版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/fengzheku/article/details/50420745
一、 交互模式:
show tables; #查看所有表名
set 命令 #设置变量与查看变量;
set -v #查看所有的变量
set hive.stats.atomic #查看hive.stats.atomic变量
set hive.stats.atomic=false #设置hive.stats.atomic变量
dfs -ls #查看hadoop所有文件路径
dfs -ls /user/hive/warehouse/ #查看hive所有文件
dfs -ls /user/hive/warehouse/ptest #查看ptest文件
source file <filepath> #在client里执行一个hive脚本文件
quit #退出交互式shell
exit #退出交互式shell
reset #重置配置为默认值
!ls #从Hive shell执行一个shell命令
二、插入导出数据
1、向表中插入数据:
1)如果是分区表,并且分区目录不存在的话,此命令会先创建分区目录,然后将数据拷贝到改路下:
load data local inpath '/data1/testdata' overwrite into table test01 partition (country = 'US', state = 'CA');
2)如果目标表是非分区表,就不需要partition了:
load data local inpath '/data1/testdata' overwrite into table test01;
关键字:LOCAL,使用LOCAL的话,路径是本地文件系统路径,数据将会拷贝到目标位置。如果省略掉LOCAL,路径就是分布式文件系统中的路径
关键字:OVERWRITE,如果使用此关键字,那么目标文件夹之前存在的数据将会被先删除掉,如果没有这个关键字,则仅仅会把新增的文件增加到目标文件中,而不会删除之前的数据。
2、通过查询语句向表中插入数据
1)静态分区插入
INSERT OVERWRITE TABLE test02 PARTITION(country = 'US', state = 'OR') SELECT * FROM test01 t WHERE t.country = 'US' AND t.state = 'OR';
2)动态分区插入:
INSERT OVERWRITE TABLE test02 PARTITION(country ,state) SELECT t.name,t.age,t.country,t.state FROM test01 t;
Hive 根据select语句中的最后2列来确定分区字段country和state的值,是根据位置而不是根据字段的名字相同来区分不同分区的。
3)混合使用静态分区和动态分区:
I NSERT OVERWRITE TABLE test02 PARTITION(country = 'US', state) SELECT t.name,t.age,t.country,t.state FROM test01 t WHERE t.country = 'US';
静态分区必须出现在动态分区键之前
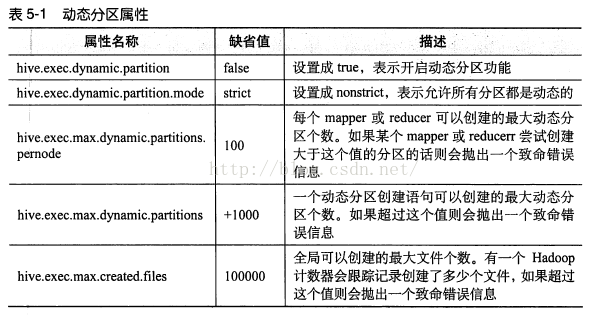
使用动态分区需要设置一些属性:
set hive.exec.dynamic.partition=true; #设置成true,表示开启动态分区
set hive.exec.dynamic.partition.mode=nonstrict;#设置成nonstrict,表示允许所有分区都是动态的,若是设置成strict,则至少有一个是静态分区
set hive.exec..max.dynamic.partitions.pernode=1000;#每个mapper或reducer可以创建的最大动态分区个数。
CREATE TABLE test4 AS SELECT * FROM test1;
4、导出数据
1)直接从表所在的位置导出:
hadoop fs -cp /user/hive/warehouse/test01 /data1/test
2) 使用INSERT ...DIRECTORY...:
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/test' SELECT * FROM test;