章节目录
第一节:下载solr 第二节:解压、启动、访问solr
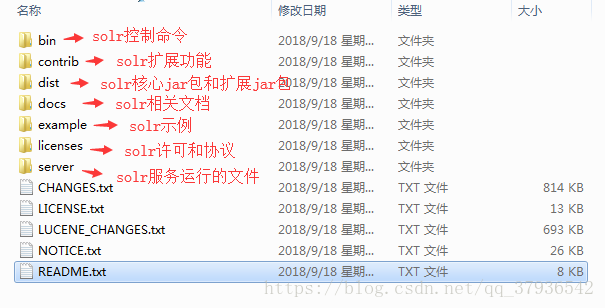
第三节:使用命令添加/删除 core 第四节:core相关配置文件简介及操作
第五节:IK分词器 第六节:从数据库导入数据到solr
第七节:使用solrj操作solr
一:下载solr

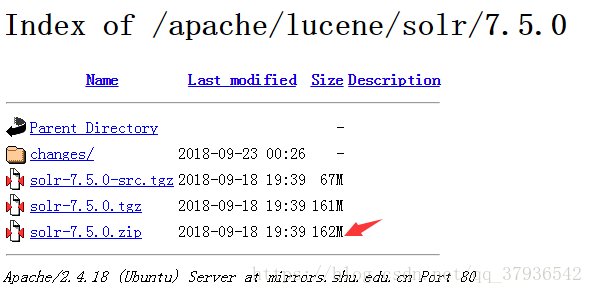
二:解压,启动,访问solr服务
▶▶ 解压
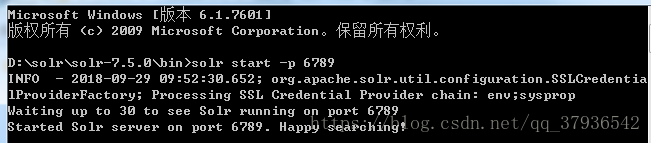
▶▶ 启动:进入bin目录,打开cmd,启动命令 solr start,默认端口8983,启动时可以通过 -p 来指定端口号
如:solr start -p 6789
▶▶ 访问 浏览器输入:http://localhost:6789/solr

▶▶ solr 启动、停止、重启命令
solr start -p 端口号
solr stop -all
solr restart -p 端口号
三:使用命令添加/删除 core
create
● solr create -c name
delete
● solr delete -c name
示例:创建名为 mote 的core,并访问这个core
▶▶ 创建
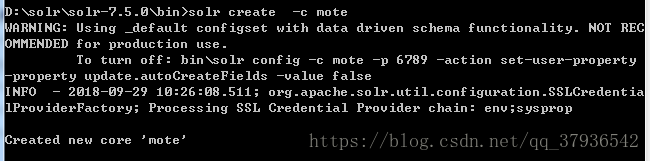
▶▶ 查看 路径:solr-7.5.0\server\solr

▶▶ 访问

四:core的配置文件介绍
路径:solr-7.5.0\server\solr\mote\conf
下图中标红的两个文件是最重要的两个配置文件
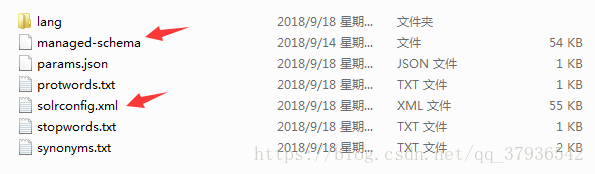
▶▶ solrconfig.xml
solrconfig.xml主要定义了Solr的一些处理规则,包括索引数据的存放位置,更新,删除,查询的一些规则配置
● luceneMatchVersion:表示solr底层使用的是lucene版本
● lib:表示solr引用包的位置,当dir对应的目录不存在时候,会忽略此属性
● datadDir:定义了索引数据和日志文件的存放位置
● directoryFactory:索引存储方案
● codecFactory:指定编码、解码器
● indexConfig:设置索引的低级别的属性
● updateHandler
☛ updateLog:设置索引库更新日志
☛ autoCommit:设置自动硬提交方式
● query:设置查询相关参数
● requestHandler:solr请求转发器
● requestHandler:solr请求映射处理器
▶▶ managed-schema
managed-schema主要定义了索引数据类型,索引字段等信息。老版本的schema配置文件是schema.xml,它的编辑方式是手动编辑,而managed-schema的编辑方式是通过chemaAPI来配置
● uniqueKey:文档的唯一标示,相当于主键,每次更新,删除的时候都根据这个字段来进行操作
● fieldtype
☛ 定义数据类型
☛ 定义当前类型建立索引和查询数据的时候使用的查询分词器

● field:指定建立索引和查询数据的字段
● dynamicField:动态定义一个字段,只要符合规则的字段都可以
例 <dynamicField name="*_i" stored="true" indexed="true" type="int"/>
*_i 只要以_i结尾的字段都满足这个定义。
● copyField:把一个字段的值复制到另一个字段中,这样搜索的时候都可以根据一个字段来进行搜索
▶▶ Schema API 操作managed-schema
准备工具 Postman 地址:Postman 下载
● add-field

managed-schema中查找到刚添加的feild
● delete-field

更多操作参考官方文档:schema-api
五:IK分词器
下载地址1:ik分词器 下载
下载地址2:ik分词器 下载

● 将 ik-analyzer-solr7-7.x.jar 放入 solr-7.5.0\server\solr-webapp\webapp\WEB-INF\lib 目录下
● 配置managed-schema
<!-- 定义ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>● 重启Solr solr restart -p 6789
● 测试 ik分词器效果
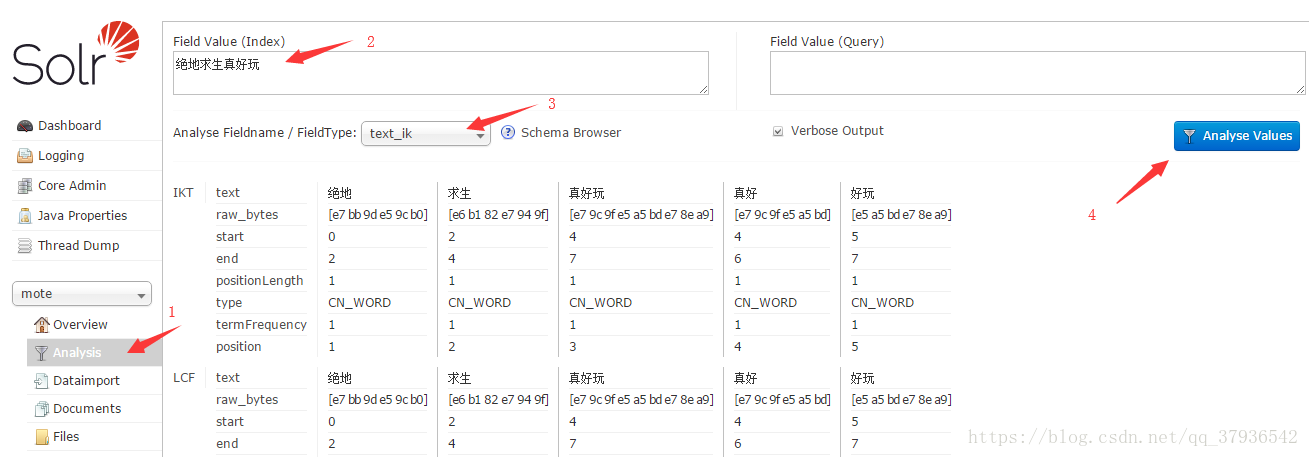
● 定义 ik分词器的 拓展/停用 词典
1:在 solr-7.5.0\server\solr-webapp\webapp\WEB-INF 新建classes目录
2:在classes新建三个文件

3:编辑文件内容
ext.dic

stopword.dic

IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典-->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>● 重启Solr
● 重新分词,将结果与上次进行对比
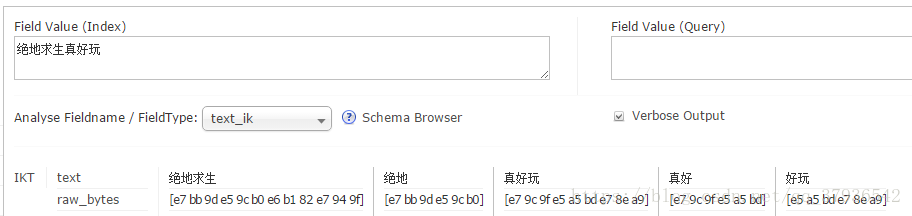
六:将数据库数据导入solr
方式一:SolrJ导入,第七节中说
方式二:Solr DataImportHandler
DataImportHandler提供一种可配置的方式向Solr导入数据,可以全量导入,也可以增量导入,还可声明式提供可配置的任务调度,让数据定时从关系型数据库中更新数据到Solr服务器
● 下载 mysql-connector-java-6.0.6.jar 添加到solr-7.5.0\server\solr-webapp\webapp\WEB-INF\lib 下
● 将solr-dataimporthandler-7.5.0.jar 、solr-dataimporthandler-extras-7.5.0.jar 从 solr-7.5.0\dist 复制到solr-7.5.0\server\solr-webapp\webapp\WEB-INF\lib 下
● 使用Postman 添加field,与数据库表的字段对应起来(id字段配置文件中本来就有)
{
"add-field":{
"name":"name",
"type":"text_ik",
"stored":true,
"indexed":true}
}● 修改 solrconfig.xml 添加 dataImport 请求资源映射
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>● solr-7.5.0\server\solr\mote 目录下创建 data-config.xml,配置访问数据库的用户名、密码、查询语句,column对应数据库中字段、name对应solr的schema.xml中字段
<dataConfig>
<dataSource driver="com.mysql.cj.jdbc.Driver" url="jdbc:mysql://IP:3306/库名" user="账号" password="密码"/>
<document>
<entity name="user" query="select * from 表名">
<field column="id" name="id" />
<field column="name" name="name" />
</entity>
</document>
</dataConfig>● 重启Solr: solr restart -p 6789
● 导入数据
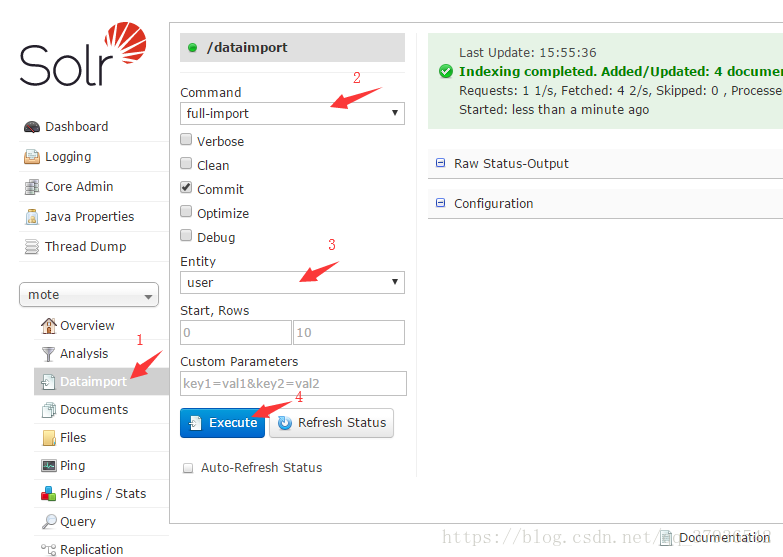
● 查看数据
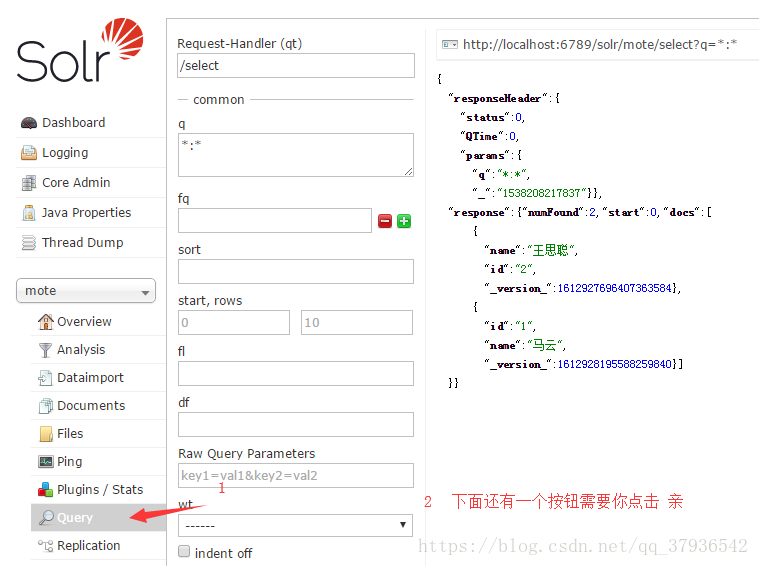
7:SolrJ
SolrJ是访问Solr服务的JAVA客户端,提供索引和搜索的请求方法,SolrJ通常嵌入在业务系统中,通过solrJ的API接口操作Solr服务
● 导入maven依赖
<!-- solrj -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.4.0</version>
</dependency>
<!-- json操作:jackson -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>${jackson.version}</version>
</dependency>
● 定义User
import org.apache.solr.client.solrj.beans.Field;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
//jackSon注解:忽略未匹配到的字段
@JsonIgnoreProperties(ignoreUnknown = true)
public class User {
public User(String id, String name) {
super();
this.id = id;
this.name = name;
}
public User() {
super();
}
// solr查询若直接将数据转为对象,需要指定Field,该值需要和managed-schema配置Field的name一致
@Field("id")
private String id;
@Field("name")
private String name;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User [id=" + id + ", name=" + name + "]";
}
}
● 测试CRUD
import java.util.List;
import java.util.Map;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrInputDocument;
import org.junit.Before;
import org.junit.Test;
public class SolrJCRUD {
private SolrClient solrClient;
/**
* 初始化solrClient
*/
@Before
public void before() {
solrClient = new HttpSolrClient.Builder(
"http://localhost:6789/solr/mote").build();
}
/**
* 通过对象添加单条数据,若添加时id已存在,那么solr会执行修改操作
*/
@Test
public void addBean() throws Exception {
User user = new User("6", "小美眉");
solrClient.addBean(user);
solrClient.commit();
}
/**
* 批量添加 也就是第六节提到的方式一
*/
@Test
public void addBeans() throws Exception {
// 从数据库查出所有的user,UserService操作数据库部分的代码省略
List<User> users = UserService.getUsers();
// 添加
solrClient.addBeans(users);
solrClient.commit();
}
/**
* 通过document添加单条数据
*/
@Test
public void addDocument() throws Exception {
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "5");
document.addField("name", "girl");
solrClient.add(document);
solrClient.commit();
}
/**
* 两种删除方式
*/
@Test
public void deleteById() throws Exception {
// 方式一:根据id删除
solrClient.deleteById("4");
// 方式二:根据查询结构删除
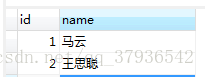
solrClient.deleteByQuery("name:马云");
solrClient.commit();
}
/**
* 查询
*/
@Test
public void query() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("name:马云");
// 设置排序
solrQuery.setSort("id", SolrQuery.ORDER.desc);
// 设置分页信息
solrQuery.setStart(0);
solrQuery.setRows(2);
// 设置高亮
solrQuery.setHighlight(true); // 开启高亮组件
solrQuery.addHighlightField("name");// 高亮字段
solrQuery.setHighlightSimplePre("<em>");// 标记,高亮关键字前缀
solrQuery.setHighlightSimplePost("</em>");// 后缀
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<User> users = response.getBeans(User.class);
// 将高亮的标识写进对象的name字段上
Map<String, Map<String, List<String>>> map = response.getHighlighting();
for (Map.Entry<String, Map<String, List<String>>> highlighting : map
.entrySet()) {
for (User user : users) {
if (!highlighting.getKey().equals(user.getId().toString())) {
continue;
}
user.setName(highlighting.getValue().get("name").toString());
break;
}
}
// 打印搜索结果
for (User user : users) {
System.out.println(user);
}
}
}
linux 单机版solr:linux单机版 solr