参考链接:Java基础——集合源码解析 List List 接口
加入部分自己的见解,并做了若干调整
UML图:
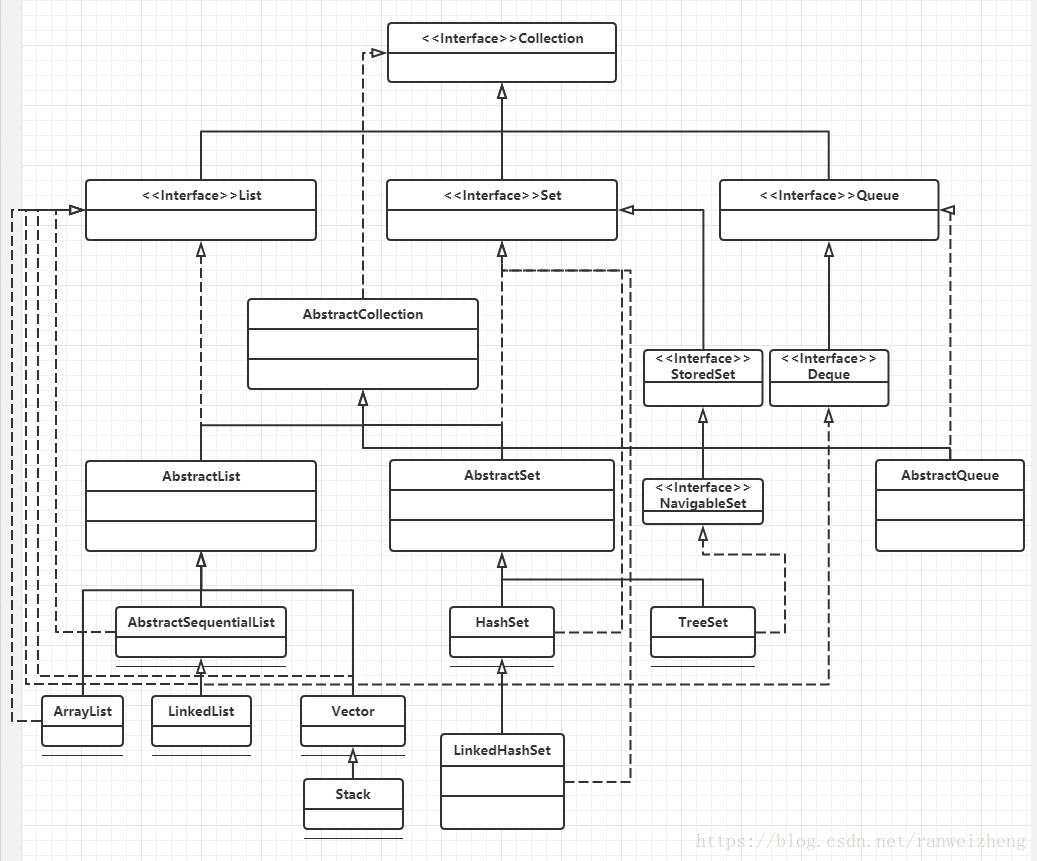
List 是一个接口,定义了一组元素是有序的、可重复的集合。
List 继承自 Collection,较之 Collection,List 还添加了以下操作方法
- 位置相关:List 的元素是有序的,因此有get(index)、set(index,object)、add(index,object)、remove(index) 方法。
- 搜索:indexOf(),lastIndexOf();
- 迭代:使用 Iterator 的功能板迭代器
- 范围性操作:使用 subList 方法对 list 进行任意范围操作。
List的抽象实现类 AbstractList
AbstractList 继承自 AbstractCollection 类,实现了 List 接口。整个类的设计类似于AbstractCollection,实现了大多数方法,抽象了对于需要根据数据操作的方法。
List 的实现类
ArrayList
ArrayList 是我们最常用的一个类,它具有如下特点:
- 容量不固定,可以动态扩容
- 有序(基于数组的实现,当然有序~~)
- 元素可以为 null
- 效率高
- 查找操作的时间复杂度是 O(1)
- 增删操作的时间复杂度是 O(n)
- 其他操作基本也都是 O(n)
- 占用空间少,相比 LinkedList,不用占用额外空间维护表结构
从成员变量,我们可以得知
- Object[] elementData:数据结构---数组
- 两个默认空数组,仅在构造方法中使用,不关心 注:jdk1.7中 ,没有找到DEFAULTCAPACITY_EMPTY_ELEMENTDATA
- DEFAULT_CAPACITY: 数组初始容量为10
- size:当前元素个数
- MAX_ARRAY_SIZE:数组最大容量 指定为 Integer.MAX_VALUE - 8,但是实际最大容量可能大于这个值,具体可以参考hugeCapacity()方法
现在我们知道了 ArrayList 其实就是基于数组的实现。因此,增删改查操作就变得很容易理解了。
- get(index)直接获取数组的底 index 个元素
- set(index,object)直接修改数组的第 index 个元素的引用
- add(index,object)添加一个元素到index,这里会牵涉到数组的扩容,扩容我们后面再单独看
这里的操作很简单,比如说含有8个元素的数组array,要在第五个位置插入一个元素x,则将第[5,8)角标的元素分别往后移动一位变成[6,9),此时角标为5的位置空出来,使 array[5] = x 即可。
移动时,使用了System.arraycopy(elementData, index, elementData, index + 1, size - index);
- remove(object)删除一个元素,删除的过程同添加元素。
现在我们来看看扩容机制,假设我们现在有一个集合 list,里面正好含有10个元素,此时,我们调用 add(object)方法添加一个元素,看看是怎样执行扩容操作的。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
//将原文中的代码换为1.7中的代码,更容易理解
|
从上面我们可以看到,修改某个角标的值或者查找某个角标的值时,我们可以直接调用数组的操作,效率很高。但是添加和删除则是要操作整个数组的移动,效率稍低。
这里我们也可以看到,其实 ArrayList 就是一个针对数组操作的封装类。
LinkedList
刚刚我们看了 ArrayList,ArrayList 的增删操作效率相对较低。因此,Java 给我们设计了另外一种增删效率比较高的集合 LinkedList。
LinkedList 继承自 AbstractSequentialList。
AbstractSequentialList 又继承自AbstractList,并且基于 iterator 实现了默认增删改查操作。
再回过头来看 LinkedList,LinkedList 还实现了Deque(双向队列)接口,双向队列后面我们会单独去学习,这里不再做过多的赘述。
再来看看成员变量~~
- size 链表元素个数
- first 第一个元素
- last 最后一个元素
getFirst(),getLast为LinkedList自有的public方法,为null时会抛出 java.util.NoSuchElementException
* get(index)方法很有意思,先要判断index是否为合法范围(大于零且小于size),然后判断index是否大于size的一半,如果小于则从first找起,否则,从list找起。
特点:和 ArrayList 的优缺点互补。
链表的实现,链表的实现很简单,就是最基本的链表数据结构。理解链表数据结构可以跳过这里了。
我举个例子吧,现在要让 a、b、c、d 四个同学按顺序投篮。有两种方法,第一种是 abcd 排成一个队伍,依次去投篮;但是体育课上让所有的同学等着投篮很浪费时间,因此有了第二种办法:依次告诉 a‘你投了蓝之后叫 b 来投篮’,告诉 b‘你投了蓝之后叫 c 来投篮’以此类推。
这样,就形成了一个简单的单向列表,abcd 按照顺序依次去投篮。此时,x 同学由于身体不舒服需要提前投篮回教室休息,则老师只需要告诉 a 同学投完篮之后不用叫 b 同学了,改叫 x 同学,x 同学投完篮之后叫 b 同学即可。
不多说了,新手听不懂,老手用不上。不懂链表的同学好好去学学数据结构吧。
后面的增删改查操作就只是基础的遍历链表操作,就不去一一去读源码了,链表操作记不太清楚的同学可以去看一下 LinkedList 的源码。
Vector
在学习了 ArrayList 之后,Vector 这个类我想用”线程安全的 ArrayList“可以一句话概括了。
/*
Vector是Java早期提供的线程安全的动态数组,如果不需要线程安全,则不建议选择,毕竟通不是有额外开销的。
与ArrayList的另一个区别是,扩容时,Vector是增长一倍,而ArrayList是50%
最好可以对比 java.util.concurrent.CopyOnWriteArrayList。
*/
Vector 和 ArrayList 一样都继承自 AbstractList,为什么说”Vector 是线程安全的 ArrayList“,本来还准备列个表让大家对比一下成员变量以及主要操作方法的实现。but,除了 Vector 的方法上多了个 synchronized 外,代码都是一样的,比较个毛。因此,如果需要考虑线程安全,直接使用 Vector 即可,但是因为所有方法都加了synchronized ,效率相对会比较低,如果没有线程安全的需求,那就使用 ArrayList 呗。
最后,还是说一下Vector 和 ArrayList的区别吧,反正也没什么卵用,大家看看就好
- Vector 出生早,JDK1.0的时候出生的,ArrayList 是1.2才出生
- Vector 是线程安全的,ArrayList 不是。(这是最大的特点了)
- Vector 默认扩容2倍,ArrayList 是1.5倍。这个~~有意义吗?
- Vector 多了一种迭代器 Enumeration。好吧,反正我没用过。
Enumeration
为了找到 Enumeration 这种迭代器有什么特点,我去翻了一下 Vector 的代码,找到了一个这样的方法和这样的接口,你们感受一下。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
mmp,这个 Enumeration 和Iterator 接口除了名字不一样,还有什么区别?然后仔细看了一遍,在elements()方法里面的匿名内部了里面找到了nextElement()方法里面有个同步代码块。好吧, Enumeration 大概是线程安全的Iterator?
Stack
Stack 继承自Vector,也是一个线程安全的集合。
Stack 也是基于数组实现的。
Stack 实现的是栈结构集合
什么是栈结构?
数据结构中,栈也是一种线性的数据结构,遵守 LIFO(后进先出)的操作顺序,这里用一张很污的图,保证你们看了之后能熟记栈结构特征。
小时候肯定都玩过羽毛球吧,羽毛球不经打,要经常换球,于是我买了一盒羽毛球,如下图,就是一个羽毛球盒子,最先放进去的羽毛球(栈底的),要最后才能取出来。
Stack 的 代码实现
类结构图如下,代码量也不多,一共才30几行
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
|
整个类的实现非常简单,就是继承 Vector,然后添加了 peek、pop、push、search 等方法,然后然添加删除都在最末尾的元素做操作即可。
思考:怎样用链表的结构快速实现 LinkedListStack?
/*
LinkedListStack(){
super();
}
pop() {
return removeLast();
}
push(E){
return addLast(E);
}
peek(){
return getLast();
}
*/
关于线程安全
ArrayList和LinkedList都不是线程安全的(有些文章中提到,linkedList中使用了synchronized来保证线程安全,但是在jdk1.7的代码中并没有。杨晓峰在极客时间的专栏中《第8讲对比Vector、ArrayList、LinkedList有何区别?》中,也提及“它也不是线程安全的”)
jdk的源码注释中有涉及:
<strong>Note that this implementation is not synchronized.</strong>
If multiple threads access a linked list concurrently, and at least
one of the threads modifies the list structurally, it <i>must</i> be
synchronized externally. (A structural modification is any operation
that adds or deletes one or more elements; merely setting the value of
an element is not a structural modification.) This is typically
accomplished by synchronizing on some object that naturally
encapsulates the list.
Vector以及它的子类Stack是线程安全的。
如果需要线程安全的使用List
1.使用Collections工具类中提供的Synchronized方法:
List list = Collections.synchronizedList(List<T> list);
可以考虑使用java.util.CopyOnWriteArrayList (不太熟悉,后面需要进一步了解。)