(一)目的
熟悉基本的CUDA程序架构以及如何调用相应的API进行CUDA编程
(二)内容
完成矩阵相加的并行程序的实现(不用share memory实现)
要求:
- 实现2个矩阵(32*32)的相加,M矩阵的初始值全为2,N矩阵的初始值全为5。同时用CPU代码实现,比较两个代码的运行时间
- 实现2个矩阵(1024*1024)的相加,M矩阵的初始值全为2,N矩阵的初始值全为5。同时用CPU代码实现,比较两个代码的运行时间
- 实现2个矩阵(5000*5000)的相加,M矩阵的初始值全为2,N矩阵的初始值全为5。同时用CPU代码实现,比较两个代码的运行时间
实验步骤一 软件设计分析:
一.数据类型:
根据实验任务,M矩阵的初始值为2,N矩阵的初始值为5,相加后得到的矩阵应该为值全为7的矩阵。因此,把实验的数据类型定义为short int类型比较合适。
二.对于方阵的存储,一共有2种方式:
矩阵在内存中的存储按照行列先后可以分为两种方式,一种是行优先的存储方式,一种是列优先的方式。
这两种存储方式是在访问对应位置的数据的时候有很大的差别。在CULA内部,矩阵默认是按列优先存放的,如果要使用CULA device 函数,就必须考虑存储方式的问题,有的时候可能需要我们对存储方式进行转换。但是无论哪种存储方式,最终在内存中是顺序存储的。
三.GPU程序的block和threads的相关设置:
我们cuda实验平台的每一个Grid可以按照一维或者二维的方式组织,每一个Block可以按照一维,二维或者三维的方式进行存储,每一个block最多只能有1536个线程。对于上面三个任务GPU程序的block和threads的设置是不一样的。
(1)第一个任务,实现2个矩阵(32*32)的相加的时候,需要32*32=1024(<1536)个线程,这时的block和threads的设置为:
DimGrid(1,1),DimBlock(32,32);
即Grid里面的Block是按照1x1的方式组织,每一个Block里面的线程按照32x32组织。
(2)第二个任务,实现2个矩阵(1024*1024)的相加的时候一个Block肯定是不够的,这时候我的的block和threads的设置为:
DimGrid(32,32),DimBlock(32,32);
即Grid里面的Block是按照32x32的方式组织,每一个Block里面的线程按照32x32组织。
(3)第三个任务,实现2个矩阵(5000*5000)的相加的时候我的的block和threads的设置为:
DimGrid(157,157),DimBlock(32,32);
即Grid里面的Block是按照157x157的方式组织,每一个Block里面的线程按照32x32组织。
实验步骤二 实验设备:
本地设备:PC机+Windows10操作系统
Putty远程连接工具
远程设备:NVIDIA-SMI 352.79
Driver Version: 352.79
实验步骤三 CPU计算代码:
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
const int DIM = 5000;
short int M[DIM][DIM];
short int N[DIM][DIM];
short int C[DIM][DIM];
void main()
{
clock_t start, end;
//生成M矩阵
for (int i = 0; i < DIM; i++)
for (int j = 0; j < DIM; j++)
M[i][j] = 2;
//生成N矩阵
for (int i = 0; i < DIM; i++)
for (int j = 0; j < DIM; j++)
N[i][j] = 5;
//求矩阵的和
start = clock();//计时开始
for (int i = 0; i < DIM; i++)
for (int j = 0; j < DIM; j++)
C[i][j] = M[i][j] + N[i][j];
end = clock();//计时结束
//打印结果
printf("矩阵M+矩阵N\n");
for (int i = 0; i < DIM; i++)
{
for (int j = 0; j < DIM; j++)
{
printf("%d ", C[i][j]);
}
printf("\n");
}
float time1 = (float)(end - start) / CLOCKS_PER_SEC;
printf("执行时间为:%f\n", time1);
system("pause");
}
实验步骤四 GPU计算代码:
#include<cuda_runtime_api.h>
#include<device_launch_parameters.h>
#include<stdio.h>
#include<time.h>
static const int M = 32;
static const int N = 32;
__global__ void add(int a[M][N], int b[M][N], int c[M][N])
{
int i = threadIdx.x + blockIdx.x * blockDim.x;
int j = threadIdx.y + blockIdx.y * blockDim.y;
if (i < M && j < N)
{
c[i][j] = a[i][j] + b[i][j];
}
}
int main()
{
clock_t start,end;
int (*a_h)[N] = new int[M][N];
int (*b_h)[N] = new int[M][N];
int (*c_h)[N] = new int[M][N];
for(int i = 0;i < M;i++)
for(int j = 0;j < N;j++)
a_h[i][j] = 2;
for(int i = 0;i < M;i++)
for(int j = 0;j < N;j++)
b_h[i][j] = 5;
int (*a_d)[N];
int (*b_d)[N];
int (*c_d)[N];
cudaMalloc((void **)&a_d, sizeof(int)* M*N);
cudaMalloc((void **)&b_d, sizeof(int)* M*N);
cudaMalloc((void **)&c_d, sizeof(int)* M*N);
start=clock();//开始计时
cudaMemcpy(a_d, a_h, sizeof(int)* M*N, cudaMemcpyHostToDevice);
cudaMemcpy(b_d, b_h, sizeof(int)* M*N, cudaMemcpyHostToDevice);
dim3 DimGrid(1, 1);
dim3 DimBlock(32, 32);
add <<<DimGrid, DimBlock>>>(a_d, b_d, c_d);
cudaMemcpy(c_h, c_d, sizeof(int)* M*N, cudaMemcpyDeviceToHost);
end=clock();//计时结束
for (int i = 0; i < M; i++)
{
for (int j = 0; j < N; j++)
printf("%10d", c_h[i][j]);
printf("\n");
}
float time1=(float)(end-start)/CLOCKS_PER_SEC;
printf("执行时间为:%f\n",time1);
return 0;
}
实验步骤五 观察输出结果:
- 第一个任务,实现2个矩阵(32*32)的相加的时候:
- CPU输出结果:
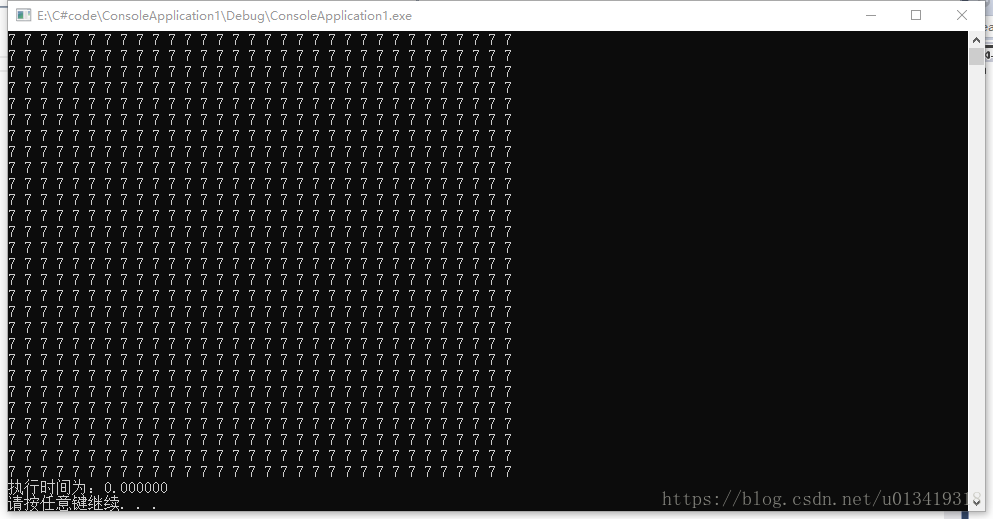
-
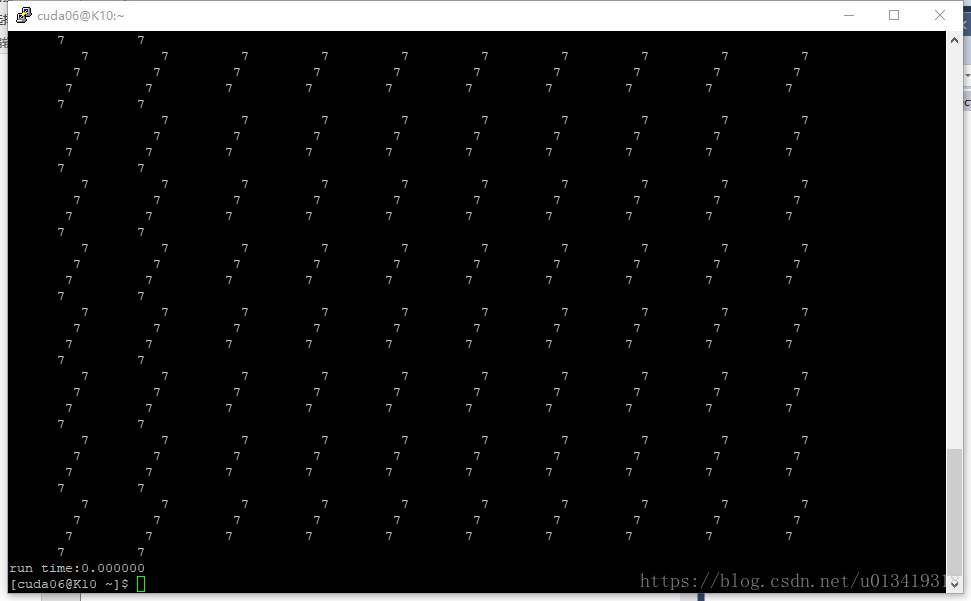
- GPU输出结果:
- 第二个任务,实现2个矩阵(1024*1024)的相加的时候:
- CPU输出结果:
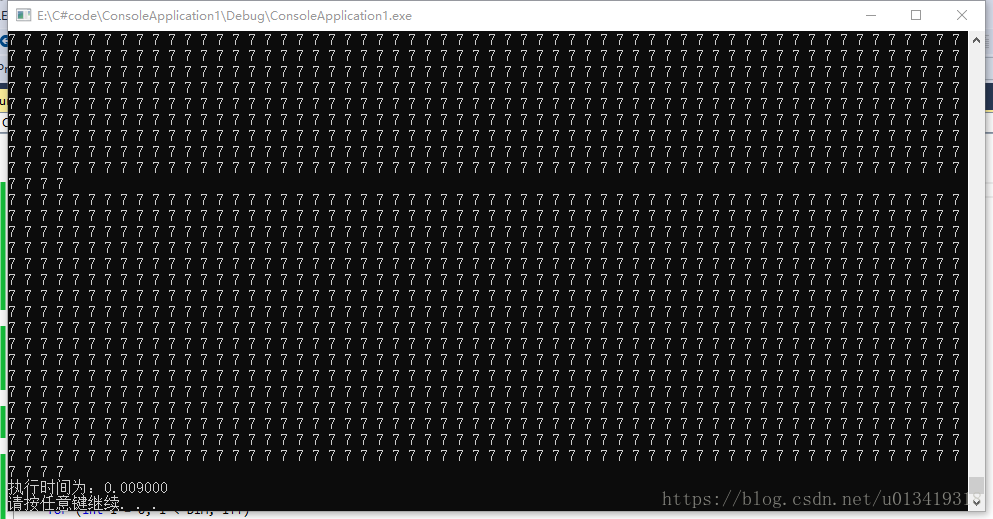
-
- GPU输出结果:

- 第三个任务,实现2个矩阵(5000*5000)的相加的时候:
- CPU输出结果:
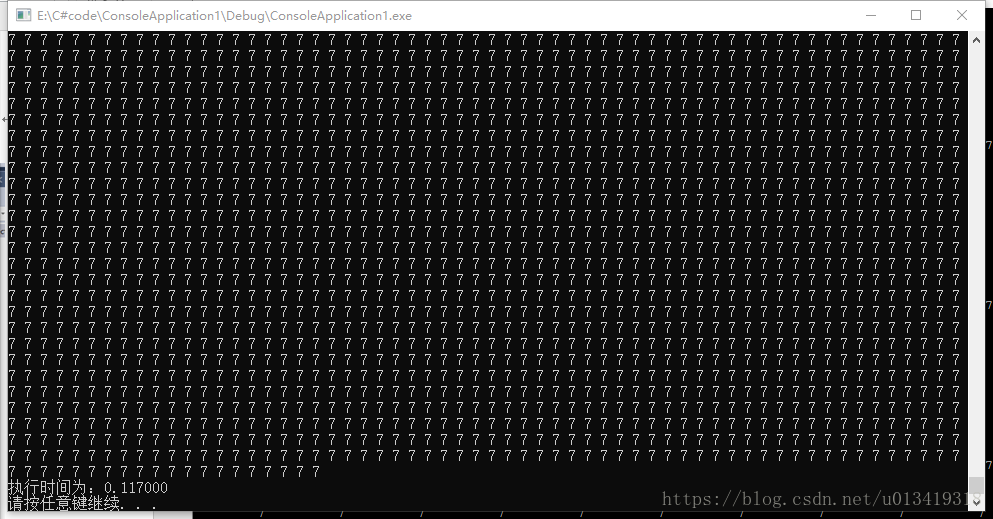
-
- GPU输出结果:

实验结论:
cpu程序计算所需时间:
第一个任务, cpu程序计算所需时间:0.000000s
第二个任务, cpu程序计算所需时间:0.009000s
第三个任务, cpu程序计算所需时间:0.117000s
gpu程序计算所需时间:
第一个任务, gpu程序计算所需时间: 0.000000s
第二个任务, gpu程序计算所需时间:0.0100000s
第三个任务, gpu程序计算所需时间:0.1600000s
总结:并行计算是一种以空间换时间的方式来提高数据的运行效率。按照实验预期,计算相同时间复杂度的程序,GPU在时间效率上应该优于CPU,但是由我们的实验来看,三个任务中,GPU都没有在时间效率上超过CPU,本人认为主要的原因是我在编写程序的时候把host端与device端之间的数据传输所花费的时间也计算在内,而在数据的传输还受到网络延迟的影响。这使得计算较小数据量的时候,GPU体现不出明显的优势,而在大数据量并行计算的时候,GPU将会大大节省我们的计算时间。