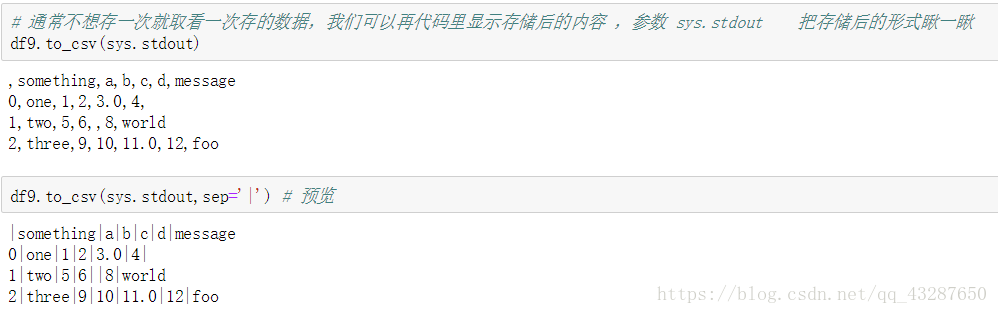
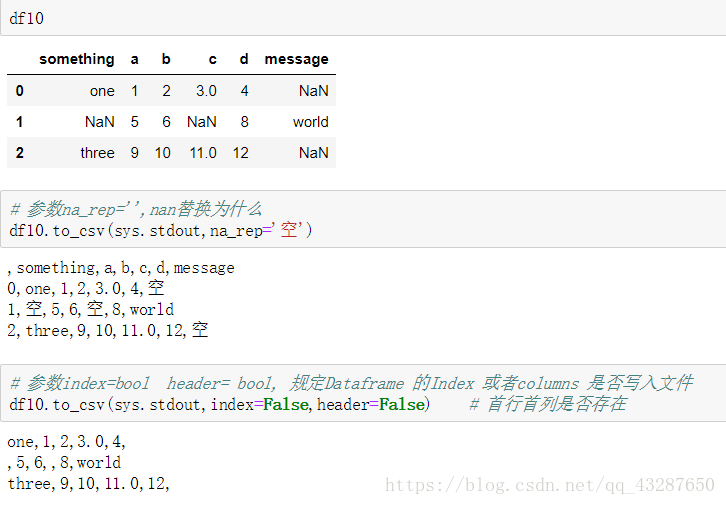
(2)to_csv()的一些参数
五、数据聚合与分组计算
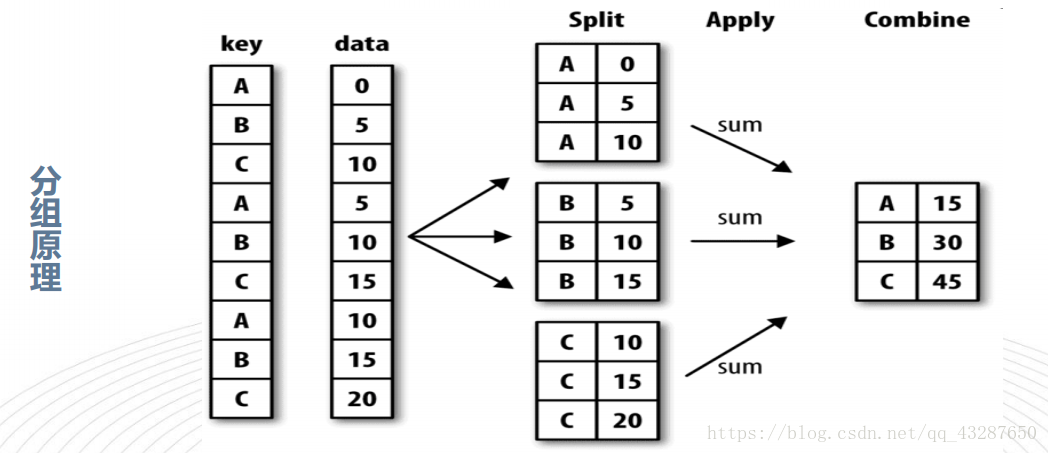
1.数据分组与聚合结合
(1)
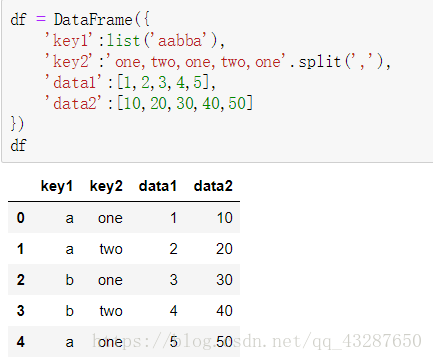
我们先看看这个具体是怎么操作的,先准备一个数据集
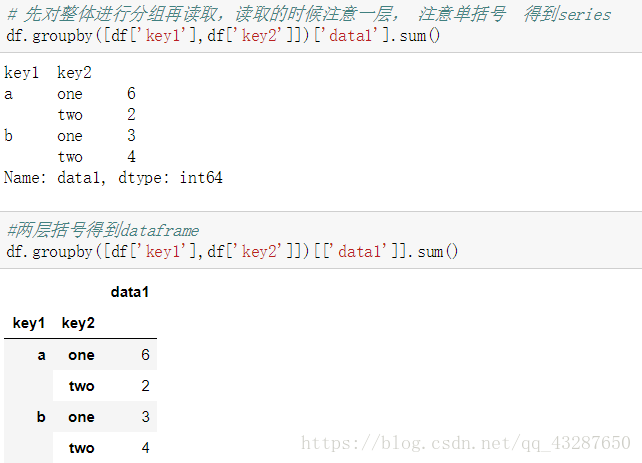
我们把data1的数据按照key1来进行分组,这一步是没有进行任何计算的,只有分组
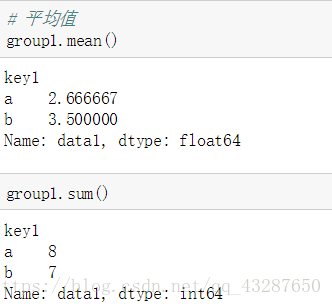
现在我们可以对它进行任何聚合运算了

(2)
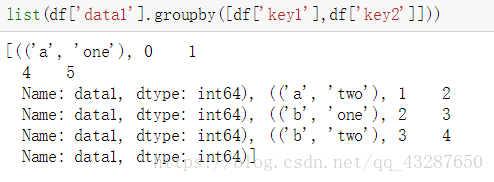
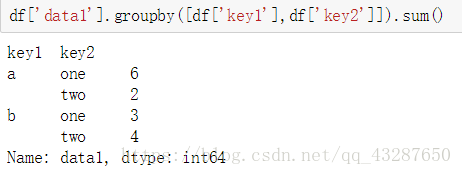
接下来,我们看看对多个条件进行分组是怎么样的,我们把data1按照key1和key2进行分组,得到了一个对象
转化为列表看看是个什么东西
a one 有两个值 在索引为0的位置的值是1;在索引为4的位置的值是5
a two 在索引为1的位置值是2
b one 在索引为2的位置值是3
b two 在索引为3的位置值是4

下面仍然对它进行聚合
(3)以上我们都是先读取再分组,再聚合。
当然我们也可以先分组再读取,再聚合
(4)对分组进行迭代
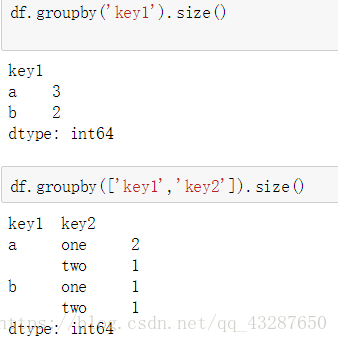
(5)size方法查看分组数据的数量
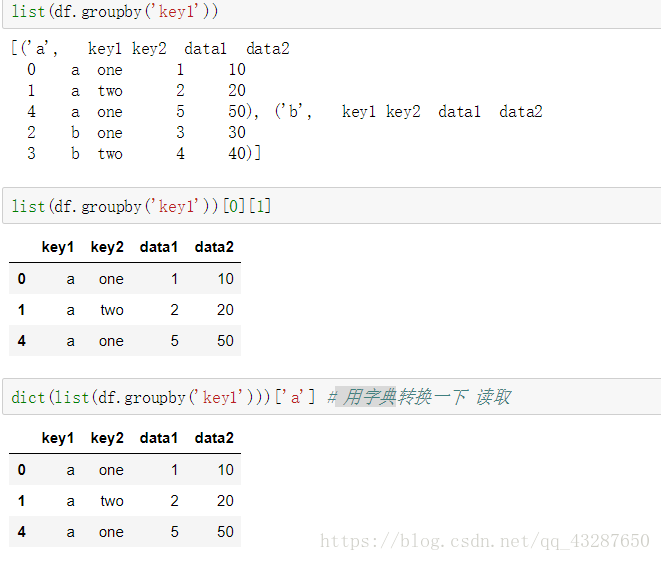
(6)读取分组后的数据
转换为列表或者字典进行读取
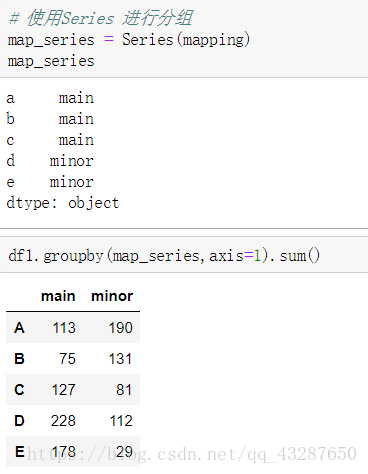
(7)通过字典或者series进行分组
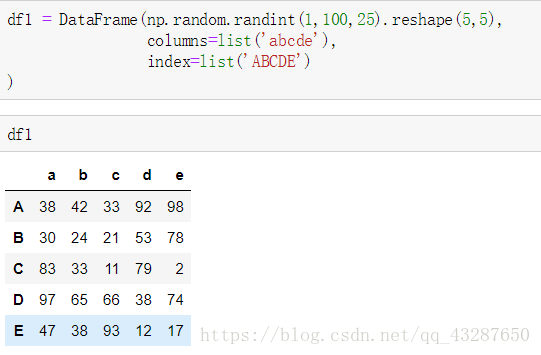
我们准备好一个数据集
①用字典进行分组
现在建一个字典,a,b,c一一对应,意思就是将abc分为一个组main,de分为1个组minor,再将之运用到df1中,按列索引进行分组。
②用series进行分组


2.数据聚合
(1)自带的聚合函数
求平均值:mean
求和:sum
求最大值:max
求最小值:min
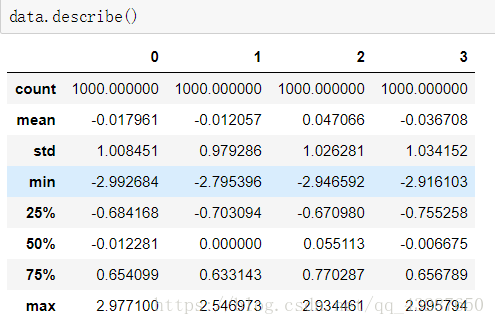
统计:describe
计数:count
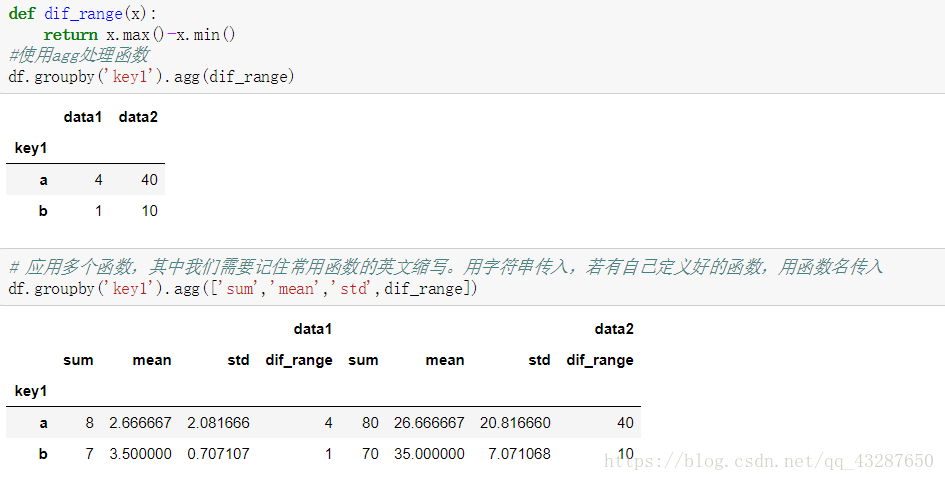
(2)自定义聚合函数
使用agg函数可以定义求哪些聚合
给列取个名字
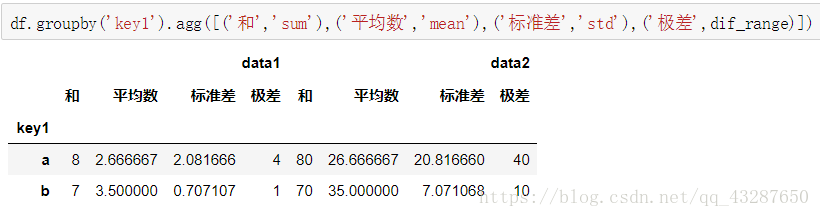
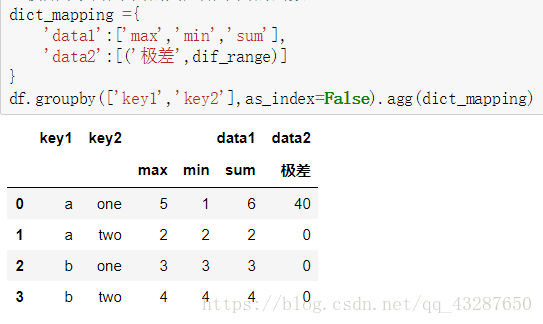
使用字典来给不同的列应用不同的函数
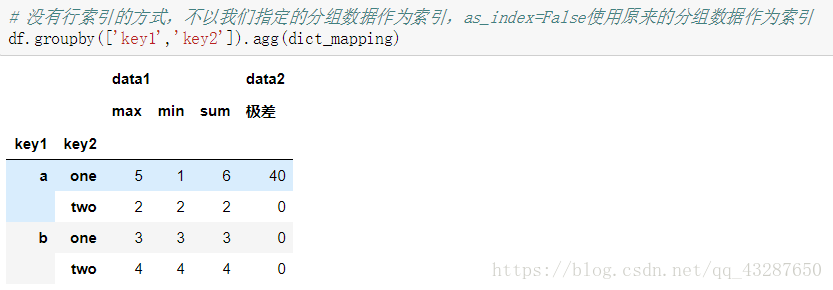
看看as_index=False有什么作用:
3.神奇的apply
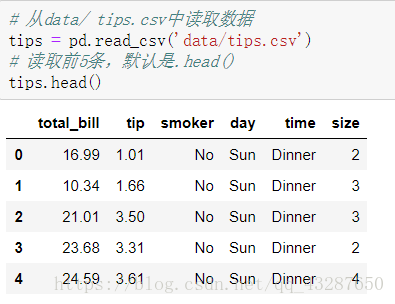
读取一个数据,看一下它的前5条,如果想看倒数几条的数据就用tail()
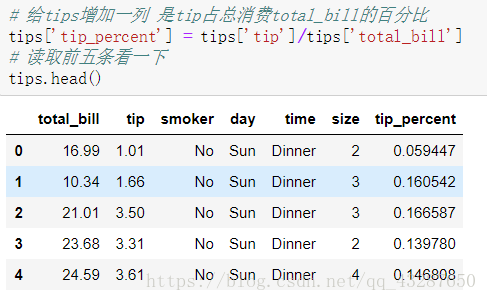
添加一列数据,消费百分比
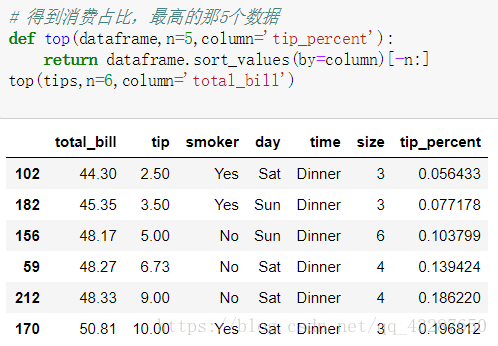
得到消费占比最高的6个数据
通过apply运用上面的函数,显示的都是默认的数据
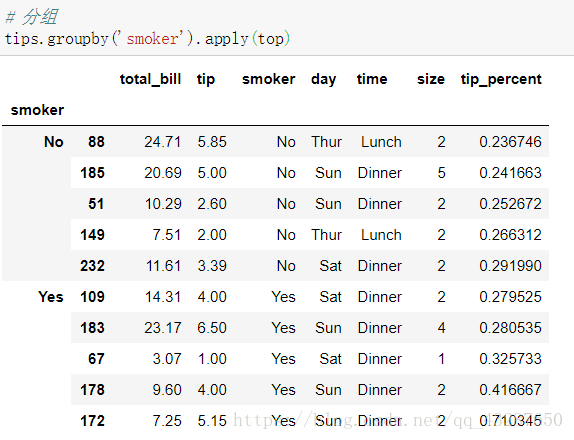
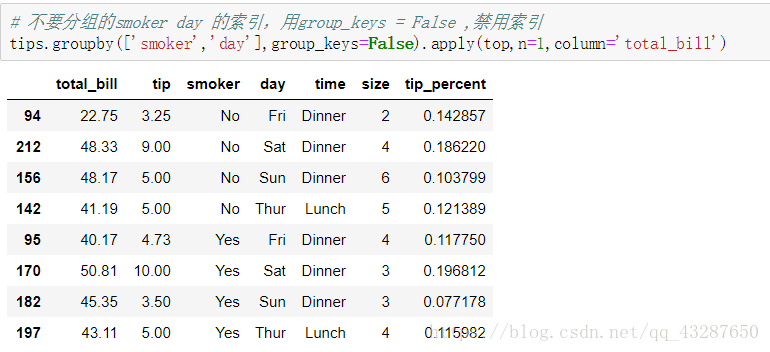
应用一些参数
4.分位数和桶分析
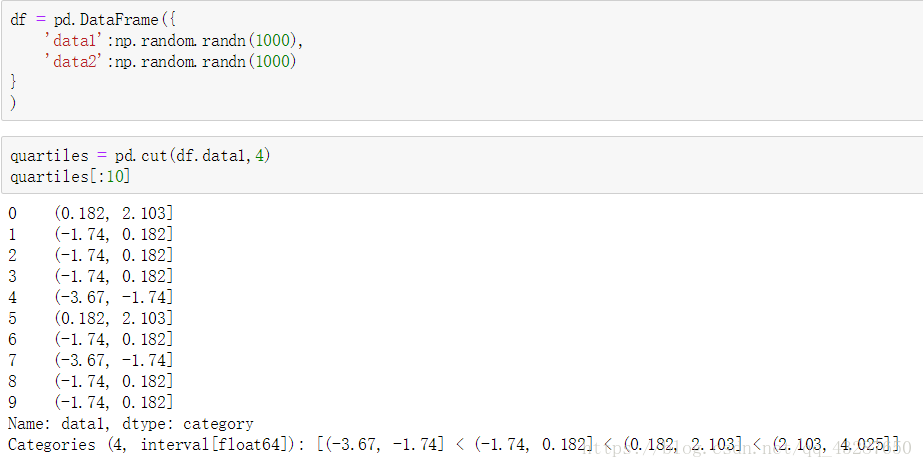
准备一个数据集,拆分为区间相等的4份
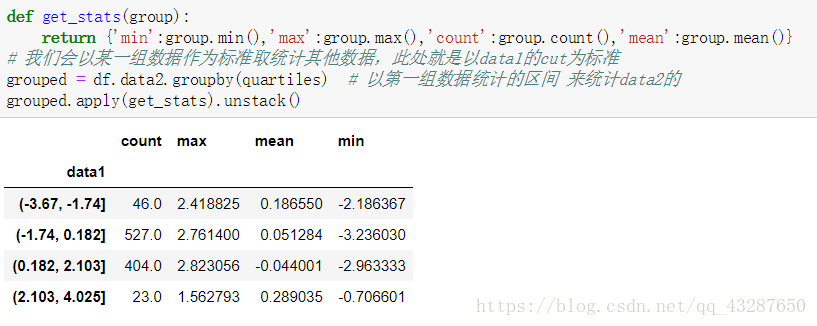
5.分组加权平均数
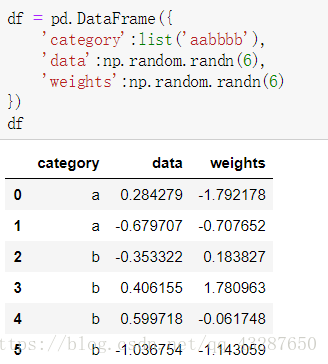
准备一个数据:
进行加权:
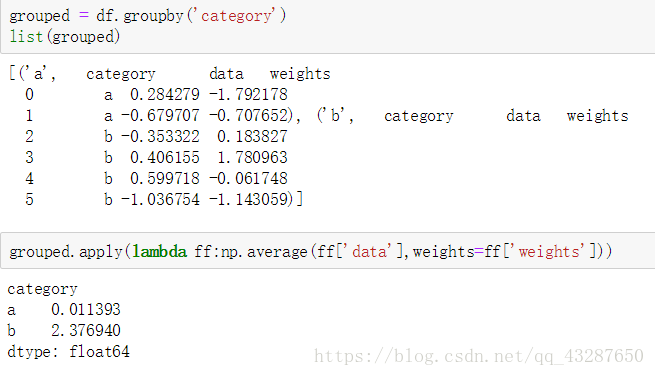
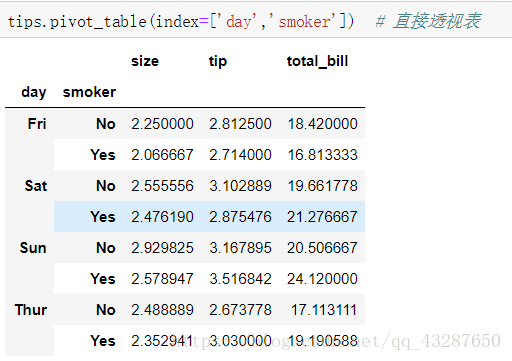
6.透视表
语法:xx.pivot_table()
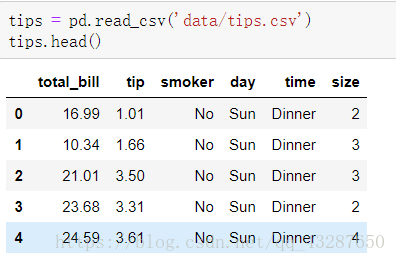
读取数据:
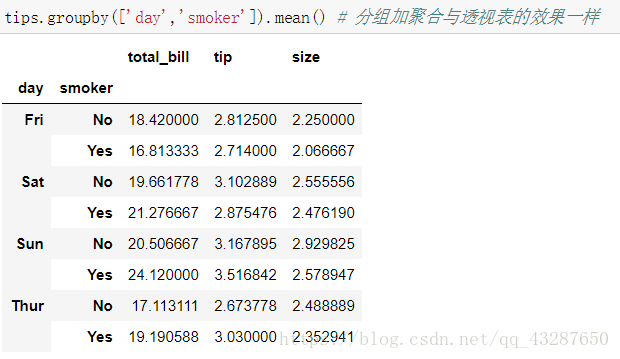
直接进行透视:
和上面效果一样,说明默认是mean
指定行和列索引
margins=True
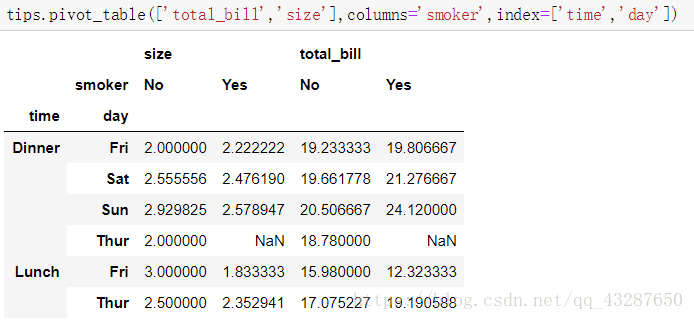

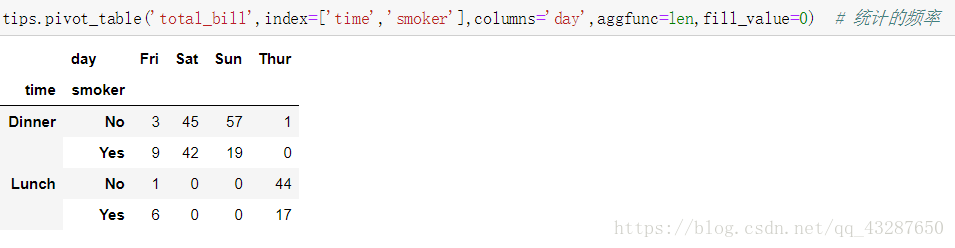
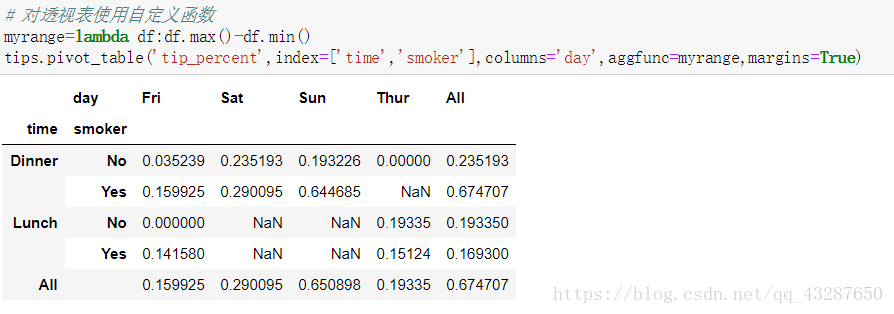
使用aggfunc参数