SYN Cookie的原理和实现
2014年01月06日 16:56:15 zhangskd 阅读数:28214 标签: TCPIPlinux内核 更多
所属专栏: TCP协议优化
版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/zhangskd/article/details/16986931
本文主要内容:SYN Cookie的原理,以及它的内核实现。
内核版本:3.6
Author:zhangskd @ csdn blog
SYN Flood
下面这段介绍引用自[1].
SYN Flood是一种非常危险而常见的Dos攻击方式。到目前为止,能够有效防范SYN Flood攻击的手段并不多,

SYN Cookie就是其中最著名的一种。
SYN Flood攻击是一种典型的拒绝服务(Denial of Service)攻击。所谓的拒绝服务攻击就是通过进行攻击,使受害主机或
网络不能提供良好的服务,从而间接达到攻击的目的。
SYN Flood攻击利用的是IPv4中TCP协议的三次握手(Three-Way Handshake)过程进行的攻击。
TCP服务器收到TCP SYN request包时,在发送TCP SYN + ACK包回客户机前,TCP服务器要先分配好一个数据区专门
服务于这个即将形成的TCP连接。一般把收到SYN包而还未收到ACK包时的连接状态称为半打开连接(Half-open Connection)。
在最常见的SYN Flood攻击中,攻击者在短时间内发送大量的TCP SYN包给受害者。受害者(服务器)为每个TCP SYN包分配
一个特定的数据区,只要这些SYN包具有不同的源地址(攻击者很容易伪造)。这将给TCP服务器造成很大的系统负担,最终
导致系统不能正常工作。
SYN Cookie
SYN Cookie原理由D.J. Bernstain和Eric Schenk提出。
SYN Cookie是对TCP服务器端的三次握手做一些修改,专门用来防范SYN Flood攻击的一种手段。它的原理是,在TCP服务器
接收到TCP SYN包并返回TCP SYN + ACK包时,不分配一个专门的数据区,而是根据这个SYN包计算出一个cookie值。这个
cookie作为将要返回的SYN ACK包的初始序列号。当客户端返回一个ACK包时,根据包头信息计算cookie,与返回的确认序列
号(初始序列号 + 1)进行对比,如果相同,则是一个正常连接,然后,分配资源,建立连接。
实现的关键在于cookie的计算,cookie的计算应该包含本次连接的状态信息,使攻击者不能伪造。
cookie的计算:
服务器收到一个SYN包,计算一个消息摘要mac。
mac = MAC(A, k);
MAC是密码学中的一个消息认证码函数,也就是满足某种安全性质的带密钥的hash函数,它能够提供cookie计算中需要的安全性。
在Linux实现中,MAC函数为SHA1。
A = SOURCE_IP || SOURCE_PORT || DST_IP || DST_PORT || t || MSSIND
k为服务器独有的密钥,实际上是一组随机数。
t为系统启动时间,每60秒加1。
MSSIND为MSS对应的索引。
实现
(1)启用条件
判断是否使用SYN Cookie。如果SYN Cookie功能有编译进内核(CONFIG_SYN_COOKIE),且选项
tcp_syncookies不为0,那么可使用SYN Cookie。同时设置SYN Flood标志(listen_opt->synflood_warned)。
-
/* Return true if a syncookie should be sent. */ -
bool tcp_syn_flood_action(struct sock *sk, const struct sk_buff *skb, const char *proto) -
{ -
const char *msg = "Dropping request"; -
bool want_cookie = false; -
struct listen_sock *lopt; -
#ifdef CONFIG_SYN_COOKIE -
if (sysctl_tcp_syncookies) { /* 如果允许使用SYN Cookie */ -
msg = "Sending cookies"; -
want_cookie = true; -
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPREQQFULLDOCOOKIES); -
} else -
#endif -
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPREQQFULLDROP); -
lopt = inet_csk(sk)->icsk_accept_queue.listen_opt; /* 半连接队列 */ -
if (! lopt->synflood_warned) { -
lopt->synflood_warned = 1; /* 设置SYN Flood标志 */ -
pr_info("%s: Possible SYN flooding on port %d. %s. Check SNMP counters.\n", -
proto, ntohs(tcp_hdr(skb)->dest), msg); -
} -
return want_cookie; -
}
(2)生成cookie
计算SYN Cookie的值。
函数调用路径:
tcp_v4_conn_request
|--> cookie_v4_init_sequence
|--> secure_tcp_syn_cookie
-
/* Generate a syncookie. mssp points to the mss, which is returned rounded down to the -
* value encoded in the cookie. -
*/ -
__u32 cookie_v4_init_sequence(struct sock *sk, struct sk_buff *skb, __u16 *mssp) -
{ -
const struct iphdr *iph = ip_hdr(skb); -
const struct tcphdr *th = tcp_hdr(skb); -
int mssind; /* mss index */ -
const __u16 mss = *mssp; -
tcp_synq_overflow(sk); /* 记录半连接队列溢出的最近时间 */ -
for (mssind = ARRAY_SIZE(msstab) - 1; mssind; mssind--) -
if (mss >= msstab[mssind]) -
break; -
*mssp = msstab[mssind]; -
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_SYNCOOKIESSENT); -
return secure_tcp_syn_cookie(iph->saddr, iph->daddr, th->source, th->dest, ntohl(th->seq), -
jiffies / (HZ * 60), mssind); /* 计算SYN Cookie的具体值 */ -
}
-
/* syncookie: remember time of last synqueue overflow */ -
static inline void tcp_synq_overflow(struct sock *sk) -
{ -
tcp_sk(sk)->rx_opt.ts_recent_stamp = jiffies; -
} -
/* -
* MSS Values are taken from the 2009 paper -
* 'Measuring TCP Maximum Segment Size' by S. Alcock and R. Nelson: -
* - values 1440 to 1460 accounted for 80% of observed mss values -
* - values outside the 536-1460 range are rare (<0.2%). -
* -
* Table must be sorted. -
*/ -
static __u16 const msstab[] = { -
64, -
512, -
536, -
1024, -
1440, -
1460, -
4312, -
8960, -
};
-
static __u32 secure_tcp_syn_cookie(__be32 saddr, __be32 daddr, __be16 sport, __be16 dport, -
__u32 sseq, __u32 count, __u32 data) -
{ -
/* Compute the secure sequence number. -
* The output should be: -
* HASH(sec1, saddr, sport, daddr, dport, sec1) + sseq + (count * 2^24) + -
* (HASH(sec2, saddr, sport, daddr, dport, count, sec2) % 2^24). -
* Where sseq is their sequence number and count increases every minute by 1. -
* As an extra hack, we add a small "data" value that encodes the MSS into the second hash value. -
*/ -
return (cookie_hash(saddr, daddr, sport, dport, 0, 0) + sseq + (count << COOKIEBITS) + -
((cookie_hash(saddr, daddr, sport, dport, count, 1) + data) & COOKIEMASK)); -
} -
#define COOKIEBITS 24 /* Upper bits store count */ -
#define COOKIEMASK (((__u32) 1 << COOKIEBITS) - 1) -
#define SHA_DIGEST_WORDS 5 -
#define SHA_WORKSPACE_WORDS 16
服务器的密钥、SHA1计算。
-
__u32 syncookie_secret[2] [16 - 4 + SHA_DIGEST_WORDS]; -
static __init int init_syncookies(void) -
{ -
get_random_bytes(syncookie_secret, sizeof(syncookie_secret)); -
return 0; -
} -
static DEFINE_PER_CPU(__u32 [16 + 5 + SHA_WORKSPACE_WORDS], ipv4_cookie_scratch); -
static u32 cookie_hash(__be32 saddr, _be32 daddr, __be16 sport, __be16 dport, u32 count, int c) -
{ -
__u32 *tmp = __get_cpu_var(ipv4_cookie_scratch); -
memcpy(tmp + 4, syncookie_secret[c], sizeof(syncookie_secret[c])); /* c取值为0、1 */ -
tmp[0] = (__force u32) saddr; -
tmp[1] = (__force u32) daddr; -
tmp[2] = ((__force u32) sport << 16) + (__force u32) dport; -
tmp[3] = count; -
sha_transform(tmp + 16, (__u8 *)tmp, tmp + 16 + 5); /* generate a 160-bit digest from 512-bit block */ -
return tmp[17]; -
}
SHA1
安全哈希算法(Secure HASH Algorithm)主要适用于数字签名。
对于长度小于2^64位的消息,SHA1会产生一个160位的消息摘要。当接收到消息的时候,这个消息摘要可以用来
验证数据的完整性。在传输的过程中,数据可能会发生变化,那么这时候就会产生不同的消息摘要。
SHA1有如下特性:
1. 不可以从消息摘要中复原信息。
2. 两个不同的消息不会产生同样的消息摘要。
在Git中,也使用SHA1来标识每一次提交。
-
/* sha_transform - single block SHA1 transform -
* @digest: 160 bit digest to update -
* @data: 512 bits of data to hash -
* @array: 16 words of workspace (see note) -
* -
* This function generates a SHA1 digest for a single 512-bit block. -
* / -
void sha_transform(__u32 *digest, const char *data, __u32 *array) {}
(3)保存TCP选项信息
tcp_v4_send_synack
|--> tcp_make_synack
|--> cookie_init_timestamp
如果SYNACK段使用SYN Cookie,并且使用时间戳选项,则把TCP选项信息保存在SYNACK段中tsval的低6位。
-
/* When syncookies are in effect and tcp timestamps are enabled we encode tcp options -
* in the lower bits of the timestamp value that will be sent in the syn-ack. -
* Since subsequent timestamps use the normal tcp_time_stamp value, we must make -
* sure that the resulting initial timestamp is <= tcp_time_stamp. -
*/ -
__u32 cookie_init_timestamp(struct request_sock *req) -
{ -
struct inet_request_sock *ireq; -
u32 ts, ts_now = tcp_time_stamp; -
u32 options = 0; -
ireq = inet_rsk(req); -
options = ireq->wscale_ok ? ireq->snd_wscale : 0xf; -
options |= ireq->sack_ok << 4; -
options |= ireq->ecn_ok << 5; -
ts = ts_now & ~TSMASK; -
ts |= options; -
if (ts > ts_now) { -
ts >>= TSBITS; -
ts--; -
ts <<= TSBITS; -
ts |= options; -
} -
return ts; -
} -
#define TSBITS 6 -
#define TSMASK (((__u32) 1 << TSBITS) - 1)
(4)验证cookie
函数调用路径:
tcp_v4_hnd_req
|--> cookie_v4_check
|--> cookie_check
|--> check_tcp_syn_cookie
SYN Cookie的设计非常巧妙, 我们来看看它是怎么验证的。
首先,把ACK包的ack_seq - 1,得到原来计算的cookie。把ACK包的seq - 1,得到SYN段的seq。
cookie的计算公式为:
cookie = cookie_hash(saddr, daddr, sport, dport, 0, 0) + seq +
(t1 << 24) + (cookie_hash(saddr, daddr, sport, dport, t1, 1) + mssind) % 24;
t1为服务器发送SYN Cookie的时间,单位为分钟,保留在高12位。
mssind为MSS的索引(0 - 7),保留在低24位。
现在可以反过来求t1:
t1 = (cookie - cookie_hash(saddr, daddr, sport, dport, 0, 0) - seq) >> 24; /* 高12位表示时间 */
t2为收到ACK的时间,t2 - t1 < 4分钟,才是合法的。也就是说ACK必须在4分钟内到达才行。
验证完时间后,还需验证mssind:
cookie -= (cookie_hash(saddr, daddr, sport, dport, 0, 0) - seq);
mssind = (cookie - cookie_hash(saddr, daddr, sport, dport, t1, 1)) % 24; /* 低24位 */
mssind < 8,才是合法的。
如果t1和mssind都是合法的,则认为此ACK是合法的,可以直接完成三次握手。
-
/* Check if a ack sequence number is a valid syncookie. -
* Return the decoded mss if it is, or 0 if not. -
*/ -
static inline int cookie_check(struct sk_buff *skb, __u32 cookie) -
{ -
const struct iphdr *iph = ip_hdr(skb); -
const struct tcphdr *th = tcp_hdr(skb); -
__u32 seq = ntohl(th->seq) - 1; /* SYN的序号 */ -
__u32 mssind = check_tcp_syn_cookie(cookie, iph->saddr, iph->daddr, th->source, th->dest, -
seq, jiffies / (HZ * 60), COUNTER_TRIES); -
/* 如果不合法则返回0 */ -
return mssind < ARRAY_SIZE(msstab) ? msstab[mssind] : 0; -
}
-
/* 使用SYN Cookie时,ACK超过了这个时间到达,会被认为不合法。*/ -
/* This (misnamed) value is the age of syncookie which is permitted. -
* Its ideal value should be dependent on TCP_TIMEOUT_INIT and sysctl_tcp_retries1. -
* It's a rather complicated formula (exponential backoff) to compute at runtime so it's -
* currently hardcoded here. -
*/ -
#define COUNTER_TRIES 4 /* 4分钟 */ -
static __u32 check_tcp_syn_cookie(__u32 cookie, __be32 saddr, __be32 daddr, __be16 sport, -
__be16 dport, __u32 sseq, __u32 count, __u32 maxdiff) -
{ -
__u32 diff; -
/* Strip away the layers from the cookie, 剥去固定值的部分 */ -
cookie -= cookie_hash(saddr, daddr, sport, dport, 0, 0) + sseq; -
/* Cookie is now reduced to (count * 2^24) + (hash % 2^24) */ -
diff = (count - (cookie >> COOKIEBITS)) & ((__u32) -1 >> COOKIEBITS); /* 高12位是时间,单位为分钟 */ -
if (diff >= maxdiff) -
return (__u32)-1; -
/* Leaving the data behind,返回的是原来的data,即mssind */ -
return (cookie - cookie_hash(saddr, daddr, sport, dport, count - diff, 1)) & COOKIEMASK; -
}
(5)建立连接
接收到ACK后,SYN Cookie的处理函数为cookie_v4_check()。
首先要验证cookie是否合法。
如果cookie是不合法的,返回监听sk,会导致之后发送一个RST给客户端。
如果cookie是合法的,则创建和初始化连接请求块。接着为新的连接创建和初始化一个新的传输控制块,
把它和连接请求块关联起来,最后把该连接请求块链入全连接队列中,等待accept()。
时间戳对SYN Cookie有着重要的意义,如果不支持时间戳选项,则通过SYN Cookie建立的连接就会
不支持大多数TCP选项。
-
struct sock *cookie_v4_check(struct sock *sk, struct sk_buff *skb, struct ip_options *opt) -
{ -
struct tcp_options_received tcp_opt; -
const u8 *hash_location; -
struct inet_request_sock *ireq; -
struct tcp_request_sock *treq; -
struct tcp_sock *tp = tcp_sk(sk); -
const struct tcphdr *th = tcp_hdr(skb); -
__u32 cookie = ntohl(th->ack_seq) - 1; -
struct sock *ret = sk; -
struct request_sock *req; -
int mss; -
struct rtable *rt; -
__u8 rcv_wscale; -
bool ecn_ok = false; -
struct flowi4 fl4; -
if (! sysctl_tcp_syncookies || ! th->ack || th->rst) -
goto out; -
/* 验证cookie的合法性,必须同时符合: -
* 1. 最近3s内有发生半连接队列溢出。 -
* 2. 通过cookie反算的t1和mssind是合法的。 -
*/ -
if (tcp_synq_no_recent_overflow(sk) || (mss = cookie_check(skb, cookie)) == 0) { -
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_SYNCOOKIESFAILED); -
goto out; -
} -
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_SYNCOOKIESRECV); -
/* check for timestamp cookie support */ -
memset(&tcp_opt, 0, sizeof(tcp_opt)); -
/* 全面解析TCP选项,并保存到tcp_opt中 */ -
tcp_parse_options(skb, &tcp_opt, &hash_location, 0, NULL); -
/* 如果有使用时间戳选项,则从ACK的tsecr中提取选项信息 */ -
if (! cookie_check_timestamp(&tcp_opt, &ecn_ok)) -
goto out; -
ret = NULL; -
/* 从缓存块中分配一个request_sock实例,指定此实例的操作函数集为tcp_request_sock_ops */ -
req = inet_reqsk_alloc(&tcp_request_sock_ops); -
if (! req) -
goto out; -
ireq = inet_rsk(req); -
treq = tcp_rsk(req); -
treq->rcv_isn = ntohl(th->seq) - 1; /* 客户端的初始序列号 */ -
treq->snt_isn = cookie; /* 本端的初始序列号 */ -
req->mss = mss; /* 客户端通告的MSS,通过解析cookie获得 */ -
ireq->loc_port = th->dest; /* 本端端口 */ -
ireq->rmt_port = th->source; /* 客户端端口 */ -
ireq->loc_addr = ip_hdr(skb)->daddr; /* 本端IP */ -
ireq->rmt_addr = ip_hdr(skb)->saddr; /* 客户端IP */ -
ireq->ecn_ok = ecn_ok; /* ECN选项,通过TS编码获得 */ -
ireq->snd_wscale = tcp_opt.snd_wscale; /* 客户端窗口扩大因子,通过TS编码获得 */ -
ireq->sack_ok = tcp_opt.sack_ok; /* SACK允许选项,通过TS编码获得 */ -
ireq->wscale_ok = tcp_opt.wscale_ok; /* 窗口扩大选项,通过TS编码获得 */ -
ireq->tstamp_ok = tcp_opt.saw_tstamp; /* 时间戳选项,通过观察ACK段有无携带时间戳 */ -
req->ts_recent = tcp_opt.saw_tstamp ? tcp_opt.rcv_tsval : 0; /* 本端下个发送段的时间戳回显值 */ -
treq->snt_synack = tcp_opt.saw_tstamp ? tcp_opt.rcv_tsecr : 0; /* 本端发送SYNACK段的时刻 */ -
/* We throwed the options of the initial SYN away, so we hope the ACK carries the same options -
* again (see RFC1122 4.2.3.8) -
* 通过ACK段,获取IP选项。 -
*/ -
if (opt && opt->optlen) { -
int opt_size = sizeof(struct ip_options_rcu) + opt->optlen; -
ireq->opt = kmalloc(opt_size, GFP_ATOMIC); -
if (ireq->opt != NULL && ip_options_echo(&ireq->opt->opt, skb)) { -
kfree(ireq->opt); -
ireq->opt = NULL; -
} -
} -
/* SELinux相关 */ -
if (security_inet_conn_request(sk, skb, req)) { -
reqsk_free(req); -
goto out; -
} -
req->expires = 0UL; /* SYNACK的超时时间 */ -
req->retrans = 0; /* SYNACK的重传次数 */ -
/* We need to lookup the route here to get at the correct window size. -
* We should better make sure that the window size hasn't changed since we -
* received the original syn, but I see no easy way to do this. -
* 查找路由缓存。 -
*/ -
flowi4_init_output(&fl4, 0, sk->sk_mark, RT_CONN_FLAGS(sk), RT_SCOPE_UNIVERSE, -
IPPROTO_TCP, inet_sk_flowi_flags(sk), (opt && opt->srr) ? opt->faddr : ireq->rmt_addr, -
ireq->loc_addr, th->source, th->dest); -
security_req_classify_flow(req, flowi4_to_flowi(&fl4)); -
rt = ip_route_output_key(sock_net(sk), &fl4); -
if (IS_ERR(rt)) { -
reqsk_free(req); -
goto out; -
} -
/* Try to redo what tcp_v4_send_synack did. */ -
req->window_clamp = tp->window_clamp ? : dst_metric(&rt->dst, RTAX_WINDOW); -
/* 获取接收窗口的初始值,窗口扩大因子和接收窗口的上限 */ -
tcp_select_initial_window(tcp_full_space(sk), req->mss, &req->rcv_wnd, &req->window_clamp, -
ireq->wscale_ok, &rcv_wscale, dst_metric(&rt->dst, RTAX_INITRWND)); -
ireq->rcv_wscale = rcv_wscale; -
/* 到了这里,三次握手基本完成。 -
* 接下来为新的连接创建和初始化一个传输控制块,并把它和连接请求块关联起来。 -
* 最后把该连接请求块移入全连接队列中,等待accept()。 -
*/ -
ret = get_cookie_sock(sk, skb, req, &rt->dst); -
/* ip_queue_xmit() depends on our flow being setup -
* Normal sockets get it right from inet_csk_route_child_sock() -
*/ -
if (ret) -
inet_sk(ret)->cork.fl.u.ip4 = fl4; -
out: -
return ret; -
} -
/* RFC 1122 initial RTO value, now used as a fallback RTO for the initial data -
* transmssion if no valid RTT sample has been accquired, most likely due to -
* retrans in 3WHS. -
*/ -
#define TCP_TIMEOUT_FALLBACK ((unsigned) (3 * HZ)) -
/* syncookies: no recent synqueue overflow on this listening socket? -
* 如果最近3s内没有发生半连接队列溢出,则为真。 -
*/ -
static inline bool tcp_synq_no_recent_overflow(const struct sock *sk) -
{ -
unsigned long last_overflow = tcp_sk(sk)->rx_opt.ts_recent_stamp; -
return time_after(jiffies, last_overflow + TCP_TIMEOUT_FALLBACK); -
}
如果SYNACK段使用SYN Cookie,并且使用时间戳选项,则把TCP选项信息保存在SYNACK段中tsval的低6位。
所以,现在收到ACK后,可以从ACK段的tsecr中提取出这些选项。
-
/* When syncookies are in effect and tcp timestamps are enabled we stored addtional tcp -
* options in the timestamp. -
* This extracts these options from the timestamp echo. -
* The lowest 4 bits store snd_wscale. -
* next 2 bits indicate SACK and ECN support. -
* return false if we decode an option that should not be. -
*/ -
bool cookie_check_timestamp(struct tcp_options_received *tcp_opt, bool *ecn_ok) -
{ -
/* echoed timestamp, lowest bits contain options */ -
u32 options = tcp_opt->rcv_tsecr & TSMASK; -
/* 如果ACK没有携带时间戳,则把tcp_opt中的tstamp_ok、sack_ok、wscale_ok -
* snd_wscale和cookie_plus置零。 -
*/ -
if (! tcp_opt->saw_tstamp) { -
tcp_clear_options(tcp_opt); -
return true; -
} -
if (! sysctl_tcp_timestamps) -
return false; -
tcp_opt->sack_ok = (options & (1 << 4)) ? TCP_SACK_SEEN : 0; -
*ecn_ok = (options >> 5) & 1; -
if (*ecn_ok && ! sysctl_tcp_ecn) -
return false; -
if (tcp_opt->sack_ok && ! sysctl_tcp_sack) -
return false; -
if ((options & 0xf) == 0xf) -
return true; /* no window scaling. */ -
tcp_opt->wscale_ok = 1; -
tcp_opt->snd_wscale = options & 0xf; -
return sysctl_tcp_window_scaling != 0; -
}
为新的连接创建和初始化一个传输控制块,然后把完成三次握手的req和新sock关联起来,
并把该连接请求块移入全连接队列中。
-
static inline struct sock *get_cookie_sock(struct sock *sk, struct sk_buff *skb, -
struct request_sock *req, struct dst_entry *dst) -
{ -
struct inet_connection_sock *icsk = inet_csk(sk); -
struct sock *child; -
/* 为新的连接创建和初始化一个传输控制块。 -
* 对于TCP/IPv4,实例为ipv4_specific,调用tcp_v4_syn_recv_sock() -
*/ -
child = icsk->icsk_af_ops->syn_recv_sock(sk, skb, req, dst); -
if (child) -
/* 把完成三次握手的连接请求块,和新的sock关联起来,并把它移入全连接队列中。*/ -
inet_csk_reqsk_queue_add(sk, req, child); -
else -
reqsk_free(req); -
return child; -
} -
static inline void inet_csk_reqsk_queue_add(struct sock *sk, struct request_sock *req, struct sock *child) -
{ -
reqsk_queue_add(&inet_csk(sk)->icsk_accept_queue, req, sk, child); -
}
把完成三次握手的连接请求块,和新的sock关联起来,并把它移入全连接队列中,等待被accept()。
-
static inline void reqsk_queue_add(struct request_sock_queue *queue, struct request_sock *req, -
struct sock *parent, struct sock *child) -
{ -
req->sk = child; /* 连接请求块request_sock,关联了一个新sock */ -
sk_acceptq_added(parent); /* 监听sock的全连接队列中的连接请求个数加一 */ -
/* 全连接队列是一个FIFO队列,把req加入到队列尾部 */ -
if (queue->rskq_accept_head == NULL) -
queue->rskq_accept_head = req; -
else -
queue->rskq_accept_tail->dl_next = req; -
queue->rskq_accept_tail = req; -
req->dl_next = NULL; -
} -
static inline void sk_acceptq_added(struct sock *sk) -
{ -
sk->sk_ack_backlog++; -
}
评价
SYN Cookie技术由于在建立连接的过程中不需要在服务器端保存任何信息,实现了无状态的三次握手,从而有效的
防御了SYN Flood攻击。但是该方法也存在一些弱点。由于cookie的计算只涉及到包头部分信息,在建立连接的过程
中不在服务器端保存任何信息,所以失去了协议的许多功能,比如超时重传。此外,由于计算cookie有一定的运算量,
增加了连接建立的延迟时间,因此,SYN Cookie技术不能作为高性能服务器的防御手段。通常采用动态资源分配机制,
当分配了一定的资源后再采用cookie技术,Linux就是这样实现的。还有一个问题是,当我们避免了SYN Flood攻击的
同时,也提供了另一种拒绝服务攻击方式,攻击者发送大量的ACK报文,服务器忙于计算验证。尽管如此,在预防
SYN Flood供给方面,SYN Cookie技术仍然是有效的(引用自[1])。
扩展
Linux内核中的SYN Cookie机制主要的功能是防止本机遭受SYN Flood攻击。
SYN Cookie Firewall利用SYN Cookie的原理,在内网和外网之间实现TCP三次握手过程的代理(proxy)。
一些SYN攻击的防火墙也是基于SYN Cookie,只是把这个功能移动到内核之外的代理服务器上。
Reference
[1]. https://www.ibm.com/developerworks/cn/linux/l-syncookie/
=====================================================================================================================================================================
tcpsyncookies----常见内核参数的修改
![]()
linanx0人评论9885人阅读2018-06-29 19:19:30
*tcpsyncookies
是一个开关,是否打开SYN Cookie功能,该功能可以防止部分SYN×××。
tcpsynackretries和tcpsynretries定义SYN的重试次数。
YN Cookie是对TCP服务器端的三次握手做一些修改,专门用来防范SYN Flood×××的一种手段。它的原理是,在TCP服务器
接收到TCP SYN包并返回TCP SYN + ACK包时,不分配一个专门的数据区,而是根据这个SYN包计算出一个cookie值。这个
cookie作为将要返回的SYN ACK包的初始序列号。当客户端返回一个ACK包时,根据包头信息计算cookie,与返回的确认序列
号(初始序列号 + 1)进行对比,如果相同,则是一个正常连接,然后,分配资源,建立连接。
原理:在Tcp服务器收到Tcp Syn包并返回Tcp Syn+ack包时,不专门分配一个数据区,而是根据这个Syn包计算出一个cookie值。在收到Tcp ack包时,Tcp服务器在根据那个cookie值检查这个Tcp ack包的合法性。如果合法,再分配专门的数据区进行处理未来的TCP连接。
默认为0,1表示开启
net.ipv4.tcpfintimeout
修改timewait状的存在时间,默认的2MSL
注意:timewait存在且生存时间为2MSL是有原因的,见我上一篇博客为什么会有timewait状态的存在,所以修改它有一定的风险,还是根据具体的情况来分析。
tcpretries1
放弃回应一个TCP连接请求前﹐需要进行多少次重试。RFC 规定最低的数值是3﹐这也是默认值
tcpretries2
TCP失败重传次数,默认值15,意味着重传15次才彻底放弃.可减少到5,以尽早释放内核资源.
---------------------------------------------------------------------------------------------------------------------------------------------------------------
nf_conntrack
该模块在kernel 2.6.15(2006-01-03发布) 被引入,支持ipv4和ipv6,取代只支持ipv4的ip_connktrack,用于跟踪连接的状态,供其他模块使用。
最常见的使用场景是 iptables 的 nat 和 state 模块:
nat 根据转发规则修改IP包的源/目标地址,靠nf_conntrack的记录才能让返回的包能路由到发请求的机器。
state 直接用 nf_conntrack 记录的连接状态(NEW/ESTABLISHED/RELATED/INVALID)来匹配防火墙过滤规则。
在服务器访问量大时,如果内核netfilter模块conntrack相关参数配置不合理,就会导致新连接被drop掉
推荐bucket至少 262144,max至少 1048576,不够再继续加。
net.netfilter.nf_conntrack_count 的数字持续超过 nf_conntrack_max 的 20% 就该考虑调高上限了;
测试没问题后可以写入配置文件 vim /etc/sysctl.d/90-conntrack.conf :
net.netfilter.nf_conntrack_buckets = 262144
net.netfilter.nf_conntrack_max=1048576
net.nf_conntrack_max=1048576
net.netfilter.nf_conntrack_tcp_timeout_fin_wait=30
net.netfilter.nf_conntrack_tcp_timeout_time_wait=30
net.netfilter.nf_conntrack_tcp_timeout_close_wait=15
net.netfilter.nf_conntrack_tcp_timeout_established=300
#########################################################################################
如何修改内核参数:::
Linux在系统运行时修改内核参数(/proc/sys与/etc/sysctl.conf),而不需要重新引导系统,这个功能是通过/proc虚拟文件系统实现的。
在/proc/sys目录下存放着大多数的内核参数,并且设计成可以在系统运行的同时进行更改, 可以通过更改/proc/sys中内核参数对应的文件达到修改内核参数的目的(修改过后,保存配置文件就马上自动生效),不过重新启动机器后之前修改的参数值会失效,所以只能是一种临时参数变更方案。(适合调试内核参数优化值的时候使用,如果设置值有问题,重启服务器还原原来的设置参数值了。简单方便。)
但是如果调试内核参数优化值结束后,需要永久保存参数值,就要通过修改/etc/sysctl.conf内的内核参数来永久保存更改。但只是修改sysctl文件内的参数值,确认保存修改文件后,设定的参数值并不会马上生效,如果想使参数值修改马上生效,并且不重启服务器,可以执行下面的命令:
#sysctl –p
常用的内核参数:
net.ipv4.tcpsyncookies = 1
#表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN×××,默认为0,表示关闭;
net.ipv4.tcptwreuse = 1
#表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcptwrecycle = 1
#表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcpfintimeout = 30
#表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。
net.ipv4.tcpkeepalivetime = 1200
#表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟。
net.ipv4.iplocalportrange = 1024 65000
#表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为1024到65000。
net.ipv4.tcpmaxtwbuckets = 5000
#表示系统同时保持TIMEWAIT套接字的最大数量,如果超过这个数字,
#TIMEWAIT套接字将立刻被清除并打印警告信息。默认为180000,改为5000。
#对于Apache、Nginx等服务器,上几行的参数可以很好地减少TIMEWAIT套接字数量,
#但是对于Squid,效果却不大。此项参数可以控制TIMEWAIT套接字的最大数量,避免Squid服务器被大量的TIMEWAIT套接字拖死。*
-------------------------------------------------------------------------------------------------------------------------------------------------------------
如何尽量处理TIMEWAIT过多
sysctl改两个内核参数就行了,如下:
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
简单来说,就是打开系统的TIMEWAIT重用和快速回收,至于怎么重用和快速回收,这个问题我没有深究,实际场景中这么做确实有效果。
用netstat或者ss观察就能得出结论。
还有些朋友同时也会打开syncookies这个功能,如下:
net.ipv4.tcp_syncookies = 1
打开这个syncookies的目的实际上是:“在服务器资源(并非单指端口资源,拒绝服务有很多种资源不足的情况)不足的情况下,尽量
不要拒绝TCP的syn(连接)请求,尽量把syn请求缓存起来,留着过会儿有能力的时候处理这些TCP的连接请求”。
如果并发量真的非常非常高,打开这个其实用处不大。=====================================================================================================================================================================
支付系统接口性能压力测试TPS优化之路
本文案例是我们品课学院在银行系统性能测试第一个案例,由发生至解决,通过对业务逻辑的认知、测试环境的了解、测试脚本的开发、服务的监控分析优化、操作系统的监控分析与优化、从基础软件到架构级优化改良、测试报告的编写等,一路艰辛,但是最终柳暗花明。
问题总结回顾
1. 每一次攻坚性能故障问题都是一次惊喜的探险,需要清醒头脑、大局观的分析意识、扎实的专业基础等更要凝结你的意志和自信心,因为这是一个艰苦而有趣的过程。
2. 纸上得来终觉浅, 绝知此事要躬行,一切性能测试与问题的分析优化,不是看完一篇文章做完几个项目就能提升,需要持续兴趣吃苦的煎熬来不断提炼优化自己的知识与技能才能慢慢的在博大精深的性能世界里认知了解游趟。
故事案例发生原因
故事原因:某知名城商行代支付管理系统,因上线一段时间后客户量剧增,在生产运行过程中偶尔会出现资源争用现象,客户领导担心目前环境无法满足业务量日益增长发展趋势。 因此该行邀请一家合作公司帮忙测试分析问题,该供应商跟他们合作关系一直友好也很支持,派了一位十几年性能测试经验的行业专家过去,因业务逻辑、技术框、测试脚本等编写比较复杂,工作量也大支持了十几天后,因该性能测试专家临时有事情,只能忍痛隐退,这时该供应商刚好项目紧张人员无法抽取,找到我们品课学院,让我们帮忙测试,得此机会我和柠檬老师两个利用周五晚上和周末时间过去支持,柠檬老师主要负责压力测试和测试数据维护工作,我负责性能定位分析优化和测试报告编写,因时间紧迫,测试过程中没有使用第三方工具,都是直接使用命令或者数据库自带的函数等进行监控分析。
测试实施场景
到客户现场后,客户开发人员很耐心的帮我讲解了业务逻辑、技术框架等以及环境情况,也介绍了目前情况,在高并发下TPS 大概在300笔/S,而且上下波动很大,目前尚未查出具体问题原因,希望能在最短时间内帮忙定位出来,不然已经临近上线,还好长期在金融行业做性能测试,能短时间内理清问题的来龙去脉,也最快的时间内切入到团队中。因每个人写脚本、参数化方式风格不一样,我也看了之前脚本编写很规范,但是每个人对脚本的使用方式有点差异性,我花了点时间重新修改编写LR脚本、shell脚本,估计是运气好或者有相关项目经验,在压力测试过程中,就发现问题并提供解决方案,通过描述问题原理以及操作系统工作原理、交易脚本使用原理等跟客户开发人员交流后,就这样客户也在最短时间内从陌生到认可,并得到大力支持,运气来了,做事就是给力。
这次接口实时交易测试数据准备相对比较简单,不用准备存量的业务数据,只需把对应的业务脚本T0交易的脚本参数化好,确保高并发下不出现业务数据重复即可,而针对T0插入到过程表的数据,通过使用verify交易进行时时查询处理到目标表,具体脚本如下:
1、 实时交易都是接口报文,分为socket协议脚本T0交易和http协议脚本verify交易,其中HTTP协议脚本是对T0的socket脚本插入到过程表数据进行查询后更新然后插入到目标表。
2、 批量脚本,需要每秒钟通过使用FTP协议进行模拟从不同服务器定时触发传输文件大小为1.5M的txt文件,文件内容是类似二维表数据方式存储,传输到目标服务器后进行文件解析插入到对应服务目标库。
涉及性能测试业务脚本,通过loadrunner 的socker进行编写,如下

测试过程问题分析
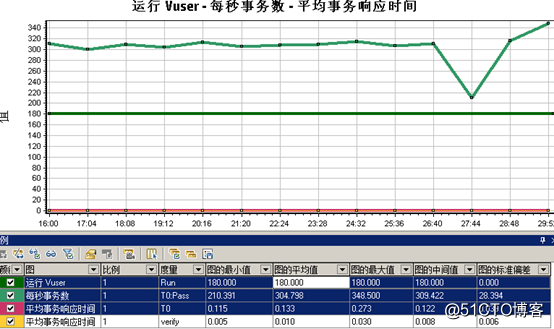
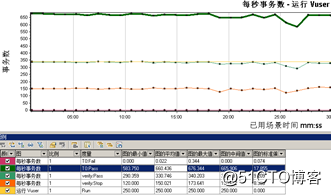
优化前:TPS只有304笔/秒,而且不稳定,在并发到一定时间后,TPS就掉下去,而且交易成功率80%不到,随时间推移交易成功率也会持续降低,没办法满足测试方案设定预期指标550笔/S,交易成功率99%,优化前通过loadrunner压测结果如下TPS 304笔/S:
1、数据库问题分析优化方法
在压力测试过程中发现TPS不高,而且随着用户并发数增加TPS反而降低,交易成功率也逐渐下降,看了各服务器资源使用都在理想状态下,与实现怀疑下数据库是否有问题,因测试交易是接口测试,SQL语法相对简单,都是单表操作,查看了数据库相应的parameter数值,发现都是默认配置,无法满足高并发,于是建议他们DBA修改下SGA、连接数等数据库参数,重新并发发现TPS有明显提升,但是还是没办法满足指标要求,因为磁盘IO高了,于是抓取语法分析,都是类似如下锁:Select ….for update,说明问题是Lock For Update,Lock Row Share,,该锁的工作原理是在并发时会创建打开游标,后返回集中的数据行都将处于行级(Row-X)独占式锁定,其他对象只能查询这些数据行,不能进行update、delete或select for update操作。
3级锁有:Insert, Update, Delete, Lock Row Exclusive
该问题说明在没有commit之前插入同样的一条记录会锁等待现象, 于是建议项目组人员把每次inster单笔数据改为改为多笔同时commit,500笔一次,然后重新压测,发现能支持更高并发游湖,而且TPS也上去达到预期指标值,具体抓取如下问题分析。
1.1 表面性能问题监控

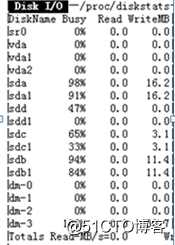
监控发现数据库服务器磁盘IO写入一直偏高,如下图:
oracle函数看到后台数据库块写数据问题情况,如下,

1.2 内核问题定位分析
通过与开发人员分析,因为T0交易在高并发下线把数据写入到过程表,这时在通过业务查询功能,查询出对应的过程表数据,通过促发for update,进行查询更新到目标表。我们通过时时关注过程表数据增加量与被更新到目标表,移除量,就是看例如每秒增加10000笔下,一次性能被更新一刀目标表数据量有多少表,例如在高并发过程表数据都能维持在100笔,而且在停止并发时,过程表数据能及时被更新迁移到目标表,说明处理能力可接受,如果更新迁移到目标表时间一直小于过程表增加速度,说明并发数高或者能力处理有问题,因出现问题才会建议项目开发人员 每次500笔commit一次,来提升TPS 和数据插入处理能力。
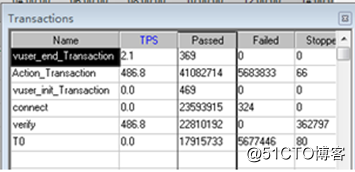
而在过程表数据量逐渐增加情况下,前端TPS 也在降低,失败率也在增加,如下图:
2、应用方面问题分析优化
而应用方面,在通过java批处理方式调度实时处理过程表数据后,对于一些业务规则判断代码也做了优化,后面我们在java应用中监控到java内存回收使用有点异常,发现JVM参数配置不合理,内存回收不及时问题,通过优化配置JVM后,以及把对应应用日志记录级别做了修改后,TPS可以稳定在800笔/S,以上。
3、其他问题分析优化方法
经分析后,在To对应的SOCKET交易与过程表verify对应的HTTP交易脚本并发数配比改为2:1,然后开发人员后台调度时时java批处理及时处理掉T0交易的数据,确保过程表数据量都在100笔以下,
这时的TPS,稳定在660笔/S,交易成功率也在99.9%,不会大批量出错现象。
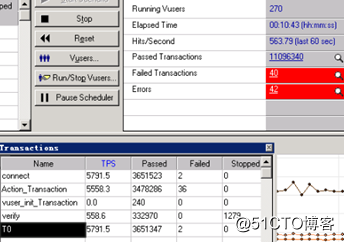
性能优化攻坚战后期:
测试环境硬件配置:应用服务器三台,数据库一台,负载均衡服务器一台,在高并发下,三台服务器处理很轻松,但是在更高用户并发下,TPS还是上不去,资源利用率也不行,反而失败率会增加,客户领导希望能继续挖掘问题,因此只能在继续发挥想象力,从全局角度看待问题,碰巧发现操作系统的文件句柄数量不足,于是让客户帮忙修改了下,发现TPS有适当提升,可以达到800笔/S,但是还是不能满足现状,发现压力测试时间久了,TPS就会抖动,而且越往后越厉害,说明资源释放有点问题,需要时间释放,然后才能回收,TPS才能提升,发现HTTP交易verify在处理过程表数据的时候,端口申请数量一直增加不能马上释放,以为是操作系统参数设置问题,于是就修改了操作系统参数,tcp_syncookies 等参数,但是在高并发下还是有问题,后来经推敲分析是verify脚本处理过程表数据给下游时是走HTTP协议,高并发下需要申请不同端口等,只能架构调整分离,然后在负载分发方式处理,TPS终于从800笔/S,直接飙到大于5000笔/S,而且成功率达到99.99%,资源利用率也上去了,终于大功告成。
我们的攻坚团队
在测试过程中,客户领导、两位开发人员、我和柠檬一起加班熬夜分析攻坚各种技术问题,才能短时间内顺利的把任务完成。
性能问题定位分析是一种技术活,性能优化分析是一种艺术活,达芬奇的艺术来源以长期技术的锻炼积累得来灵感,而性能测试分析优化也是如此。对于一个大项目的性能测试分析优化,不是一个人能完成的事情,是需要一个团队协作,是需要一个拥有高度的执行力的团队,是一个责任分明的团队,在应对突发、严重、紧急情况时,能通过专门的攻坚团队来解决这类问题,这个团队应该包括项目组的核心专业人员,有较强的动手能力和研究能力,能够变通解决问题,思路开阔。他们的作用是至关重要的,往往可能决定项目的成败。
作者:郭柏雅(泊涯)
拥有13年软件从业经验,12年的金融项目性能实施管理与测试质量控制咨询经验,通过相关行业的开发和高级测试认证,例如SQL SERVER开发认证,高级软件评测师认证等。
2010年加入上市公司高伟达集团公司,具有8年测试团队建设管理经营经验,先后在不同城商行的项目担任过性能测试优化专家、项目群测试管理、企业级IT测试质量控制管理规划咨询建设,其中包含,建行、兴业银行、鄞州银行、唐山银行、华夏银行、泉州银行、厦门银行、四川农信等商业银行以及烟草系统、ERP制造业、医疗等项目,也经常到高校分享职业发展技能知识和厦门本地其他企业生产性能故障分析优化支持,例如典型案例如下:
2006年,参与某国有大行26亿信贷项目建设的性能测试;
2007年,参与某国有大行证券交易管理系统性能测试;
2008年,参与某国有大行卡系统日终处理性能测试与优化;
2009年,参与某国有大行所有系统用户统一登录认证(单点登录系统)性能测试与调优;
2010年,参与某国有大行当时第一个且数据量最大解决巴塞尔协议的风险加权资产类项目,并获得银行业科技三等奖
2014-2016年,参与某国有大行新一代800亿级项目,负责该行四大重点项目中的信贷与客户管理项目群的非功能测试咨询与性能故障分析优化和功能测试管理支持工作;
2017年,负责某城商行IT质量规划建设咨询,负责质量测试管理咨询。
================================================================================================================================================================================================================================================================================================================================================================================================
SYN-Flood遭遇战——Linux内核SYN-Cookie实现探究
2012年07月25日 09:04:33 lucien 阅读数:2424 标签: linux内核tcpdstprocessinglinuxstruct 更多
个人分类: linux内核
SYN Flood好使啊,成本低廉,简单暴力,杀伤力强,更重要的是:无解,一打一个准!这种攻击充分利用了TCP协议的弱点,可以很轻易将你的网络打趴下。如果监控和应急不到位的话,那就等着被用户骂吧。
虽说是无解,但还是可以想想办法在TCP协议上做点手脚在稍微防范下比较小规模的攻击的。至少不会沦落到随便找个小P孩搞一些PC机随便打一下,你的主机就跨了吧。
SYN Flood的基本原理就是耗尽你主机的半开连接资源。那么最简单的方法便是减少TCP握手的超时,让攻击包消耗的资源尽量稍微快点释放。这样能将系统抵抗能力提高个几倍。但是面对洪水一样的攻击包,一两倍的抵抗能力提高是浮云啊。
所以人们就想在握手协议上做点手脚,让攻击的包不会占用资源就好了。常用的方法是SYN Cookie。思路也比较简单暴力(以暴制暴):第一个SYN包来了之后,不分配资源,返回一个经过构造的ACK序号,然后看回复的ACK号能不能对上号,对上了再分配资源,否则那个SYN包便是攻击了,果断放弃。来看看Linux2.6内核中的SYN Cookie功能是如何实现的吧。
tcp会话握手协议的处理在net/ipv4/tcp_ipv4.c中,而cookie的生成和检查在net/ipv4/syncookies.c中。
当新的连接请求(SYN包)到达时内核是这么处理的(删除了大部分代码):
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
|
看到了,如果开启了SYN Cookie,内核会将初始的流水号做成一个cookie,这个cookie是由cookie_v4_init_sequence函数生成。否则,就分配资源了。
如果对方没有响应,则timeout,资源也不会占用,如果回应了,我们看看处理的代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
在最后,做了cookie的检查,如果检查通过会返回正常的sock,否则返回NULL。下面看看cookie是如何生成和检查的。
先是生成函数(在syncookies.c中):
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
|
比较简单,注释也很清楚,将源地址/端口,目标地址/端口,还有当前时间(单位:分钟),还有MSS(最大报文长度)对应的ID传给secure_tcp_syn_cookie来算了个hash作为cookie。
接着看检查:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
|
cookie_check中的cookie参数是这样来的:cookie = ntohl(th->ack_seq) – 1。好了,直接从返回的ACK号里面解出上次种下的mssid,看看对不对。以暴制暴,清爽无比。
不过,SYN Cookie也不是救世主,这只能对付很小规模的SYN Flood。攻击流量一大,连CPU都要爆了。还是要在网络节点上做流量清洗啊。