一.Python中glob模块用法
glob是python自己带的一个文件操作相关模块,用它可以查找符合自己目的的文件,类似于Windows下的文件搜索,支持通配符操作
. - - 当前目录
. . --当前目录的上一级目录
“*” - -0个或多个字符
? 一个任意字符
[…]匹配指定范围内的字符,如[0-9]匹配数字。
两个主要方法如下。
1.glob方法:
glob模块的主要方法就是glob,该方法返回所有匹配的文件路径列表(list);该方法需要一个参数用来指定匹配的路径字符串(字符串可以为绝对路径也可以为相对路径),其返回的文件名只包括当前目录里的文件名,不包括子文件夹里的文件。
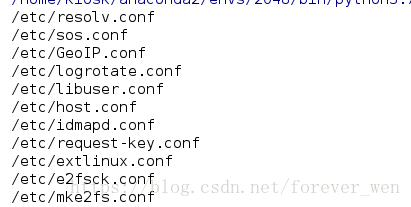
import glob
print(glob.glob('/etc/*.conf'))
print(glob.glob('/etc/????.conf', recursive=True))
print(glob.glob('/etc/*[0-9]*.conf'))
print(glob.glob('/etc/*[A-Z]*.conf'))
print(glob.glob('/etc/*[0-9A-Z]*.conf'))

- iglob方法:
获取一个迭代器( iterator )对象,使用它可以逐个获取匹配的文件路径名。与glob.glob()的区别是:glob.glob同时获取所有的匹配路径,而 glob.iglob一次只获取一个匹配路径。
import glob
print(glob.iglob('/etc/*.conf'))

要想获取所有路径,我们可以使用遍历方法实现查看路径
import glob
x = (glob.iglob('/etc/*.conf'))
for py in x:
print (py)
二.正则表达式3种处理函数
1.re.findall 函数
re.findall 从字符串的所有位置匹配一个模式,如果匹配不到,就返回一个空列表
函数语法:
re.findall(pattern, string, flags=0)
函数参数说明:
pattern :匹配的正则表达式
string :要匹配的字符串。
flags :标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
示例:
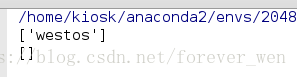
import re
s = "kiosk/home/kiosk/westosanaconda2/envs/blog/bin/python3.6/home/kiosk/Desktop/day25"
# 1. 编写正则的规则
pattern1 = r'westos' ###规则前要用‘r‘标注
pattern2 = r'kibgbosk'
# 2. 通过正则去查找匹配的内容
print(re.findall(pattern1, s))
print(re.findall(pattern2, s))
2.re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就会返回一个None对象。函数语法:
re.match(pattern, string, flags=0)
匹配成功re.match方法返回一个匹配的对象。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方法 :
1).group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
2). groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
import re
s = "kiosk/home/kiosk/westosanaconda2/envs/blog/bin/python3.6/home/kiosk/Desktop/day25"
# 1. 编写正则的规则
pattern1 = r'kiosk'
pattern2 = r'kibgbosk'
# 2. 通过正则去查找匹配的内容
print(re.match(pattern1, s))
print(re.match(pattern2, s))
matchObj = re.match(pattern1, s)
# 返回match匹配的字符串内容;
print(matchObj.group())

3.re.search函数
re.search 扫描整个字符串并返回第一个成功的匹配。如果匹配不成功的话,searh()就会返回一个None对象。
函数语法:
re.search(pattern, string, flags=0)
匹配对象方法和re.match函数一样
示例:
import re
s = "/home/kiosk/westosanaconda2kiosk/envs/blog/bin/python3.6/home/kiosk/Desktop/day25"
# 1. 编写正则的规则
pattern1 = r'kiosk'
pattern2 = r'kijosk'
# 2. 通过正则去查找匹配的内容
print(re.search(pattern1, s))
print(re.search(pattern2, s))
matchObj = re.search(pattern1, s)
# 返回match匹配的字符串内容;
print(matchObj.group())

re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
import re
s = "Cats are smarter than dogs"
matchObj = re.match(r'dogs', s)
if matchObj:
print("match --> matchObj.group() : ", matchObj.group())
else:
print("No match!!")
matchObj1 = re.search(r'dogs', s)
if matchObj1:
print("search --> matchObj1.group() : ", matchObj1.group())
else:
print("No match!!")
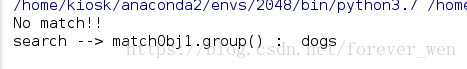
练习
1. 设计一个正则来找出一个字符串序列中的10-59;import re
s = "12 38 29 84 28 2 3"
pattern = r"[1-5][0-9]"
print(re.findall(pattern,s))
2. 设计一个正则来过滤一个字符串序列中只包含两个字符的字母, 其中第一个字母是大写的A或者B或者C;

import re
str = "AB cds Ab Bs Bg Fd Aj"
pattern = r"[A-C]{1}[a-zA-Z]{1}"
print(re.findall(pattern,str))
3. 匹配一个qq邮箱;([email protected])
xdshcdsh(可以由字母数字或者下划线组成, 但是不能以数字或者下划线开头; 位数是6-12之间)

import re
pattern = r"[a-zA-Z]{1}\w{5,11}@qq\.com"
s = re.match(pattern,"[email protected]")
if s:
print(s.group())
else:
print("no match")

import re
pattern = r"[a-zA-Z]{1}\w{5,11}@qq\.com"
s = re.match(pattern,"[email protected]")
if s:
print(s.group())
else:
print("no match")
4.有一个贴吧页面,其中含有很多页面,而每页页包含很多qq邮箱,现在我们需要将其过滤并保存到文件中。

from itertools import chain ###用来循环保存文件
from urllib.request import urlopen ##用来获取网页信息
import re
def getPageContent(url):
"""
获取网页源代码
:param url: 指定url内容
:return: 返回页面的内容(str格式)
"""
with urlopen(url) as html:
return html.read().decode('utf-8')
def parser_page(content):
"""
根据内容获取所有的贴吧总页数;
:param content: 网页内容
:return: 贴吧总页数
"""
pattern = r'<span class="red">(\d+)</span>'
data = re.findall(pattern, content)
return data[0]
def parser_all_page(pageCount):
"""
根据贴吧页数, 构造不同的url地址;并找出所有的邮箱
:param pageCount:
:return:
"""
emails = []
for page in range(int(pageCount)):
url = 'http://tieba.baidu.com/p/2314539885?pn=%d' %(page+1)
print("正在爬取:%s" %(url))
content = getPageContent(url)
# pattern = r'\w[-\w.+]*@[A-Za-z0-9][-A-Za-z0-9]+\.+[A-Za-z]{2,14}'
pattern = r'[a-zA-Z0-9][-\w.+]*@[A-Za-z0-9][-A-Za-z0-9]+\.+[A-Za-z]{2,14}'
findEmail = re.findall(pattern, content)
print(findEmail)
emails.append(findEmail)
return emails
def main():
url = 'http://tieba.baidu.com/p/2314539885'
content = getPageContent(url)
pageCount = parser_page(content)
emails = parser_all_page(pageCount)
print(emails)
with open('tiebaEmail.txt', 'w') as f:
for tieba in chain(*emails): ##解包
f.write(tieba + '\n')
main()

三.正则中的分组
当使用分组时, findall方法只能获取到分组里面的内容;
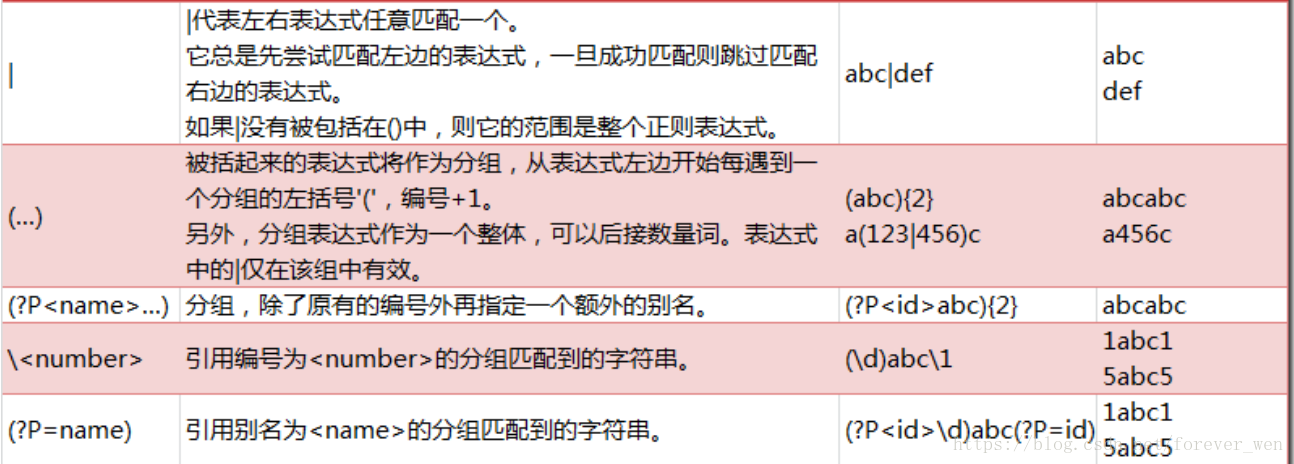
| 和(…)的用法
import re
print(re.findall(r'(westos|hello)\d+', 'westos1hello2'))
pattern = r'<span class="red">(\d+)</span>'
s = '<span class="red">3333</span>'
print(re.findall(pattern, s))
pattern = r'(<span class="red">(\d+)</span>)'
s = '<span class="red">31</span>'
print(re.findall(pattern, s))

findall不能满足时, 考虑使用search 或者match
import re
Obj = re.search(r'(westos|hello)(\d+)', 'westos1hello2')
if Obj:
print(Obj.group())
print(Obj.groups()) ###groups返回多个分组的内容
else:
print('Not Found')

\number的具体用法
import re
s = '<html><title>西部开源技术中心</title></html>'
pattern = r'<\w+><\w+>\w+</\w+></\w+>'
print(re.findall(pattern, s))
s = '<html><title>西部开源技术中心</title></html>'
# 目前有三个分组, \1: 代指第一个分组的内容, \2: 代指第二个分组的内容,
pattern = r'<(\w+)><(\w+)>(\w+)</\2></\1>'
print(re.findall(pattern, s))

P?(Name)的用法
import re
s1 = 'http://www.westos.org/linux/book/'
pattern = 'http://[\w\.]+/(?P<courseName>\w+)/(?P<courseType>\w+)/'
Obj = re.match(pattern, s1)
if Obj:
print(Obj.group()) ###匹配出内容
print(Obj.groups()) ##匹配分组内容
print(Obj.groupdict()) ###用别名匹配
else:
print('Not Found')
练习:
匹配出正确的身份证号,并表示其信息

import re
s =['610897199004154534', '210 887 19800415 4534']
for i in s:
pattern = r'(?P<Province>\d{3})[\s-]?(?P<City>\d{3})[\s-]?(?P<Year>\d{4})' \
r'[\s-]?(?P<Month>\d{2})[\s-]?(?P<Day>\d{2})[\s-]?(\d{4})'
Obj = re.search(pattern, i)
if Obj:
print(Obj.groupdict())
else:
print('Not Found')

四.正则中的分离和替换
分离
re,split方法
指定多个分隔符进行分割import re
s = '12+13-15/16'
print(re.split(r'[\+\-\*/]', s)) ###以+ - * / 任意一个为分隔符进行分割。

替换
re.sub方法
替换字符串中的匹配项语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
示例一:repl 参数不是一个函数
import re
s = "第1000条本次转发数为100"
print(re.sub(r'\d+', '0', s))
当指定最大替换次数n时,将默认替换掉前n个值

import re
s = "第1000条本次转发数为100"
print(re.sub(r'\d+', '0', s,1))
示例二:repl 参数是一个函数

import re
def addNum(sreObj):
"""在原有基础上加1"""
num = sreObj.group() # ‘100’ ‘99’
new_num = int(num) + 1
return str(new_num)
s1 = "本次转发数为100, 分享数量为99"
print(re.sub(r'\d+', addNum, s1))

五.re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:
re.compile(pattern[, flags])
参数:
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
1)re.I 忽略大小写
2)re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
3)re.M 多行模式
4)re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
5)re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
6)re.X 为了增加可读性,忽略空格和 # 后面的注释
import re
pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
m = pattern.match('Hello World Wide Web')
print (m) # 匹配成功,返回一个 Match 对象
print(m.group(0)) #返回匹配成功的整个子串
print(m.span(0)) # 返回匹配成功的整个子串的索引
print(m.start(0))
print(m.end(0))
print(m.group(1)) # 返回第一个分组匹配成功的子串
print(m.span(1)) # 返回第一个分组匹配成功的子串的索引
print(m.start(1))
print(m.end(1))
在上面,当匹配成功时返回一个 Match 对象,其中:

group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
span([group]) 方法返回 (start(group), end(group))。
应用:匹配qq邮箱
import re
mailList =["[email protected]", "[email protected]", "[email protected]", "[email protected]", "[email protected]", "[email protected]"]
# 判断邮件地址是否合法;
def ismailOK(mail_name):
reg = r"\w{4,20}@qq.com$"
reg = re.compile(reg)
a = re.match(reg, mail_name)
if a:
return True
else:
return False
mailOkList = [i for i in mailList if ismailOK(i)]
# 将符和条件的邮件地址写入文件 ;
with open("/tmp/mail.txt", "a+") as f:
for i in mailOkList:
f.write(i+"\n")
print (i)
