一、为什么要用ConcurrentHashMap
经典讲解为什么并发不用HashMaphttps://blog.csdn.net/mydreamongo/article/details/8960667
HsahMap在并发执行put操作时会引起死循环,是因为多个线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会死循环获取Entry。
Hashtable容器使用的是synchronized来保证线程安全,但是Hashtable性能低下。原因是当一个线程访问Hashtable的同步方法的时候,另外的线程只能进入阻塞状态,等待那个拥有同步锁的线程释放同步锁。所以线程竞争同步锁越激烈,Hashtable的性能越低下。综上,Hashtable性能低下的原因是所有线程竞争同一把锁。
为了改善多个线程竞争同一把锁导致的性能低下的缺点,ConccurentHashMap采用的是锁分段技术。锁分段技术的原理是:当操作互不影响,锁就可以分离。ConcurrentHashMap把这个容器分为若干段,每段分配一把锁。当一个线程访问其中一个段的数据的时候,其它段的数据也能被其它线程访问到。
二、ConcurrentHashMap在JDK1.7的经典结构
ConcurrentHashMap是由Segment数组与HashEntry数组构成。每个ConcurrentHashMap持有一个Segement数组。而每个Segment对象由一个HashEntry数组构成。HashEntr数组其实就是一个小的哈希表。如果研究过HashMap的内部结构,你就应该知道HashMap内部是数组加链表的数据结构,Segment正如HashMap的结构类似,可以说每段Segment就是一个小的HashMap。

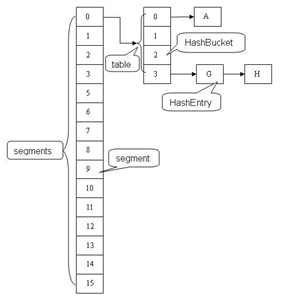
三、核心源码解析
导致结构变化的方法:都是加锁的,比如 put、remove、clean。get不加锁。
初始化一个ConcurrentHashMap的构造函数中,除了做了一些健壮性判断,最重要的初始化了内部的Segment[ ]数组Segments与创建一个Segment对象。以后在调用put方法的时候,会陆续创建更多的Segment对象。
// create segments and segments[0]
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
//省略其它健壮性判断
//创建第一段Segment
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
//创建Segment[]数组Segments
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
//赋值给ConcurrentHashMap内部的对象
this.segments = ss;
}(1)Segment的结构
//Segment可以视为一个小的HashMap,但是因为继承了ReentrantLock,所以可以保证线程安全。
//那HashEntry又是怎么回事?HashEntry可以视为HashMap中的节点,用于封装键值对。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
//加载因子
final float loadFactor;
//阙值:达到多少个元素的时候需要扩容
transient int threshold;
//内部的哈希表,节点就是HashEntry
transient volatile HashEntry<K,V>[] table;
//添加键值对到内部数组+链表中
final V put(K key, int hash, V value, boolean onlyIfAbsent){..};
}(2)HashEntry结构
HashEntry是用来存储键值对的,那么它的结构又是什么呢?原来这个HashEntry就是一个类似HashMap内部的Entry节点。
/**
* ConcurrentHashMap list entry. Note that this is never exported
* out as a user-visible Map.Entry.
*/
static final class HashEntry<K,V> {
//此节点的hash值
final int hash;
//此节点的键
final K key;
//此节点的值,使用volatile修饰,保证立马对其它线程可见
volatile V value;
//因为它是一个链表数据结构,所以要保存下一个节点的引用,volatile保证立马对其它线程可见。
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
//设置下一个节点的引用
final void setNext(HashEntry<K,V> n) {
UNSAFE.putOrderedObject(this, nextOffset, n);
}
//省略其它
}(3)put方法,添加键值对.(加锁)
//这是ConcurrentHashMap的put方法
public V put(K key, V value) {
//创建一个Segment引用
Segment<K,V> s;
//如果值为空,则抛异常
if (value == null)
throw new NullPointerException();
//第一次计算hash值:确定数据在哪个具体的Segment中
int hash = hash(key);
//j索引:指在哪个具体的Segment中。即数据应该存放在Segment[j]段中
int j = (hash >>> segmentShift) & segmentMask;
//第一次调用的时候,创建指定的Segment段,以及Segment对应的HashEntry[]数组
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
//若指定Segment段不存在,则创建它
s = ensureSegment(j);
//将数据存放到指定段中
return s.put(key, hash, value, false);
}
//嵌套类Segment的put方法,相当于小HashMap的put方法
//static class Segment extends ReentrantLock
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//获取同步锁
HashEntry<K,V> node = tryLock() ? null :
//如果key没有找到,则返回一个新节点,并加锁。否则返回null
//如果没有获取到同步锁,那么也不能闲着。
//作者说是预热代码:循环获取同步锁,当然了有重试次数的限制,这个代码很有启发
//次数到了之后,还没有获取到同步锁,那么就进入阻塞状态,随时争夺同步锁
//如果没有,返回一个新的节点,省的下面再创建。
//既然返回了,也说明当前线程已经获取到同步锁了。
scanAndLockForPut(key, hash, value);
//旧值引用
V oldValue;
try {
//把这个Segment中的哈希表 HashEntry[] table 赋给 tab
HashEntry<K,V>[] tab = table;
//第二次计算hash值,获取这个key在这个Segment的哪个链表上
int index = (tab.length - 1) & hash;
//获取这个链表的头节点
HashEntry<K,V> first = entryAt(tab, index);
//从头节点开始,循环遍历
for (HashEntry<K,V> e = first;;) {
//从头节点开始找,是不是有相同key的键值对
if (e != null) {
K k;
//如果有相同key的键值对
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
//那么就用新值替换旧值,并退出循环
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
//如果没有找到,那么就继续遍历这个链表,直到到链表末尾,执行下面的else的代码
e = e.next;
}
//如果遍历完了整个链表都没有发现有相同的key的元素
//那么put的目的就是把新这个新元素加入的concurrentHashMap中
//效果是:创建最新的节点到tab[index]链表的头位置,以前的节点挂在这个节点的next引用上
else {
//之前新创建的节点不为空
//那么就把这个新节点的下一个节点引用指向以前的头节点
if (node != null)
node.setNext(first);
else
//若新创建的节点为空,那么就新创建一个节点
node = new HashEntry<K,V>(hash, key, value, first);
//个数+1
int c = count + 1;
//若个数超过限制那么就扩容,不然就直接插入到链表中
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
//tab == HashEntry[] table
//在这段Hash表中的指定索引的插入最新的node
//此node的下一个节点是之前头节点
setEntryAt(tab, index, node);
++modCount;
count = c;
//新插入的节点没有旧值,那么就方法的返回值就是null
oldValue = null;
//退出循环
break;
}
}
} finally {
//释放同步锁,因为上述方法一直都在加锁的情况下进行
unlock();
}
return oldValue;
}(4)get方法(不加锁)
思路: (1)确定键值对在哪个段
(2)确定键值对在哪个小的链表上 tab[index]
(3)遍历链表,找到指定的key
说白了,就是比HashMap多一个确定段的操作。从代码上看,它是没有使用同步锁的,所以可以多个线程同时访问。另外值得一提的是,这个HashEntry内部的value属性,使用的是volatile修饰符,所以立即对其它所以线程可见。
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
//计算此key的哈希值,确定在哪个段中
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
//找到某个段,再确定这个元素在哪个tab[index]上,并确定头节点e
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
//循环遍历头节点是e这个链表,找到指定的key对应的值,并返回
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}(5)remove方法(加锁)
remove方法的思路就是确定段。再确定哪个链表。在这个链表上遍历,找到这个节点。把这个节点的前驱节点与后继节点连接上即可。当然,这个操作是要加锁的!
final V remove(Object key, int hash, Object value) {
if (!tryLock())
//循环获取同步锁
scanAndLock(key, hash);
V oldValue = null;
try {
//找到指定的小HashMap哈希表
HashEntry<K,V>[] tab = table;
//计算在哪个链表
int index = (tab.length - 1) & hash;
//获取链表头节点
HashEntry<K,V> e = entryAt(tab, index);
//前驱节点指针
HashEntry<K,V> pred = null;
while (e != null) {
K k;
//头节点的后继节点,如果这个不是要被删除的,那么就开始测试下一个
HashEntry<K,V> next = e.next;
//如果这个是我们要找的key对应的键值对
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
//获取旧值
V v = e.value;
//如果旧值为null或者旧值与要被删除的节点值一样,即找到了此键值对
if (value == null || value == v || value.equals(v)) {
//若前驱节点为空
if (pred == null),说明是要被删除的是头节点
//把头节点的后继节点放在头节点上
setEntryAt(tab, index, next);
else
//不然的话,把前驱节点与后继节点连接上
pred.setNext(next);
++modCount;
//个数减少
--count;
//返回旧值
oldValue = v;
}
break;
}
//前驱节点指针指向当前被测试的节点
pred = e;
//后继节点即将成为要被测试的节点,看是否是我们的指定的key的键值对
e = next;
}
} finally {
//同步状态减少1,说明释放了同步锁
unlock();
}
return oldValue;
}(6)size方法(先尝试不加锁,再尝试加锁)
size方法主要思路是先在没有锁的情况下对所有段大小求和,这种求和策略最多执行RETRIES_BEFORE_LOCK次(默认是两次):在没有达到RETRIES_BEFORE_LOCK之前,求和操作会不断尝试执行(这是因为遍历过程中可能有其它线程正在对已经遍历过的段进行结构性更新);在超过RETRIES_BEFORE_LOCK之后,如果还不成功就在持有所有段锁的情况下再对所有段大小求和。事实上,在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试RETRIES_BEFORE_LOCK次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。
那么,ConcurrentHashMap是如何判断在统计的时候容器的段发生了结构性更新了呢?我们在前文中已经知道,Segment包含一个modCount成员变量,在会引起段发生结构性改变的所有操作(put操作、 remove操作和clean操作)里,都会将变量modCount进行加1,因此,JDK只需要在统计size前后比较modCount是否发生变化就可以得知容器的大小是否发生变化。
至于ConcurrentHashMap的跨其他跨段操作,比如contains操作、containsValaue操作等,其与size操作的实现原理相类似,此不赘述。
参考:https://blog.csdn.net/justloveyou_/article/details/72783008