1,最近做了一个个人博客项目,使用了一个富文本编辑器,然后遇到了一个问题。我们都知道,富文本编辑器编辑的文本都是有格式,颜色之类的,而实际上在数据库中存储的不仅仅是你写的文章的内容,还有富文本编辑器自己形成的HTML标签,这些标签使富文本编辑器中的内容各式各样,即实现富文本。比如,你在富文本编辑器中写了一个文本“Long Bro博客”,并设定其为斜体粗体,那么虽然富文本编辑器显示的仍是“Long Bro博客”,但通过它存储到数据库中的文本内容不仅仅有“Long Bro博客”,还有这个字体的粗体及斜体格式,即“<b><i>Long Bro博客</i></b>”。
2,使用富文本编辑器写的博文存储到数据库后,就可以使用Javaweb的JSP及Servlet中的out.println()方法通过访问数据库向浏览器输出数据库中的数据,输出时会自动按照标签的格式来输出,即以指定格式输出文本。
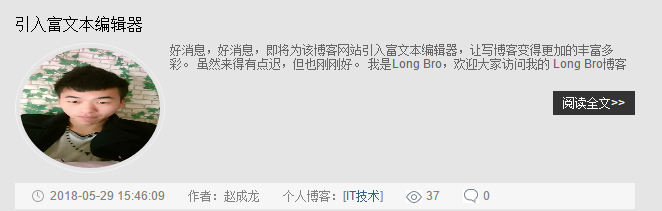
3,但是,在有些地方,我们不需要它按这种格式输出文本。如果按这种格式输出,反而使标签与标签产生冲突,造成不可逆转的后果,比如如下的博客列表展示界面(以下只截了一篇作为例子)只需要展示博客的一部分,也不必按格式显示,如果不去除数据库中的标签它反而可能会与页面中其他标签(图中的“阅读原文”,时间,作者等)相冲突,造成界面显示混乱的结果。那么这个时候,就需要做一件事情了---去除HTML标签。
4,那么问题来了,该怎么做才能将博文中的HTML标签去掉呢,啰嗦了半天,接下来进入本篇博文的重点。
String content=rs.getString("content");//content为从数据库获取的包含标签的博文内容
content=content.replaceAll("<[.[^<]]*>", "");//使用String的replaceAll方法将标签去掉,注意里面的参数通过String类的replaceAll方法将博文内容中的标签去掉。第一个参数为要替换的内容,第二个参数为替换成的内容。如上代码的意思就是将所有标签替换为一个空字符串。
5,普及一个与本篇博文无关的常识,在HTML中使用<xmp></xmp>标签可以自动忽略其中的标签,将内容按原本输出,即<p>段落</p>会输出:<p>段落</p>
好了,今天的博客写到这里就进入尾声了,感谢大家的观看。有错误的地方欢迎各位评论指正,小编在这里向大家表示感谢。欢迎大家访问我的博客网站---Long Bro博客,我在这儿等着你^~^