正则匹配原理
啦啦啦 我是一个搬运工,搬错打轻点儿 _-
说说正则的引擎
给你一个世界观
我要去西藏,走过去?内蒙离西藏 还是挺远的 我没病哈哈。我要开嘟嘟嘟的小汽车去,我只要把握好方向 发动机机会带着我去西藏看大草原了。
这个过程中:驱动就是动力系统,我们不必要关系他怎么工作的,握好方向盘就是了。
动力系统是什么呢:引擎 + 驱动装置
那这个小车车是什么类型的呢:传统的汽油机 OR 炫酷的电动车
开车的问题呢:汽油机会污染空气 但是马力足啊,电动车不污染空气 车速快 但是动力不行
所以我想要一个即速度快 有动力还不污染的车车(帅的人环保意识都强 没办法)
如果以环保为标准,我们可以得出了四种车车:污染空气的汽油车、不污染空气的汽油车、污染空气的电动车、不污染空气的电动车
电动车都不污染空气所以就只有三种了:污染空气的汽油车、不污染空气的汽油车、电动车
(虽然有点无厘头 不过先记住这个类比哈哈 对装逼有帮助)
正则引擎的分类
之前可以看看这个 恶补一下知识点(看完了 可以自己写引擎呦 点我 点我 嘤嘤嘤)
正则的引擎可以分为两种
- DFA(确定的有穷状态自动机 只要知道有就好了)-电动车
- NFA(非确定的有穷状态自动机 需要知道具体匹配到的东西)-汽油机
- POSIX 版本的NFA - 即速度快 有动力还不污染的车车
NFA比DFA出现时间要早一点,像.NET、PHP、JS都用的是这个,有些甚至还用到了egrep和awk,也有一些是混合使用这个两个的(存在性查找 用DFA,真实查找用NFA),具体如下表:
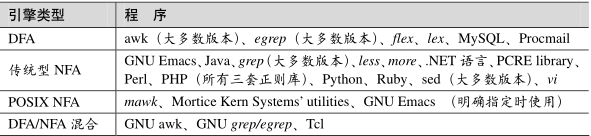
DFA的出现,必须是NFA出问题了,最主要的就是发展太久 没有规范,所以POXIS约定了一波引擎需要支持的元字符和特性,DFA是符合这标准的,所以NFA要先够装逼 就要先自己规范一波行为。
- 这里的POXIS只是匹配意义上的,规定了表达式应该有那些行为,而不是POXIS引入了一些匹配特性!
一双火眼金睛
一般区分引擎就像兼容IEX一样,检车特性就好了
- 支持忽略优先量词:NFA。在POSIX和DFA中是没有意义的,nfa|nfa not 匹配 naf,如果结果是naf not 那就不是NFA了
- 支持捕获分组和回溯:NFA。 XX———————– 匹配 X(.+)+X,如果死机(堆溢出 超时)了 那就是NFA了
- 如果上面方法失灵了,那就是油电混合动力了
- NFA因为有环视、条件判断、反向引用、固话分组等等
找类似
就想男人和女人,审理构造不一样,但是还是一个鼻子两个耳朵的,所以DFA和NFA也有一些相同的地方
- 从左到右匹配
- 匹配量词的优先级比较高
从左到右
abc 匹配 dafdsf fdsfdf dsfsdfabc abc,匹配到的是dsfsdfabc中的abc 而不是 abc(装逼时刻 showtime),如果是egrep、awk、lex、flex这种DFA确实是这样。
说说动力系统
动力系统是由引擎+驱动装置构成了,实施过程就是驱动过程。驱动装置的主要作用 就是:驱动,完成驱动过程。基础里面有个\G,讲的就是这里,一般的引擎都会在匹配失败之后 驱动引擎到下一个匹配节点,如果是^这种开头的,首次匹配失败 就会直接失败(某些流派优化过)
匹配量词的优先级高
匹配量词的结果一般都是能匹配到的最长的结果(NFA),他会不断的进行尝试,如果最终匹配到的不是最长的,那一般就是匹配字符过多 导致匹配失败了,然后为后面的固定字符释放了资源。 \bw+s\b 匹配regexes w+先匹配regexes 人后到s的时候匹配失败,回退到上一个状态,释放s 匹配成功。
这个特性非常有用,比如 abc1999 匹配 [0-9]+,1匹配成功之后 还会继续匹配 到终结符
- 不要过度使用匹配量词:aaa: (. ) 和 aaa: (. ) . *,后面的没有意义
- sfdsfdsf123fsdfasdfds匹配 ^ . * ([0-9][0-9]),释放23之后 就不释放了,也是有底线的
- ^ . * ([0-9]+)匹配 fsdfsdfsdfd 2003,结果是什么呢? 只能会退还一个3,如果+换成* 则一个都不会退还
表达式主导&文本主导
在往下挖,我们看到 DFA是文本主导的、NFA是表达式主导的
NFA 表达式主导
to(nite|knight|night|)匹配 tonight,从to开始 先检查第一组,然后是第二组,知道成功为止。表达式控制前在不同分组之间不听的切换,我们叫表达式主导。
-这个的优点就是,每个子表达式都是独立的,不同于反向引用,子表达式不存在内在联系,父表达式是通过儿子、分支、括号、量词组成的
DFA 文本主导
DFA扫描记录的是当前有效的所有记录 到i的时候 去掉knight,如下图

处理中的分支可能有很多,只要没有淘汰 就都有机会匹配成功,但是会保留一个to状态,应付所有分支都失败的情况,如果某段匹配可能失败 就会调回之前一个装填。
比较NFA和DFA
- DFA要快一点,因为表达式主导的 主导权在不同分支来回切换浪费时间
- NFA目标文本的某个字符可能会被不同分支反复匹配,没有匹配到结尾 就不知道是否失败,而DFA 如果所有分支都失败 则直接失败 不会匹配后面的了。
- NFA 表达式主导,引擎的匹配原理就比较重要了,改变表达式 或者优化匹配策略 或有很多意想不到的情况。
- tonight的例子,如果把night分支放最前面,会极大的加快速度(传统的DFA)
- DFA对表达式分支顺序没要求,都是同时匹配的,所以DFA匹配快、匹配一致、但是很蛋疼
回溯
NFA比较强大,我们就多宠信一下他 谈谈DFA的回溯
回溯就是:引擎依次处理多个分支,在分岔路口记录一下状态,留着失败回退状态。
分岔路口一般有:量词(* 跳过?还是尝试一把),多选结构
如果分支成功+剩余部分成功,则表达式成功(传统的NFA)
回溯的两个步骤 一个定义特别重要:
- 优先选那个分支:量词–匹配优先 选尝试,忽略优 选跳过
- 多选结构:stack的原则,LIFO
- 备用状态:就是每个分叉口保存的装填
比如匹配优先: ab?c 匹配 abc!!! 匹配ac呢? 再比如 abX呢?
比如忽略优先: ab??c 匹配 abc!!! 匹配ac呢? 再比如 abX呢?
回溯和匹配优先
* + 回溯
- x* 相当于 x?x?x?x?x?… 或者是(x(x(x…?)?)?),不谈性能 功能是一样的
- [0-9]+ 匹配a 1234 aaa,到4之后的空格无法匹配 所以在1234后面都会保存一次状态,空格匹配失败 回退到最近的(4之后的版本),匹配结束 成功
- 1之前是没有版本保存的,因为+至少匹配一次
- 如果[0-9]*匹配,1之前的状态会保存吗?不会 因为如果是*修饰所有表达式,在a之前的空格就成功了 结束了,除非+好后面有其他字符,促使表达式去匹配
- 之前的CA 95472 USA 匹配 ^. * ([0-9][0-9]),用现在的NFA解释一波:释放2 第一个0-9匹配,第二个失败,继续回溯。现在之前尝试的第一个是否匹配已经没用了,当前状态来到了7前面,成功,. 很吝啬,成功了 就不再释放了。
- 这种回溯机制不但要重新计算正则和目标字符串的相对位置,还要维护子表达式的匹配文本状态,每次会说 都把指正指向([0-9][0-9])的括号之前,这里可以优化一波:^. * [0-9][0-9] 减少维护$1的开销
- 还有一点注意:会竟可能的匹配, 前面的例子 ^. ([0-9]+) 只能匹配一位数字
NFA和DFA和匹配优先的火花特别多,但是我们的js是NFA 所以只要记住DFA只能是匹配优先的 用起来很方便就好了
NFA因为有环视、条件判断、反向引用、固话分组等等,可操作性比较大。
匹配优先的问题
因为匹配优先,只有在后面有其他元素压迫的时候 才会被动的释放,所以 某些时候 会出问题。
- ” . * ” 匹配 sdfsdfdsfsdf “fsdfsdf” fsdfsdf sdfsdf “sfsdfsdf” fsdfsdf –>所以不过分依赖匹配优先量词
- 可以使用[^ “]替换 . (注意. 不能匹配换行符的问题 而排出法 是可以的)
- 如果是<\B>Billions<\B> and <\B>Zillions<\B> of suns 呢? 使用[^]是不行的,所以可以用环视
- 不用环视 使用忽略优先量词 也可以
忽略优先量词的锅:(.\d \d [l-9] ?) \d * / $1/, 取1.612131300001,前三位小数问题
- 如果数字是1.632 则d* 没有匹配任何东西,浪费
- 只有有第四位数字 才使用d*呢? 换成 d+,但是1.62 这种 就崩了 d+ 没有匹配 报错了
- 那如果(.\d \d [l-9] ??) \d * / $1/ 呢? 碰到1.633 结果是1.63
回到” . * ” 匹配 sdfsdfdsfsdf “fsdfsdf” fsdfsdf sdfsdf “sfsdfsdf” fsdfsdf问题,我们发现:匹配优先 匹配最长 忽略优先匹配最短
占有优先量词和固化分组
- 不用回溯的话毫无影响
- 导致匹配失败–子表达式 xxx 子表达式这种
- 改变匹配结果
- 加快失败速度(真的会失败的时候)
- 不支持固化分组 可用占有优先量词实现
环视中的回溯
环视是不会占用字符消耗的,如果匹配成功:肯定环视 就是成功 否定环视 就是失败,这几种情况都不会保留备用状态,所以可以模拟固话分组什么的
性能分析
” . * ” 匹配 sdfsdfdsfsdf “fsdfsdf” fsdfsdf sdfsdf “sfsdfsdf” fsdfsdf,匹配优先 和 [^] ,重点是PXIOS的时候
最左最长
传动装置某位置启动了DFA,从左开始 匹配最长的为最终结果。POSIX也是如此
DFA会从分支一直进行下去 找到最长的,二POSIXDFA 则会尝试所有的可能 最终保留最长的
效率
因为NFA有回溯,所以一般时间会比DFA长,而PROSIX的脑残行为 导致在有多个匹配结果的时候 效率比NFA长
不过DFA因为碰到分支 会同时比对多个可能,所以内存和初始时间消耗 会高一点(其实就是空间换时间的问题,如果NFA分支排的好 是会比DFA快的)
再比较DFA 和NFA
- 预编译阶段的区别
- 匹配速度(见效率)
- 匹配结果的差别DFA(确定的有穷状态自动机 只要知道有就好了)、NFA(非确定的有穷状态自动机 需要知道具体匹配到的东西)
- 捕获子表达式、反向引用、环视、占有优先量词、固话分组、精确控制
- 实现难度??不清楚 没木有实现成功