GBDT原理概述
GBDT是集成学习Boosting的一种。算法流程详见集成学习之梯度提升树GBDT。
Gradient boosting的主要思想是,每一次建立单个学习器时,是在之前建立的模型的损失函数的梯度下降方向。损失函数越大,说明模型越容易出错,如果我们的模型能够让损失函数持续的下降,则说明我们的模型在不断改进,而最好的方式就是让损失函数在其梯度的方向上下降。
GBDT的核心就在于,每一颗树学的是之前所有树结论和的负梯度,这个负梯度就是一个加预测值后能够得到真实值的累加量。所以为了得到负梯度,GBDT中的树都是回归树,而不是分类树,即使GBDT是用来处理分类问题。
GBDT常用损失函数有哪些
对于分类算法,其损失函数一般有对数损失函数和指数损失函数两种:
a) 如果是指数损失函数,则损失函数表达式为

其负梯度计算和叶子节点的最佳残差拟合参见Adaboost原理篇。
b) 如果是对数损失函数,分为二元分类和多元分类两种
二元GBDT:
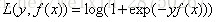
多元GBDT:
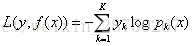
对于回归算法,常用损失函数有如下4种:

a) 均方差,这个是最常见的回归损失函数了

b) 绝对损失,这个损失函数也很常见
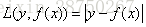
对应负梯度误差为: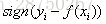
c) Huber损失,它是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心附近的点采用均方差。这个界限一般用分位数点度量。损失函数如下:
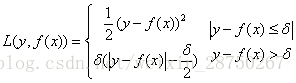
对应的负梯度误差为:
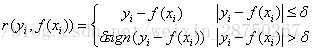
d) 分位数损失。它对应的是分位数回归的损失函数,表达式为
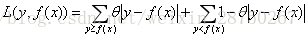
其中θ为分位数,需要我们在回归前指定。对应的负梯度误差为:

对于Huber损失和分位数损失,主要用于健壮回归,也就是减少异常点对损失函数的影响。
GBDT中为什么要用负梯度来代表残差计算
其实除了均方误差的情况一阶导是残差外,其他的情况没有残差的概念,GBDT每一轮拟合的都是损失函数负梯度。
使用梯度计算代替残差的主要原因是为了将GBDT拓展到更复杂的损失函数中。
当损失函数形式简单,可以认为模型输出值等于实际值
时损失函数最小,但当损失函数加入正则项(决策树的正则项主要是叶子节点个数,在xgboost中还与叶子节点的取值有关)后,并非在
时损失函数取得最小值,所以我们需要计算损失函数的梯度,而不能直接使用模型来计算残差。
GBDT用于分类
- GBDT无论是用于分类还是回归一直都是使用的CART回归树。
- 之所以要使用回归树,是由于分类树的结果相减是没有意义的,而回归树的结果相减为残差(梯度)是有意义的。
- 二分类的GBDT与回归问题的GBDT的区别在于以下三点:
- 树的初始化方式不同。普通的回归GBDT可将树直接初始化为一个常数(取样本均值,本质上是取一个值使得损失函数最小。)。二分类的GBDT在初始化树时也是取一个常数,这个常数为整体样本分类的一个odd,又叫机会比。
- 叶子节点取值不同。普通的回归GBDT在选定分裂特征后将每个分支节点的均值作为其节点预测值(损失函数为MSE);而二分类的GBDT选定分裂特征的规则是相同的,不过每个分支节点的预测值采用一个新的公式。
- 最重要的还是损失函数的不同。对于回归问题通常会使用MSE,对于二分类问题通常使用的是交叉熵损失(对数损失)。
- 多分类的GBDT在本质上是对二分类GBDT使用了One Vs All的策略。对于K个类别,需要训练K颗GBDT树。与普通回归GDBT的区别与二分类GDBT和普通回归GDBT的区别相差无几。其实也是在三个方向上做了改动:
- 树的棵树较二分类增多。
- 树的初始化方式改变,简单的置为0.
- 叶子节点的取值公式更新。公式较为复杂。
- 损失函数重新定义。
- 对于分类问题而言,我们用GDBT最后得到的是一个预测数值,显然需要对输出做一定的处理。常见的处理方式为,二分类问题中使用Sigmoid函数缩放到[0,1]区间后设定划分阈值。多分类问题中使用Softmax函数将概率最大的设定为该样本的预测类别。
- 虽然当GDBT用在回归和分类不同场合时,其应用细节有较大的改变,从根本的损失函数定义到节点的初始化与赋值操作,都发生了变化。但在算法的流程上,其实GBDT模型还是较为统一的,以及接下来将会介绍的Xgboost,即使作出了较多的改进,但在算法的整体流程上,依旧采用的是GDBT的模式。
使用GBDT构建特征
之前整理有整理过一点,详见高维稀疏特征及特征构建
GBDT本身是不能产生特征的,但是我们可以利用GBDT去产生特征的组合,其主要思想是GBDT每棵树的路径(每一条路径其实就是不同的特征之间的组合)直接作为其他模型的输入特征使用,例如输入逻辑回归模型中去。
具体的做法是:用已有特征训练GBDT模型,然后利用GBDT模型学习到的树来构造新特征,最后把这些新特征加入原有特征一起训练模型。
构造的新特征向量是取值0/1的,向量的每个元素对应GBDT模型中树的叶子节点。当一个样本点通过某棵树最终落在这颗树的一个叶子节点上,那么在新的特征向量中这个叶子节点对应的元素之为1,而这棵树的其他叶子节点对应的元素值为0。新特征向量的长度等于GBDT模型里所有树包含的叶子节点数之和(路径数)。

如上图,记有样本,假设我们利用已有特征已经构架出来两颗GBDT数即为tree1和tree2.然后我们将样本输入到这两棵树中去,对于每一个输入样本,其总会在每一颗树中落到一个叶节点上,同时每一个叶节点其必对应一条特征路径。假设样本落在了第一棵树的第二个节点,第二棵树的第一个节点,则我们可以为该样本添加新的特征,特征组合为每一条路径,上图中为一个5维的向量,这个特征的值为[0,1,0,1,0]。
实验证明这样会得到比较显著的提升模型效果。
论文中提到这样的GBDT树(验证树)的数量最多为500,大于500就没有性能提升了,同时每棵树的节点不多于12.
为什么GBDT不适合使用高维稀疏特征
- 特征太多,GBDT不一定跑的动,即使可以跑也会耗费很长时间。主要是由于树模型在分支时的特征选择相当耗时,尤其是当特征量很大的时候!其次由于GBDT的boosting算法,需要构建多棵CART树,虽然对于弱分类器CART树而言,不需要很深,但弱分类器的构建往往在开始的时候是很慢的。
- 树的分割往往只考虑了少量的特征,大部分的特征都用不到。boosting过程需要迭代多棵CART树,每次树的构建可能使用的特征都类似。所以高维稀疏特征会造成大量特征的浪费。
GBDT正则化
- 第一种是和Adaboost类似的正则化项,即步长(learning rate)。对于同样的训练集学习效果,较小的v意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。
- 第二种正则化的方式是通过子采样比例(subsample)。取值为(0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间。 使用了子采样的GBDT有时也称作随机梯度提升树(Stochastic Gradient Boosting Tree, SGBT)。由于使用了子采样,程序可以通过采样分发到不同的任务去做boosting的迭代过程,最后形成新树,从而减少弱学习器难以并行学习的弱点。这里其实引入了bagging的思想,所以GBDT能够有效地抵御训练数据中的噪音,具有更好的健壮性。(降低方差)
- 第三种是对于弱学习器即CART回归树进行正则化剪枝。在决策树原理篇里我们已经讲过,这里就不重复了。
GBDT调参
- n_estimators:也就是弱学习器的最大迭代次数,或者说最大的弱学习器的个数。太小容易欠拟合,太大容易过拟合。
- learning_rate:即每个弱学习器的权重缩减系数v,也称为步长。
- subsample:不放回抽样比例,又叫做子采样。如果取值为1,即使用全部样本构建GBDT。一般使用[0.5,0.8],过大可能会过拟合,过小会欠拟合。适当的子采样可以使得模型具有较好的泛化能力。
- 基分类器的叶子节点个数J选在[4,8]区间内较好,太小,需要太多的迭代次数。太大又容易过拟合。
- 预剪枝策略的设定参数,不作累述了,在之前将随机森林或者剪枝策略中都有提到过。
GBDT对异常值敏感吗?
GBDT在不使用一些健壮的损失函数的情形下,对于异常值实际上是极为敏感的。如果使用一些健壮的损失函数,如Huber以及分位数Quantile损失函数则可以改善这个状况。
从GBDT的算法模型来理解为什么GBDT对异常值相当敏感。
GBDT每一次拟合上一次弱回归树的负梯度。如果样本中存在异常值。则每一次的负梯度往往都会被异常值给放大(仔细回想回归树的最优分裂点选取准则以及子节点的预测值计算)。直观来想,其实很好理解,模型是无法判断这个值是不是异常值的,它只会机械的让模型去充分拟合样本,如果存在异常值,模型依旧希望可以较为充分的拟合它(使得损失函数最低),此时整个模型的预测就会因为一个极端的预测值而被带偏。对于正常样本的预测能力就会大大降低了。
GBDT的优缺点
优点:
- 使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
- GBDT几乎可用于所有回归问题(线性/非线性),相对logistic regression仅能用于线性回归,GBDT的适用面非常广。
- 训练过程中可以自动构建特征。同时可以用于特征构建。
- 在相对少的调参时间情况下,预测的准备率也可以比较高。这个是相对SVM来说的。
- 可以灵活处理各种类型的数据,包括连续值和离散值。(其实这可以算作是决策树的一个特性了。)
- 不需要归一化。(也算是树模型的一大特色,作为概率模型,是不需要归一化的。)
缺点:
- 由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过子采样的SGBT来达到部分并行。
- 不适合高维稀疏特征。
为什么Xgboost要用泰勒展开
Xgboost使用了一阶和二阶偏导,二阶导数有利于梯度下降的更快更准,使用泰勒展开取得函数做自变量的二阶导数形式,可以在不选定损失函数具体形式的情况下,仅仅依靠输入数据的值就可以进行叶子分裂优化计算,本质上也就把损失函数的选取和模型算法优化/参数选择分开了。这种去耦合增加了Xgboost的适用性,使得它按需选取损失函数,可以用于分类,也可以用于回归。
XGBoost的特征重要性是如何得到的
某个特征的重要性(feature score),等于它被选中为树节点分裂特征的次数的和,比如特征A在第一次迭代中(即第一棵树)被选中了1次去分裂树节点,在第二次迭代被选中2次…..那么最终特征A的feature score就是 1+2+….
Xgboost如何寻找最优特征
Xgboost在训练的过程中给出各个特征的增益评分,最大增益的特征会被选出来作为分类依据。像CART树中的基尼增益等,不过Xgboost的增益计算相对复杂。
Xgboost调参
- booster [default=gbtree]:选择基分类器,gbtree: tree-based models/gblinear: linear models
- eta [default=0.3]:shrinkage参数,用于更新叶子节点权重时,乘以该系数,避免步长过大。参数值越大,越可能无法收敛。把学习率 eta 设置的小一些,小学习率可以使得后面的学习更加仔细。
- min_child_weight [default=1]:这个参数默认是 1,是每个叶子里面 h 的和至少是多少,对正负样本不均衡时的 0-1 分类而言,假设 h 在 0.01 附近,min_child_weight 为 1 意味着叶子节点中最少需要包含 100 个样本。这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易 overfitting。
- gamma [default=0]:后剪枝时,用于控制是否后剪枝的参数。
- max_delta_step [default=0]:这个参数在更新步骤中起作用,如果取0表示没有约束,如果取正值则使得更新步骤更加保守。可以防止做太大的更新步子,使更新更加平缓。
- subsample [default=1]:样本子采样,较低的值使得算法更加保守,防止过拟合,但是太小的值也会造成欠拟合。
- colsample_bytree [default=1]:列采样,对每棵树的生成用的特征进行列采样.一般设置为:[0.5,1]
- lambda [default=1]:控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
- alpha [default=0]:控制模型复杂程度的权重值的 L1 正则项参数,参数值越大,模型越不容易过拟合。
- scale_pos_weight [default=1]:如果取值大于0的话,在类别样本不平衡的情况下有助于快速收敛。
- objective [default=reg:linear]:定义最小化损失函数类型,常用参数:
- binary:logistic –logistic regression for binary classification, returns predicted probability (not class)
- multi:softmax –multiclass classification using the softmax objective, returns predicted class (not probabilities) ,you also need to set an additional num_class (number of classes) parameter defining the number of unique classes
- multi:softprob –same as softmax, but returns predicted probability of each data point belonging to each class.
XGBoost树剪枝
- 预剪枝,
 ,每一次分类选择Gain值最大的分裂方式,可以通过调节
,每一次分类选择Gain值最大的分裂方式,可以通过调节值的大小来改变树的分裂倾向,实现预剪枝。
- 当最优分裂点对应的增益值为负值是停止分裂;
- 但是这也会存在问题,即将来的某个时刻能够获取更高的增益;
- 其次XGBoost会在完整生成一颗决策树后回溯剪枝(从底到顶进行剪枝)。
- 将决策树增长到它的最大深度,递归的进行剪枝,剪去那些使得增益值为负值的叶子节点;
XGBoost对缺失值的处理
当数据中含有缺失值的时候,我们可以不再填充缺失值。利用XGBoost的机制自动处理缺失值。

上图给出了XGBoost关于缺失值的处理方式,XGBoost为缺失值设定了默认的分裂方向,XGBoost在树的构建过程中选择能够最小化训练误差的方向作为默认的分裂方向,即在训练时将缺失值先分入左子树计算训练误差再分入右子树计算训练误差,将缺失值划入误差小的方向。
XGBoost和GBDT的区别
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
- 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性 —正则化包括了两个部分,都是为了防止过拟合,剪枝是都有的,叶子结点输出L2平滑是新增的。
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
- column subsampling列(特征)抽样,说是从随机森林那边学习来的,防止过拟合的效果比传统的行抽样还好(行抽样功能也有),并且有利于后面提到的并行化处理算法。
- xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序(预排序),然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。(其实就是在特征分类的时候,传统的做法是遍历每个特征再遍历每个特征的所有分裂点,然后去寻找一个损失最小的特征的分裂点。这些特征与特征间的选择是独立的,所以给了实现并行计算的可能性。同时在分裂点的选取的时候还需要对特征进行排序,这个也是独立的,所以也给了实现并行计算的可能。)
- 对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。上面也有讲到。
- split finding algorithms(划分点查找算法):提出了候选分割点概念,先通过直方图算法获得候选分割点的分布情况,然后根据候选分割点将连续的特征信息映射到不同的buckets中,并统计汇总信息。