第十一天 - 大数据项目结构 - Hive简介与安装配置、基本操作
一、大数据项目模块简介
数据源管理
给每个用户分配固定的存储路径,根据用户标识分配独有的空间用于存储该用户的数据源和结果输出
给每个用户分配固定的存储路径:在项目部署时手动创建;
根据用户标识分配独有的空间:在用户注册时生成对应的路径
数据源名称和数据文件需要有映射关系,并且能获取输入数据文件路径inputPath
添加数据源
- 在数据库中进行记录(当前用户的数据表中记录数据文件的相关信息,路径,数据源名称)
- 上传文件至相应路径
删除数据源
- 在数据源列表中选择要删除的数据
- 清除数据库中的记录信息
- 在hdfs中将数据文件删除
数据源信息
- 数据文件的基本信息:数据名称、数据大小、上传时间等
- 数据预览,比如展示前20条
数据源分组
一个用户上传了多份数据源,进行归类分组,对每一个组添加一个标识(组名)
计算任务
- 在列表中罗列显示当前应用中支持的算法,可以固定写死或者通过配置文件读取展示
- 向项目中添加算法时,重新编译jar包上传,更改jps页面或者更改web应用配置文件
- 用户选择相应的算法,生成命令执行所需要的信息
结果展示
- 到相应的目录下读取结果文件,展示信息
数据流程管理
- 记录整个数据处理流程,数据源,计算节点,结果文件,执行顺序,数据流程状态标识
- 数据流程列表(根据数据流程状态标识区分)
- 对于已经完成的流程,可以查看结果、重新运行、删除结果、修改执行流程
- 对于新建的流程,可以进行修改流程、运行
- 数据流程id,记录了节点(包括数据源/计算/展示)以及执行顺序
二、将项目部署到Linux中运行
项目地址
步骤
在eclipse中执行导出,导出格式为war
右键项目 – export – war File – 选择输出路径
使用Xftp将导出的wat文件上传至Linux下的tomcat安装路径下的webapps目录中
启动tomcat,详见tomcat配置
通过浏览器访问地址:sz01/WebProject,选择数据源文件和计算任务
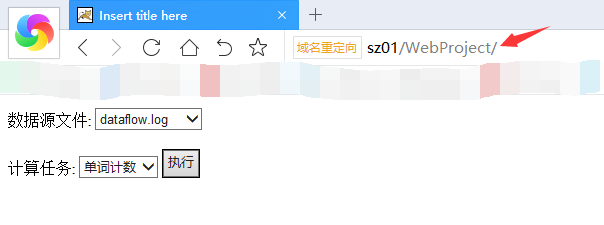
运行结果:

注意事项
MapReduce执行以队列方式执行,意思是同时跑多个MapReduce任务时,只会执行一个MapReduce任务,其他需要排队等待。所以在同时访问WebProject并且执行任务时,会排队执行MapReduce任务,等待时间较长。
三、Hive简介与安装配置、基本操作
本文以hive-1.2.2作为学习版本。
Hive简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能(Hive SQL,简称HQL)。 Hive使用HDFS作为数据存储,核心工作是将hql语句转换为MapReduce任务运行,默认使用Hadoop中的yarn作为资源调度系统。
Hive的特点
- 可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。 - 延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。 - 容错
良好的容错性,节点出现问题SQL仍可完成执行。
Hive架构
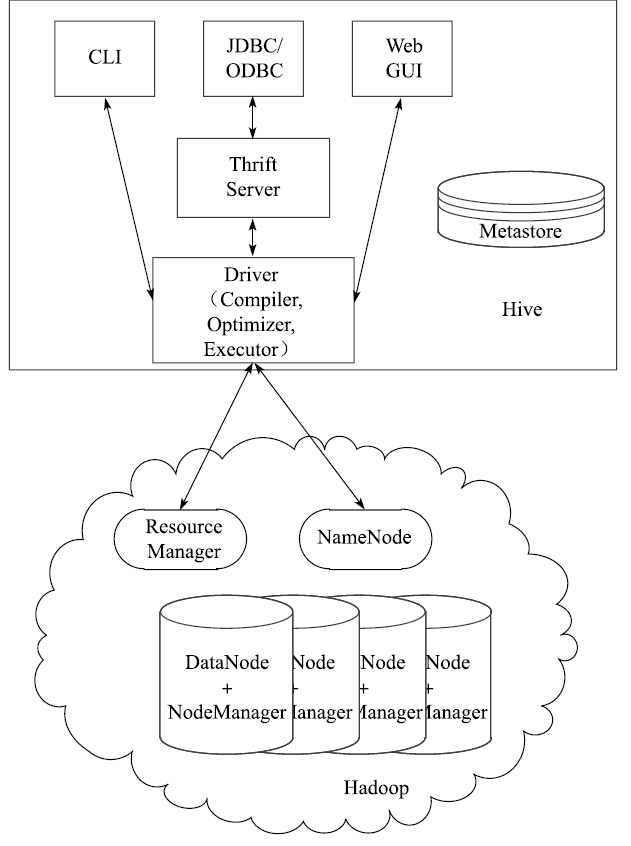
Hive包含用户访问接口(CLI、JDBC/ODBC、Web GUI和Thrift Server)、元数据存储(Metastore)、驱动组件(编译器、优化器、执行器)。
用户访问接口即用户用来访问Hive数据仓库所使用的工具接口。
MySql补充
数据库(mysql)包含数据文件、数据元信息,其中数据文件在本地磁盘中进行存储,而数据元信息记录表结构(表名,字段名,列名),记录在特定的数据表中。
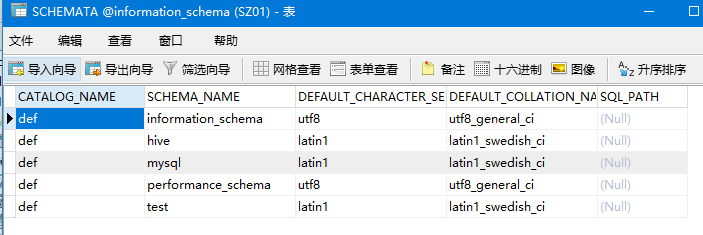
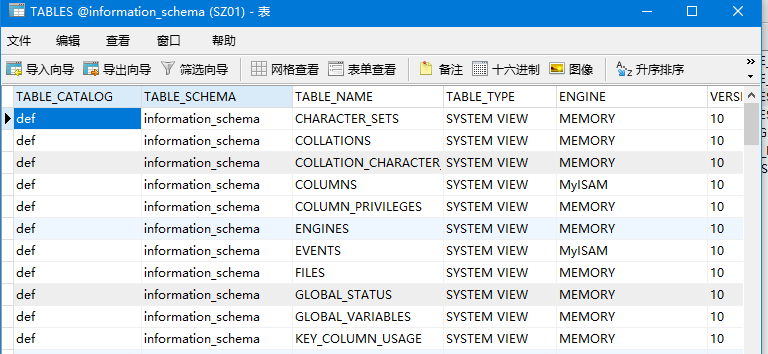
mysql数据库,在库information_schema中,表schemata存储数据库信息,tables存储表的信息
schemata:
tables:
MySql(RDBMS)与Hive对比
| 项目 | MySql | Hive |
|---|---|---|
| 数据存储 | 本地磁盘 | HDFS |
| 执行器 | Executor | MapReduce |
| 数据插入 | 批量/单条 | 批量/单条 |
| 数据操作 | 以行位单位更新删除 | 覆盖追加 |
| 处理数据规模 | 小 | 大 |
| 处理数据延迟 | 低 | 高 |
| 分区 | 支持 | 支持 |
| 拓展性 | 弱 | 强 |
| 数据加载模式 | 写时模式 | 读时模式 |
对数据的操作:
小数据量:
MySql先进行数据校验,数据是否符合格式,符合才能追加写入数据文件;
Hive直接通过插入语句生成新的数据,在相应的目录下创建新的文件,由于在集群进行操作,所以需要创建多个文件,各个节点的数据进行同步。
由于数据量小,所以Hive所花费的时间大部分花在了数据节点之间的通信、同步上,所以小数据量时的感受是mysql速度快于hive。
大数据量:
MySq支持l批量sql、结构化文件导入,首先获取数据元信息(结构信息),然后对数据库中的数据进行变更;
Hive则是将数据文件(本地磁盘)上传或移动到hdfs对应目录下,需要进行查询计算时再读取元信息,得出结果。
写时模式与读时模式对比:
MySql:写时模式,当数据发生变化时(数据插入)进行校验
Hive:读时模式,写入数据时是将数据文件移动到了目标文件夹下,当数据被使用时(查询数据、计算数据)才进行校验,容错性较强,当数据格式不对应时也不会立即报错,
Hive存储
- Hive同样包含数据文件、数据元信息,其中数据文件存储在hdfs上,数据元信息则借助mysql存储。
- hive管理的库在hdfs储存为文件夹,warehouse为default库所在的路径,其他的库以.db为结尾(存储路径可在hive-site.xml中进行配置);
- hive管理的表在hdfs存储为文件夹,在相应的库文件夹下,存储的是各个表文件夹
- hive管理的表的数据在hdfs存储为文件,在相应的表文件夹下
Hive安装
通过官网下载apache-hive-1.2.2-bin.tar.gz
将apache-hive-1.2.2-bin.tar.gz通过Xftp上传至CentOS的bigdata用户家目录
解压缩
tar -zxvf apache-hive-1.2.2-bin.tar.gz
配置
用户环境变量
修改.bash_profie
vi .bash_profile
添加两行
HIVE_HOME=/home/bigdata/apache-hive-1.2.2-bin
PATH=$PATH:$HIVE_HOME/bin
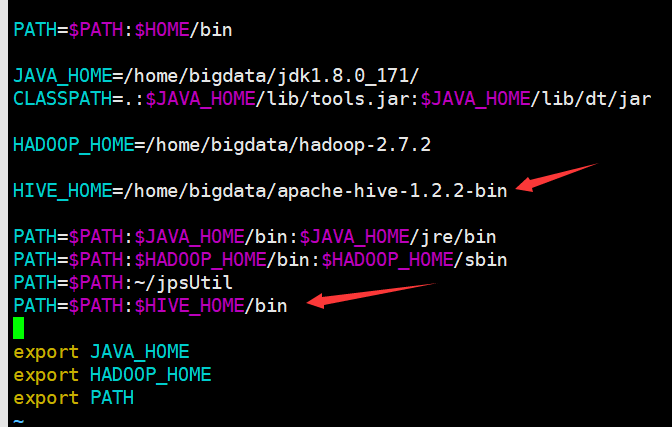
保存退出
刷新配置文件
source .bash_profile
通过which hive命令检测环境变量是否配置成功
配置文件
hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!--配置hive元数据存储使用的数据库连接驱动名--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <!--配置hive元数据存储使用的数据库URL和存储库位置(是否自动创建)--> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://SZ01:3306/hive?createDatabaseIfNotExist=true</value> </property> <!--配置hive元数据存储使用的数据库连接用户名--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!--配置hive元数据存储使用的数据库连接密码--> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> </property> <!-- <!--配置hive数据可视化需要的包--> <property> <name>hive.hwi.war.file</name> <value>lib/hive-hwi-1.2.2.war</value> </property> --> <!--配置hive数据文件在hdfs中的存储位置,如果未配置则默认/user/hive/warehouse--> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> </configuration>hive-log4j.properties(19-21行)
#日志级别 hive.root.logger=DEBUG,DRFA #日志存储目录 hive.log.dir=/home/${user.name} #日志名 hive.log.file=hive.log引入jdbc的jar包
将mysql-connector-java-5.1.46-bin.jar放在hive安装路径下的lib目录中
修改mysql在任何host下都能以root的用户密码登录
- 使用命令启动mysql,注意加上-h选项
mysql -u root -h sz01 -p
- 修改密码
set password=password(‘root’)
- 刷新权限
flush privileges
Hive启动
可以直接使用hive命令启动hive客户端

hive启动成功后,会根据hive-site.xml和hive-log4j.properties配置文件在对应的mysql数据库中生成相应的表,在对应的位置创建日志文件
通过navicat远程连接至CentOS中的mysql查看
创建库
create database test;
库hive中表DBS存储了创建库的信息
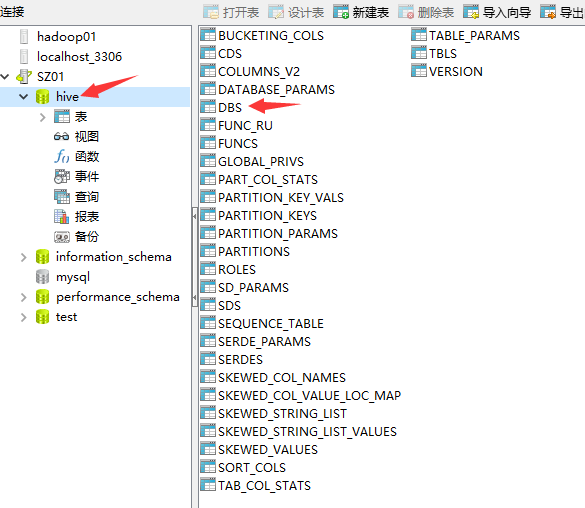
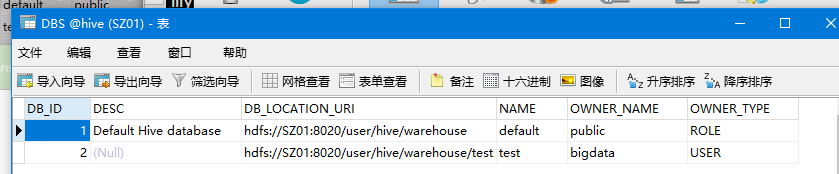
hdfs中/user/hive/warehouse目录下创建了对应的数据库test.db文件夹用于存储表文件夹
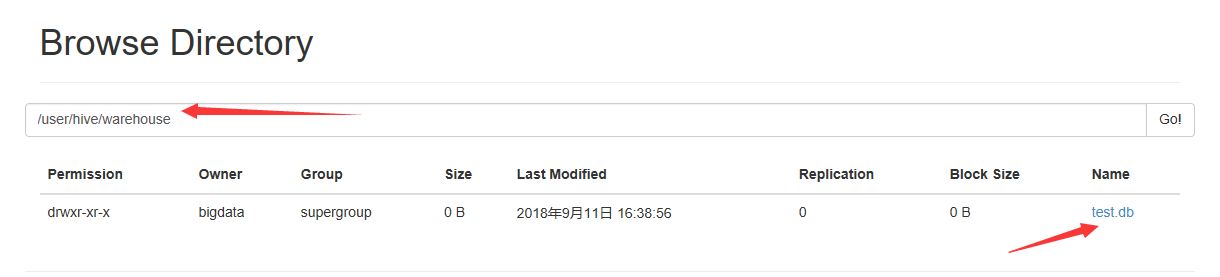
创建表
use test;
create table t1(
c1 int
);
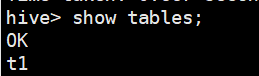
库hive中表TBLS存储了创建表的信息

库hive中表记录表信息
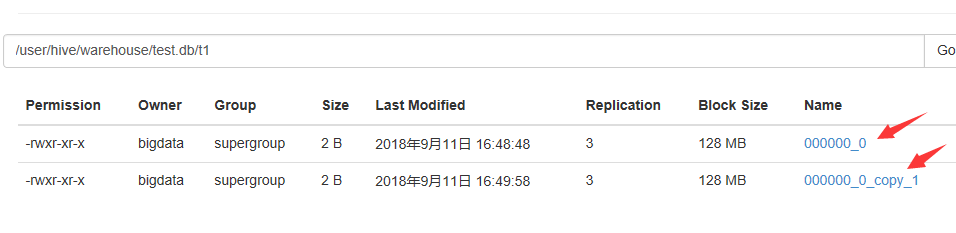
hdfs中/user/hive/warehouse/test.db目录下创建了对应的表文件夹用于存储表数据文件

对Hive的数据基本操作(一)
插入数据
insert into t1 values (1);
insert into t1 values (2);
插入数据后,将存储在hdfs中相应的表文件夹下
创建第二个表,第二个表有两列
create table t2(
c1 int,
c2 int
);
插入数据
insert into t2 values(3,3);
当表出现多个列时,查看hdfs中存储的hive数据文件,会有一个制表符进行分割
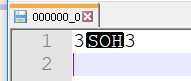
将结构化数据文件导入到hive表中
数据导入时,需要指定行分隔符,列分隔符,通过这两个分隔符去解析文件中的数据
如数据文件1内容为:
aaa,bbb,ccc;111,222,333; ddd,eee,fff;444,555,666; ggg,hhh,iii;777,888,999;当指定行分隔符为”;”,列分隔符为”,”时,以上文件则解析为六行,每行有三列数据。
指定的分隔符必须与文件中的分隔符相一致,否则虽然导入时不会出问题,但是在读取、操作数据时就会出现错误
例如:
数据文件2内容为:以“-”为列分隔符,”\n“为行分隔符
1-1-1\n 2-2-2\n 3-3-3\n将此文件作为数据导入源文件
此时有一个表test,以c1 int, c2 int, c3 int为表数据结构,当读取此导入的数据时,期待的数据应该是
1 1 1 2 2 2 3 3 3但此时如果指定了以“\n”为行分隔符,“,”为列分隔符进行读取时,读取到的数据将会是:
1-1-1 null null 2-2-2 null null 3-3-3 null null不符合预期,所以在读取数据时需要指定与源文件向符合的行、列分隔符。