偏差-方差分解(Bias-Variance Decomposition)
偏差-方差分解(Bias-Variance Decomposition)是统计学派看待模型复杂度的观点。Bias-variance分解是机器学习中一种重要的分析技术。给定学习目标和训练集规模,它可以把一种学习算法的期望误差分解为三个非负项的和,即样本真实噪音noise、bias和 variance。
noise 样本真实噪音是任何学习算法在该学习目标上的期望误差的下界;( 任何方法都克服不了的误差)
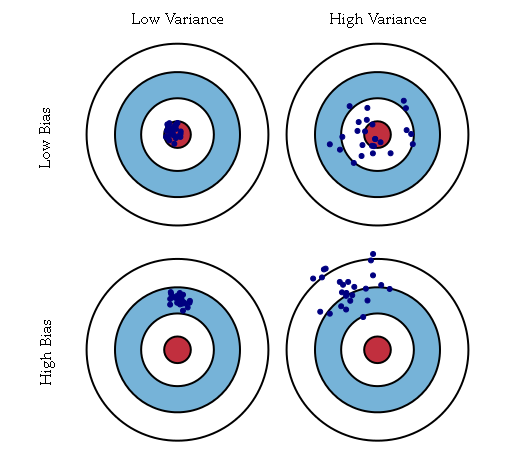
bias 度量了某种学习算法的平均估计结果所能逼近学习目标的程度;(独立于训练样本的误差,刻画了匹配的准确性和质量:一个高的偏差意味着一个坏的匹配)
variance 则度量了在面对同样规模的不同训练集时,学习算法的估计结果发生变动的程度。(相关于观测样本的误差,刻画了一个学习算法的精确性和特定性:一个高的方差意味着一个不稳定的匹配)。
偏差度量了学习算法期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;噪声表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度……泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。给定学习任务,为了取得好的泛化性能,则需使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小。-周志华《机器学习》
期望误差
整体来讲,误差可以分为3个部分

偏差-方差分解推导
样本可能出现噪声(可能是标记错误等情况),使得收集到的数据样本中的有的类别与实际真实类别不相符。对测试样本 ,另
为
在数据集中的标记,
为真实标记,
为在训练集
上学得模型
在
上的预测输出。接下来以回归任务为例:
模型的期望预测(这里指所有的样本,期望预测为该模型的所有预测结果的期望。也可以表示有多个模型同时对
一个样本进行预测,期望预测为所有模型预测的期望):
样本数相同的不同训练集产生的方差(可以理解为测试集预测结果与训练集输出期望
之间的方差,也可以直接理解为一个模型中所有的预测与预测期望之间的平方差):
噪声(这里的噪声为人工标注的错误。):
期望输出与真实标记的差别称为偏差(也有两种理解,一种是多模型的预测期望与真实值之间的偏差,还有一种就直接是单模型的预测输出(因为单模型的预测期望就是它的输出了)与真实值之间的平方差就可以记为偏差的平方,其实这里应理解为多模型的情况,即类似多折交叉验证):
通过简单的多项式展开与合并,模型期望泛化误差分解如下:
其中第三行与第六行有两式为0,具体的推导如下:
第三行:
其实不需要这么复杂的理解。因为噪声与模型无关
第六行:
简单的理解,噪声的期望为0,即,故乘积为0。
小结
偏差:度量了模型的期望预测和真实结果的偏离程度,刻画了模型本身的拟合能力。
方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
噪声:表达了当前任务上任何模型所能达到的期望泛化误差的下界,刻画了学习问题本身的难度。
在偏置和方差之间有一个折中。对于非常灵活的模型来说,偏置较小,方差较大。对于相对固定的模型来说,偏置较大,方差较小。有着最优预测能力的模型时在偏置和方差之间取得最优的平衡的模型。
灵活的模型(次数比较高的多项式)会有比较低的偏置和比较高的方差,而比较严格的模型(比如一次线性回归)就会得到比较高的偏置和比较低的方差。