20172328 蓝墨云实验——三种查找算法练习
- 课程:《软件结构与数据结构》
- 班级: 1723
- 姓名: 李馨雨
- 学号:20172328
- 实验教师:王志强老师
- 实验日期:2018年10月19日
- 必修选修: 必修
一、实验要求学习内容
- 查找的关键:比较
- 用平均比较次数来评估算法的优劣,称为平均查找长度(ASL)
ASL = ∑ p(i)c(i)(i=1,2,3,…,n)- 其中P(i)为查找表中第i个数据元素的概率,C(i)为找到第i个数据元素时已经比较过的次数.
- 在查找表中查找不到待查元素,但是找到待查元素应该在表中存在的位置的平均查找次数称为查找不成功时的平均查找长度。
- 线性查找算法的ASL:如果每个关键字查找概率相同,则ASL = (n+1)/2;时间复杂度为O(n)
二分(折半)查找算法的ASL:如图所示,时间复杂度为O(log2(n))

- 分块(索引顺序)算法的ASL:因为分块查找是先折半查找再线性查找,故假设序列分成了n块,每块k个元素,那么ASL = LB + LA
那么ASL = (1+n)/2 + (1+k)/2 - 哈希表ASL:哈希表(Hash Table)也叫散列表,是依据关键码值(Key Value)而直接进行訪问的数据结构。它通过把关键码值映射到哈希表中的一个位置来访问记录,以加快查找的速度。这个映射函数就做散列函数。存放记录的数组叫做散列表。
- 查找技术一般基于待查关键字和数据项关键字的比较,基于关键字的比较,其时间复杂度为O(log2(n)~O(n),而哈希表查找可以直接通过关键字找到存储地址,使得查找时间可以是常数级。
哈希表存储的是键值对,其查找的时间复杂度与元素数量多少无关。哈希表在查找元素时是通过计算哈希码值来定位元素的位置从而直接訪问元素的,因此,哈希表查找的时间复杂度为O(1)。
哈希冲突的处理方法
1、开放定址法——线性探测法
线性探测法的地址增量di = 1, 2, ... , m-1,当中,i为探测次数。该方法一次探测下一个地址。知道有空的地址后插入。若整个空间都找不到空余的地址,则产生溢出。
线性探测法容易产生“冲突”现象。当表中的第i、i+1、i+2的位置上已经存储某些keyword,则下一次哈希地址为i、i+1、i+2、i+3的keyword都将企图填入到i+3的位置上,这样的多个哈希地址不同的keyword争夺同一个后继哈希地址的现象称为“冲突”。
2、开放地址法——二次探测法
二次探測法的地址增量序列为 di = 12, -12, 22。 -22,… 。 q2, -q2 (q <= m/2)。二次探測能有效避免“聚集”现象,可是不可以探測到哈希表上全部的存储单元,可是至少可以探測到一半。


3、链地址法——拉链法
其基本思路是:将全部具有同样哈希地址的而不同keyword的数据元素连接到同一个单链表中。假设选定的哈希表长度为m,则可将哈希表定义为一个有m个头指针组成的指针数组T[0..m-1]。凡是哈希地址为i的数据元素,均以节点的形式插入到T[i]为头指针的单链表中。而且新的元素插入到链表的前端,这不仅由于方便。还由于常常发生这种事实:新近插入的元素最优可能不久又被訪问。
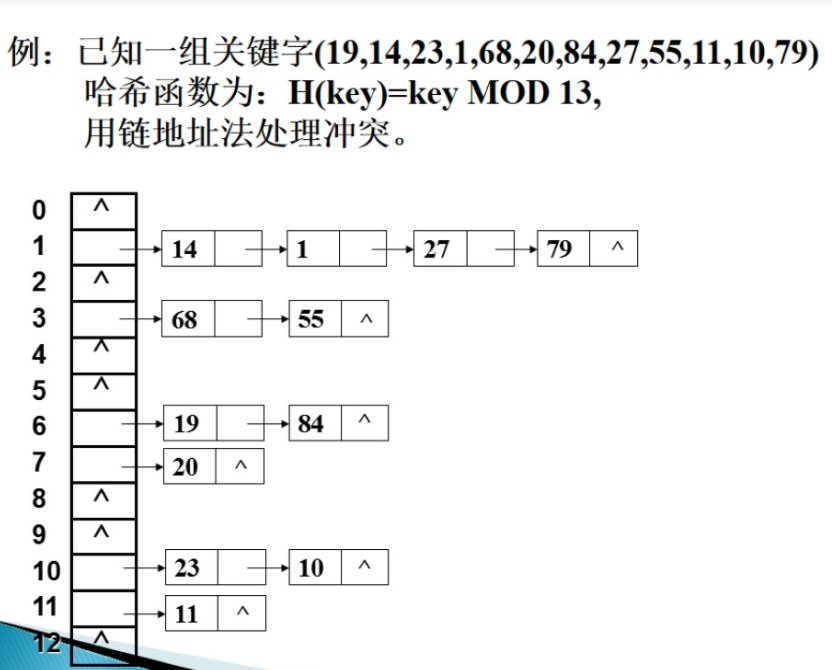
链地址法特点:
(1)拉链法处理冲突简单。且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
(2)因为拉链法中各链表上的结点空间是动态申请的。故它更适合于造表前无法确定表长的情况。
(3)开放定址法为降低冲突。要求装填因子α较小。故当结点规模较大时会浪费非常多空间。而拉链法中可取α≥1,且结点较大时,拉链法中添加的指针域可忽略不计,因此节省空间;
(4)在用拉链法构造的散列表中,删除结点的操作易于实现。仅仅要简单地删去链表上对应的结点就可以。而对开放地址法构造的散列表,删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是由于各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。
因此在用开放地址法处理冲突的散列表上运行删除操作。仅仅能在被删结点上做删除标记,而不能真正删除结点。
四、哈希表的装填因子α
装填因子(α) = (哈希表中的记录数) / (哈希表的长度)
装填因子是哈希表装满程度的标记因子。值越大。填入表中的数据元素越多,产生冲突的可能性越大。
二、实验题目及解答过程
给定关键字序列11,78,10,1,3,2,4,21,试分别用顺序查找、折半查找、散列查找(用线性探查法和链地址法)来实现查找。
请画出他们的对应存储形式(顺序查找的顺序表和两种散列查找的散列表),并求出每一种查找的成功平均查找长度。其中,散列表H(k)= k%11
课堂上做的答案如图所示:

需要改正的内容是线性探查法部分
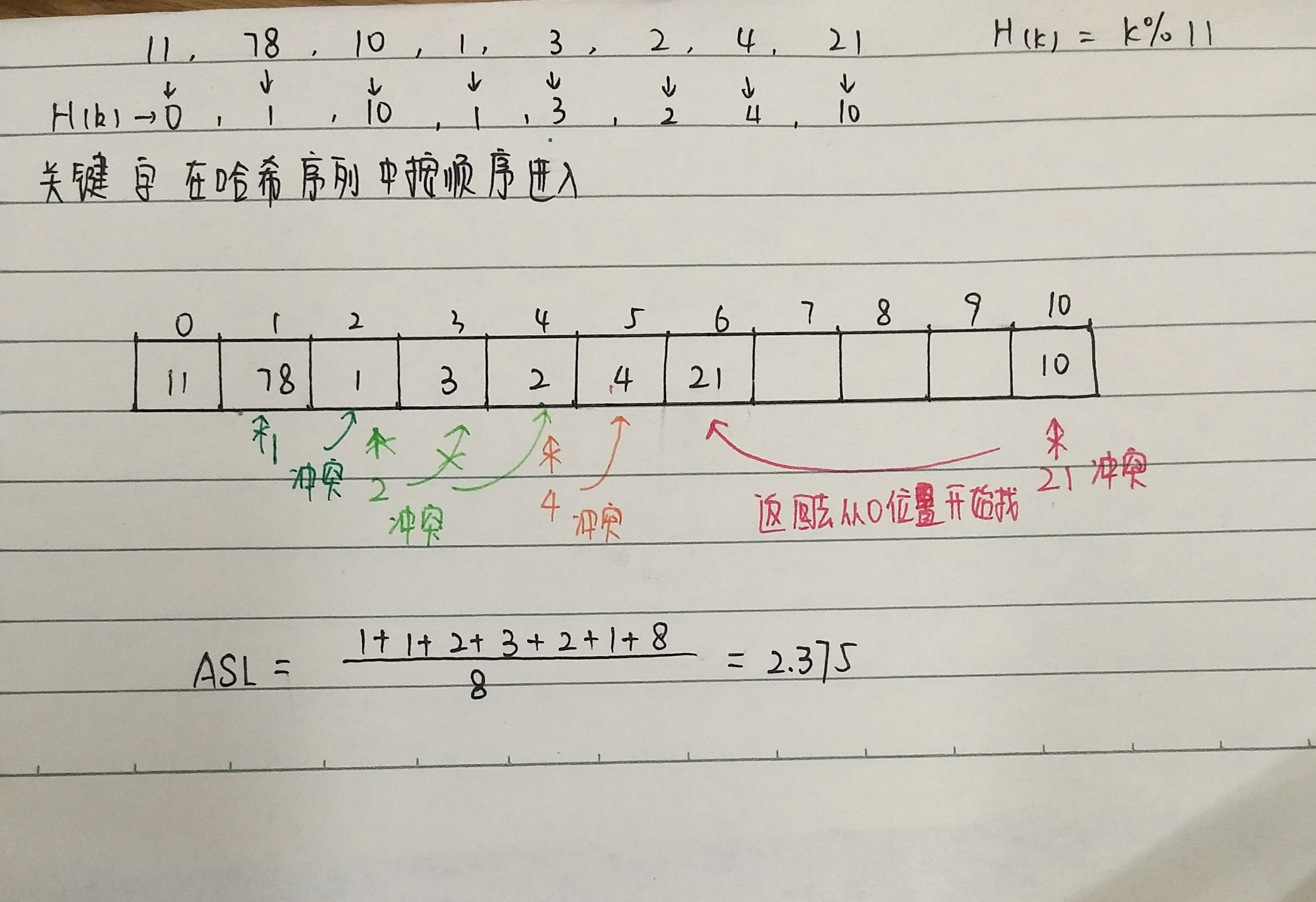
- 对于错误的理解:
关于这个问题,让我对Hash表查找有了更清楚的认识。
首先,我们是在记录的存储地址中查找的,是要在存储地址和关键字序列建立一个确定的对应关系,这样通过一次存取就能得到所查元素的查找方法。
其次,冲突也是有顺序的,当关键值序列一个一个往哈希序列中放的时候,冲突要一个一个解决,而不是把能重复的抛在一遍,最后填完了所有出现的H(k)再去解决冲突。
其他(感悟、思考等)
第一次写课堂错误改正博客,感觉有点开心???哈哈,希望是最后一次啦!不过认识的更加深刻啦,也算是好事呀!