本系列文章由 @yhl_leo 出品,转载请注明出处。
文章链接: http://blog.csdn.net/yhl_leo/article/details/52857657
把前段时间自己整理的一个关于卷积神经网络应用于图像语义分割的PPT整理发布在本篇博客内,由于部分内容还在研究或发表过程中,就只上传PPT前两部分的内容。

今天给大家介绍卷积神经网络在图像语义分割上的一些方法和应用。

PPT的目录包括,语义分割的简单介绍,然后介绍一些我的研究和具体的应用,最后简单说一下我最近的一些研究工作。

图像语义,也就是图像理解,图像作为一种信息记录方式,每张图像都会传达出一些信息,就像一个故事。比如左边的图像,我们可以简单地分析出,有一只黑白斑纹的小猫,趴在一个木质的小木桌上,一只爪子按着一个有线鼠标,另一只放在一个打开的黑色的笔记本电脑上,旁边好像还站着个人。但是怎么能让计算机理解这些呢?这是个很难的问题,即便现在我们通过深度学习进行目标检测,可以得到图像场景中可能有哪些目标,但是要实现这样更深层次的理解,还是非常困难。

目标检测和语义分割,是两种理解图像语义的基础方法,主要是为了解决,图像中有什么,在哪里的问题。虽然看起来解决的问题很相似,但是却差异很大。

从输出结果来看,目标检测网络更加宽松,只要给定一个包含目标的最小窗口区域就可以,可以说它是window级别的方法,得到粗检测结果;而分割网络更加细致,强调像素级的精细化检测结果,需要输出每个像素所属的类别。
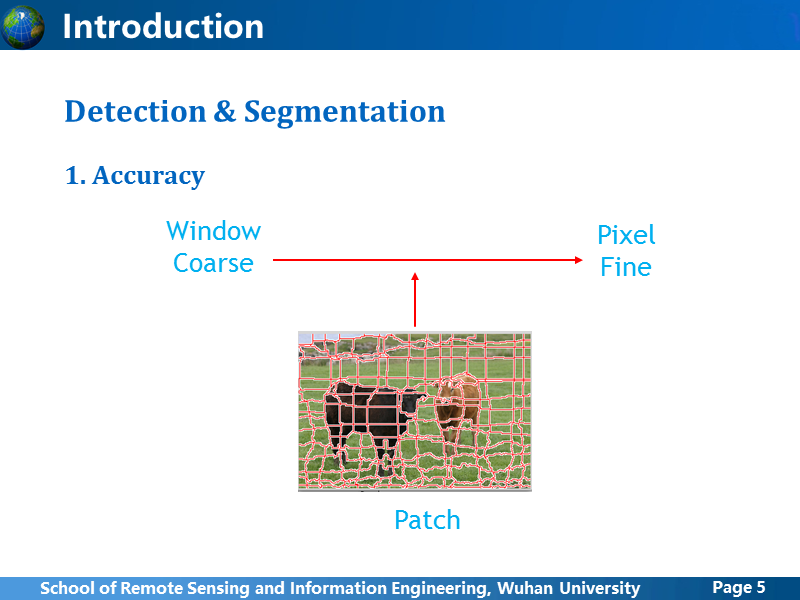
从粗糙到精细,还有一种折中方法,就是基于图像分割方法,比如超像素,把相近的像素分在一个不规则的小patch里,这种方法在语义分割中也有应用,后面会简单介绍一下。

由于表达方式的特殊,目标检测窗口定位的方法,限制了它的使用范围,对于那些单个中心分布式物体,按照部件模型的理解,目标可以分为几个子部件,子部件之间相互紧密连接的目标,目标检测可以做得还不错,但是此外还有很多其他类型的目标物,比如道路,建筑群,裂缝很多情况下,如果使用目标检测的方法,对于一张输入图像,得到的反馈窗口很有可能是整图像,还有倾斜的文本,使用bbox表示,这些与预期有很大差异。
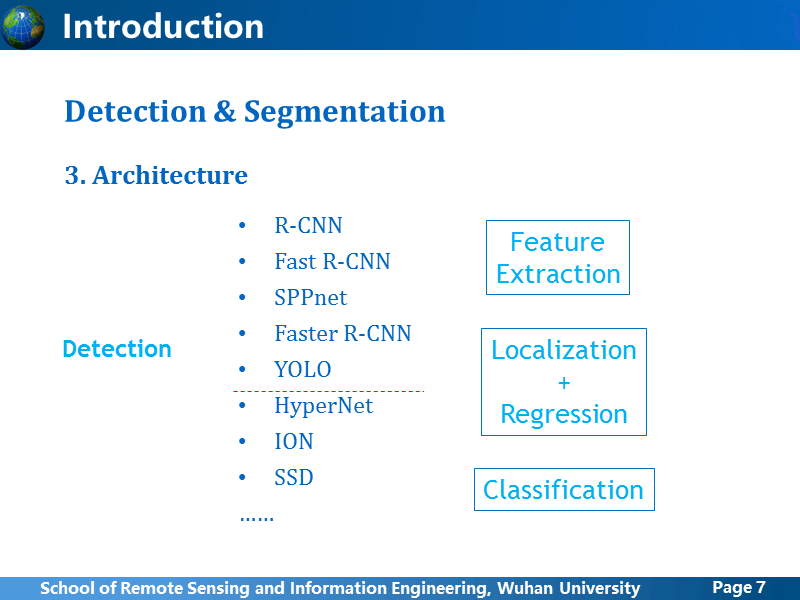
同样由于窗口表达的特殊性,目标检测的网络架构从R-CNN开始,虽然在网络结构,提取proposal上进行很多探索,基本思想上还是沿用R-CNN,一般都包括卷积网络学习特征,根据候选区分类,然后回归定位窗口。其中,为了解决深度网络中小目标,弱目标的梯度消失问题,后面列举的三种网络,都尝试了融合不同尺度的卷积feature map,不过SSD网络的”多尺度”跟另外两个还有些区别,这里就不提了。前一段时间,ImageNet挑战赛的结果公布,大家评论说,Facebook, Google等这些实力雄厚的公司都没参加,我觉得可能是有两方面的原因,第一点,从2012年到现在,虽然只有四年左右的时间,基于目前框架下的这种目标检测似乎已经快要触碰到极限,当然还是有很多人在尝试,试图在这个框架下不断优化,但是是能够提升的空间还是不大,这些有实力的研究机构应该是不屑于去做这些事的,大家都在期待一种新的黑科技,这才是那些机构的方向;第二点,图像语义本身是个涉及范围比较广的概念,目标检测仍然属于比较浅层的图像理解,本身应用范围非常有限,而更高级的像素级图像语义,比如语义分割(Semantic Segmentation)、深度预测(Depth Prediction)、生成对抗网络(GAN)等,都取得了突破,也逐渐成为研究热点。理论上来说,如果语义分割做得很好了,这种粗略的目标检测也就不需要做了。
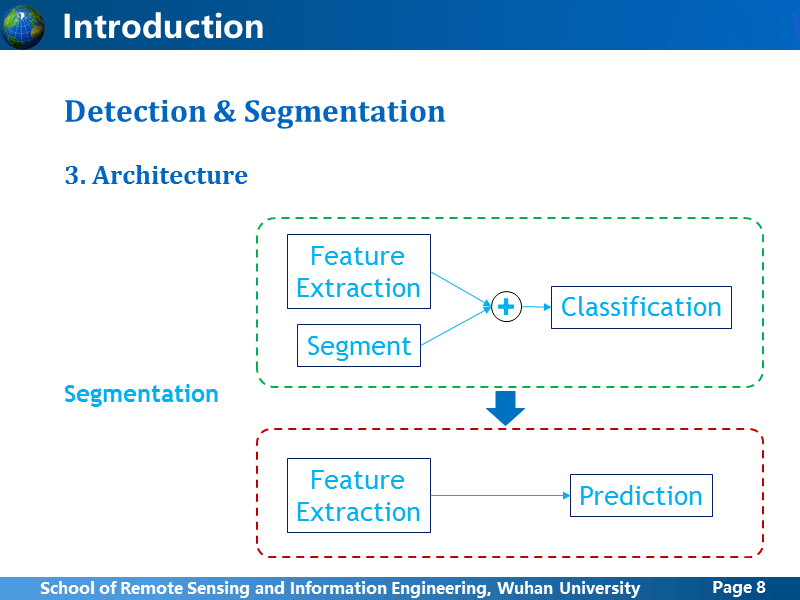
因为目标检测直接基于分类网络来做,所以相对发展走在前面,图像语义分割也受到目标检测的影响,早期思路与目标检测相似,就是先利用传统视觉的分割方法处理,得到patch级的分割结果,然后用CNN网络训练一个特征学习和分类器,把分割的patch进行分类,从而得到语义分割结果;目前的做法逐渐抛弃了这一思路,朝着直接使用卷积网络训练得到分割预测结果方向发展。总体而言,语义分割是比目标检测更加深层次的图像理解,我曾在一篇论文中看到,作者分析认为,语义分割是图像理解最为重要的方式,如此强调可以看出语义分割的重要价值。两者的对比先讲这么多,后面我展开讲几个语义分割网络。

我们可以把目前的语义分割网络,分为六大类,第一类是传统的图像分割方法,2000左右就开始被很多人关注和研究,第二种是一种过渡方法,提出的时间刚好是深度学习浪潮刚刚出现的时候,把传统方法分割方法+CNN结合,后面四类,都是直接基于卷积网络预测分割结果,只是网络结构上有差异,其实也可以分为一类,它们的出现已经是深度学习热潮近乎白热化的时期,从2013年到2016年三年左右的时间,发展非常迅猛,可以说是翻天覆地的变化,当然不止是语义分割还有很多其他计算机视觉领域都在经历着这样类似的变化。
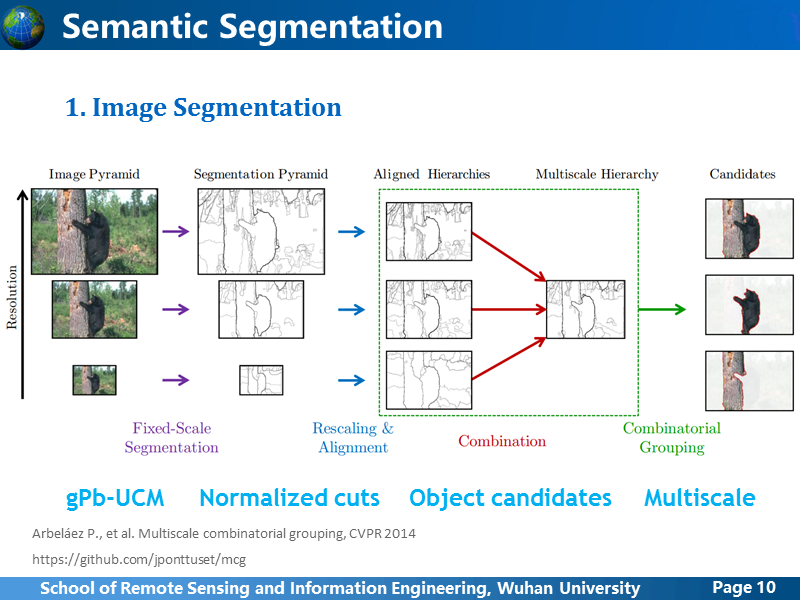
传统方法的巅峰之作,应该就算是MCG算法,集成了经典的contour detection方法gPb-UCM,加速了normalized cuts方法,改进了生成目标候选区的方法,而且还考虑了多尺度问题,性能上也没得说,但计算量有些大,在CPU下一张普通大小的图像要计算30~40秒,简化加速版本也要10s+。代码是开源的,可以下载测试,这里不再多做介绍。
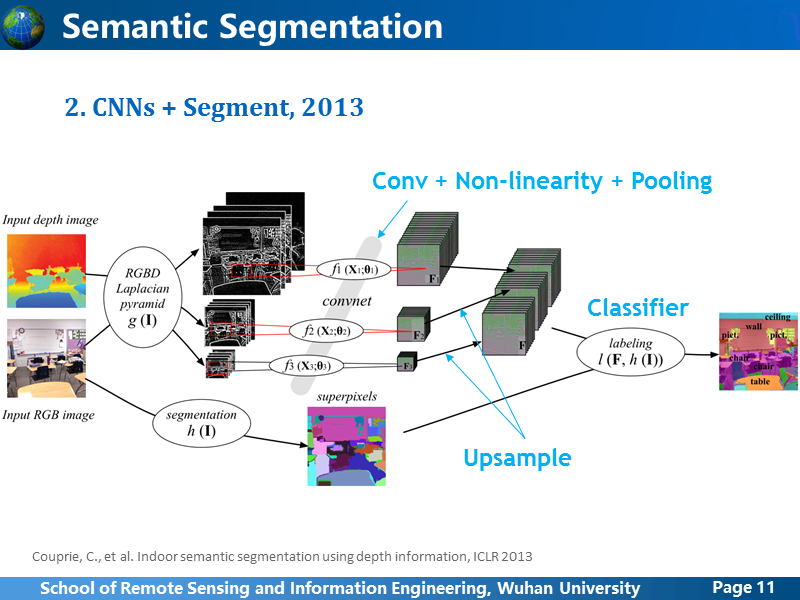
这是2013年LeCun他们进行的语义分割尝试,使用图像和深度图对室内场景进行语义分割,结构很简单,利用深度图和RGB图像先用不同尺度的拉普拉斯算子滤波,在不同尺度上进行卷积特征提取,然后将不同尺度上的特征图融合在一起,于此同时RGB图像上利用超像素分割,分类器利用学到的特征和预分割结果,对超像素的每个patch进行分类。

一方面,超像素分割并不稳定,小块物体或者单个物体中存在杂色时,分类存在很多错误;另一方面,弱边界区域,本身对超像素分割也是很难处理的,所以这种方法的效果一般,而且前面说了,毕竟这只是一种折中的过渡方法。

真正开启像素级语义分割网络的就是FCN,然后以它为基础,衍生出几个方法,这里列举几个方法:FCN本身,DeepLab, CRF-RNN,以及一个基于FCN网络的应用。
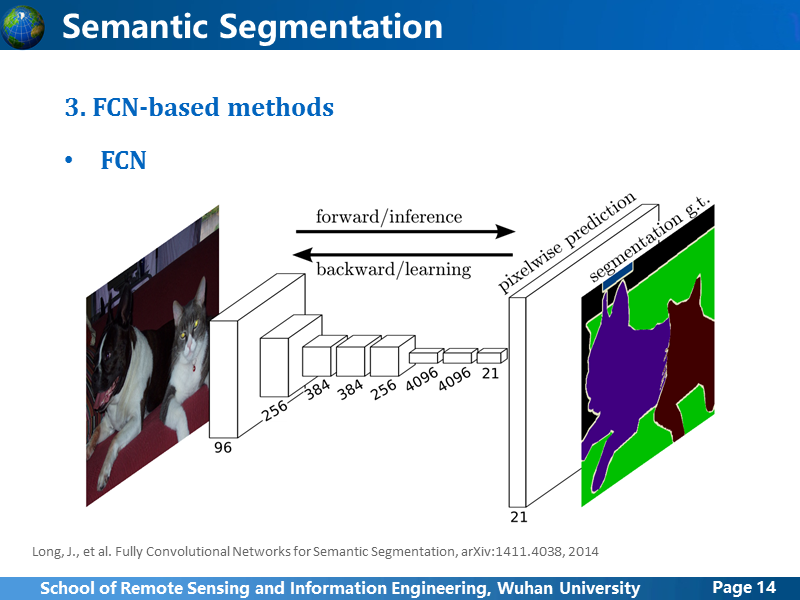
首先来看FCN,沿用了AlexNet卷积网络的结构,但是在全连接层的地方,为了能够生成图像的像素级预测,就扩大了卷积阶段和全连接层的plane size,最后全链接层的特征向量变成了特征图,由于最终的feature map比原图小,所以还需要进行上采样。
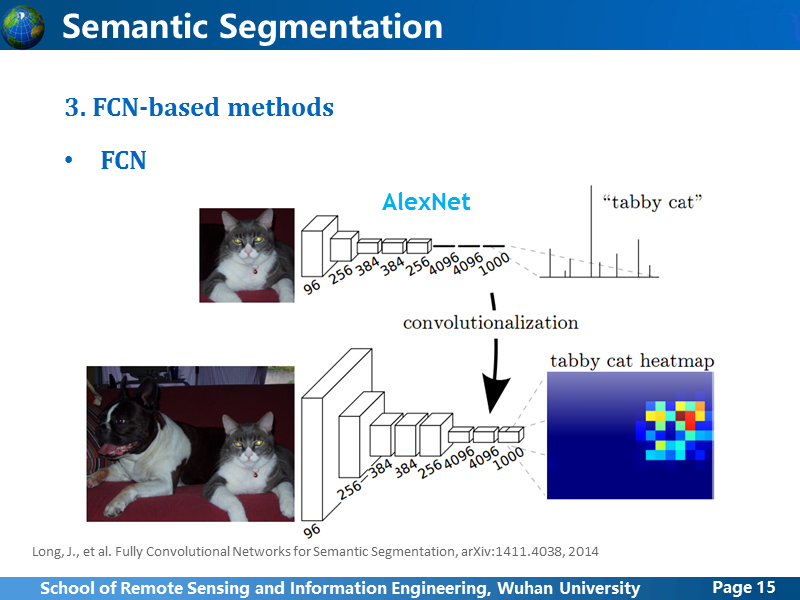
这张图更加清晰地说明的网络结构的变化,上面的就是AlexNet网络,下面是改变后的,首先为了使学习到的feature map更大,作者把训练输入的图像从224x224 扩大为500x500,全连接层输出的feature map的大小为10x10。
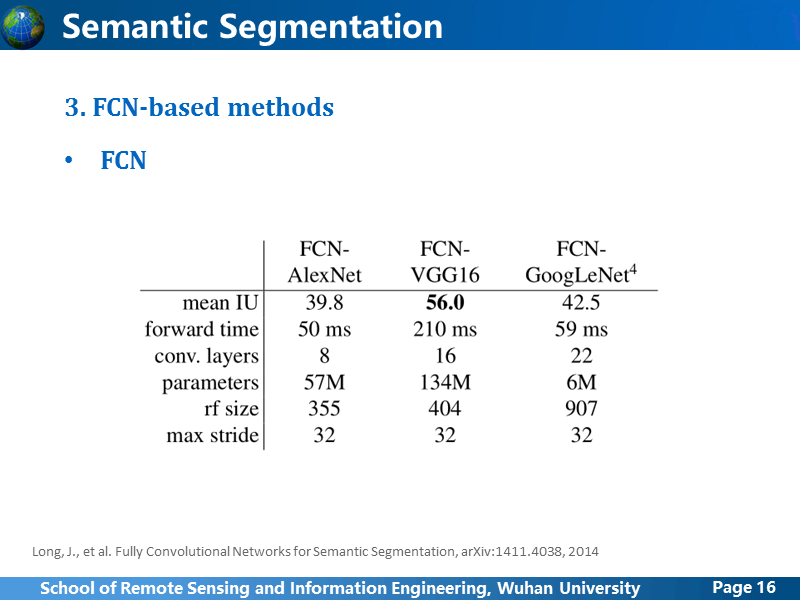
作者比较了AlexNet, VGG16, GoogLeNet的性能,在精度上来讲,VGG16最好,但是由于参数规模比较大,所以也比较耗时。
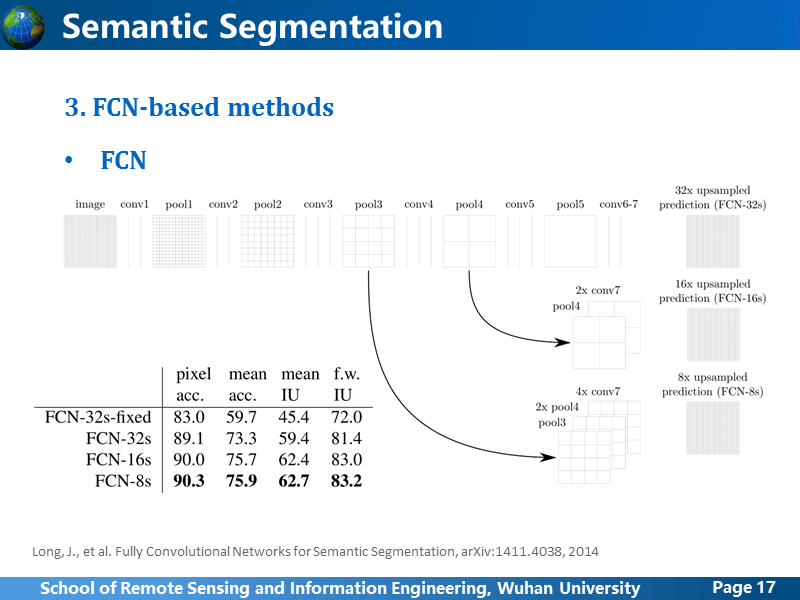
在卷积网络学习过程中,大家都知道,不同深度level的卷积学习到的特征抽象程度是不同的,浅层的学习到的都是局部特征,而随着卷积层深度增加,感受野也随之增大,学习到的特征更加抽象,作者测试了使用不同卷积阶段的feature map 生成分割结果,并进行对比,发现Pool3后得到的分割结果最佳,这很容易理解,太过浅层学习的feature 对局部变化比较敏感,也就是抗噪性能不佳,而更高层的学到的feature map对于局部变化不敏感,但很严重的缺点就是,梯度消失或者说边界模糊,也就是只能得到一个笼统的预测,但是很难获得准确的分割边界。
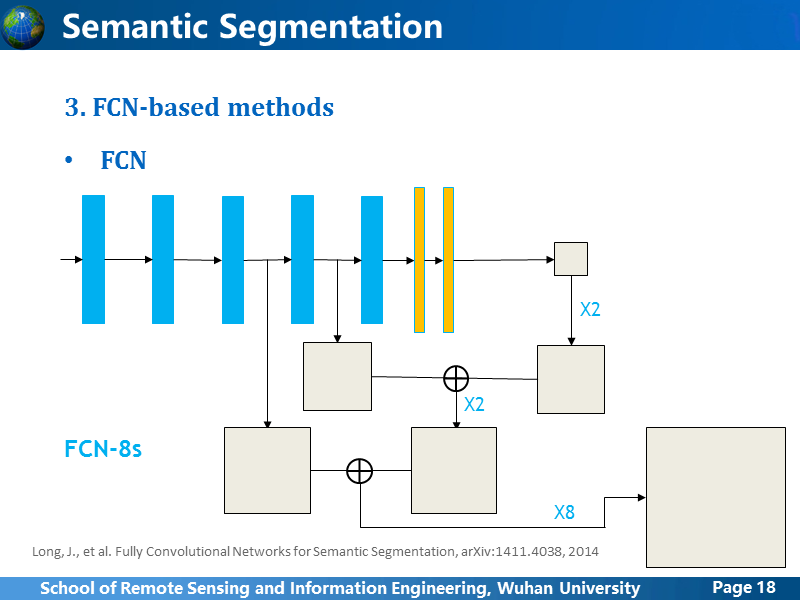
我简单画出FCN-8s的网络结构,作者也考虑了不同卷积阶段学习到特征的差异性,所以也进行了multi-stage的融合,方法就是图中画的那样,全连接输出的预测feature map上采样2倍后,跟pool4后的预测feature map叠加在一起,再上采样2倍,跟pool3后的预测feature map叠加在一起,最后整体上采样8倍,得到最终的预测结果。
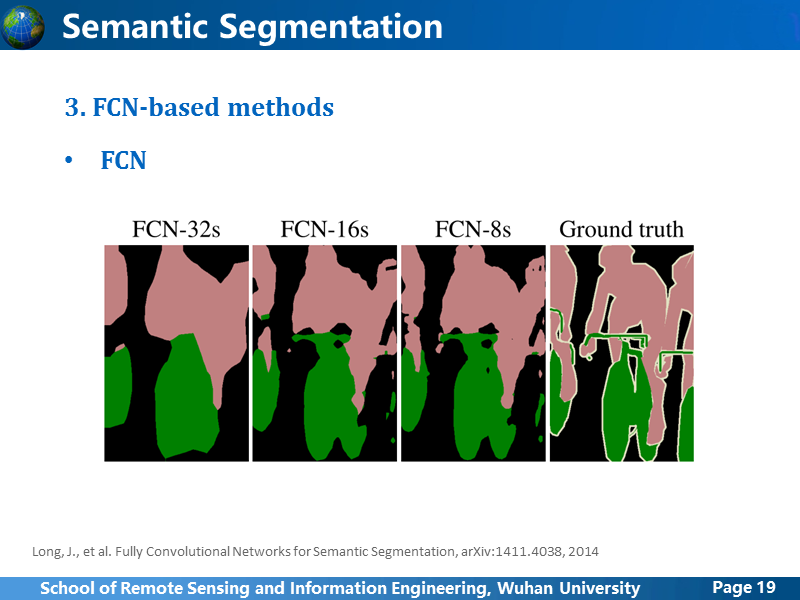
这是结果对比,验证刚刚我们的分析。
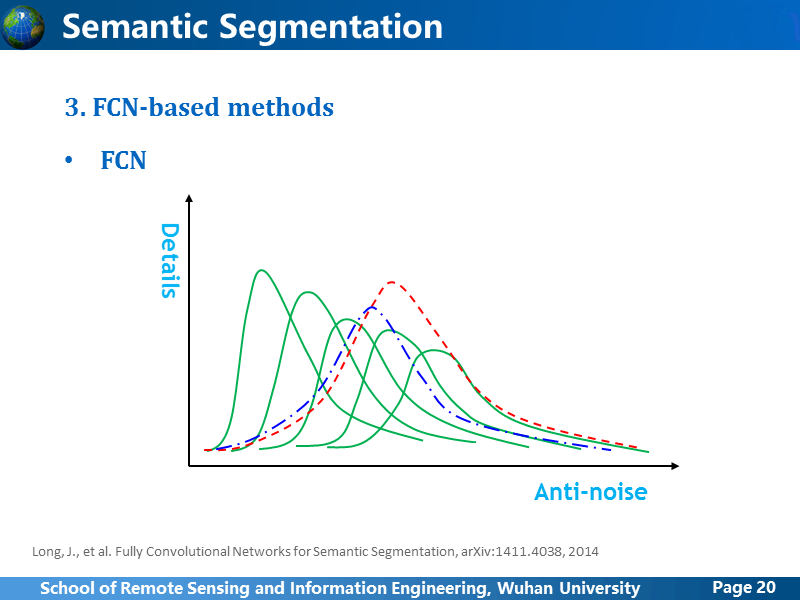
我按照自己的理解,画了一个简单的示意图,真实情况可能不是这样,但是差不多应该就是这样,横轴表示抗噪性能,竖轴表示表达结果的所能达到的细化程度,以VGG的五个卷积阶段为例,从左向右有5条实曲线,依次表示由浅到深各个卷积阶段学习的feature 对应的曲线,现在FCN依靠某一阶段或几个阶段的feature 学习得到的最佳结果是FCN-8s,也就是蓝色曲线,有所改善,但并没有达到理想结果,我们想要得到红色虚线那样的效果,可以做到吗?当然是可以的。
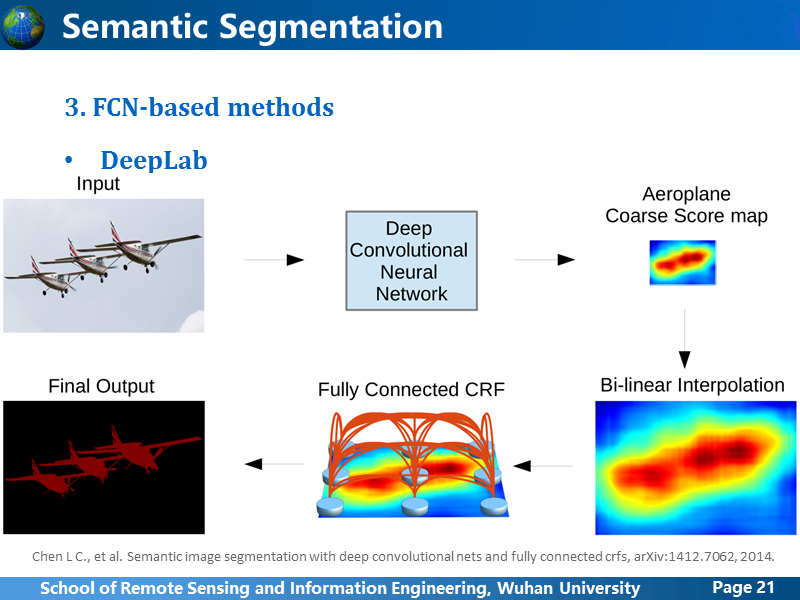
DeepLab的思路跟FCN基本一致,它是通过卷积,全连接后输出一个粗糙的,比原始图像小得多的预测图,然后把预测图上采样,然后使用条件随机场迭代优化,所以可以把DeepLab 理解成FCN+CRF。

第一张图示DeepLab不使用CRF优化与使用后的对比,第二张图是DeepLab使用CRF与FCN的对比,其实性能稍微提升了一些。
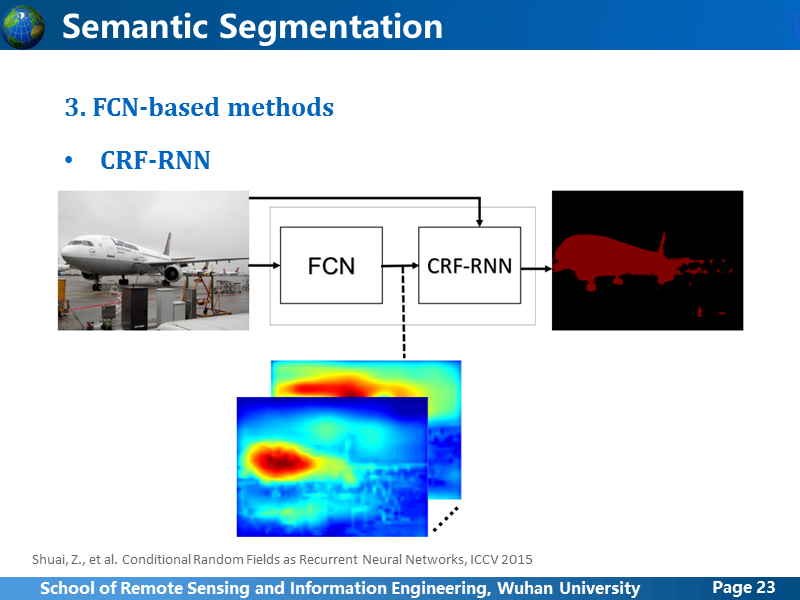
接下来讲CRF-RNN,这是他的原理图,同样是基于FCN的粗预测结果,进行优化,作者把DeepLab的CRF模块改成了CRF-RNN。
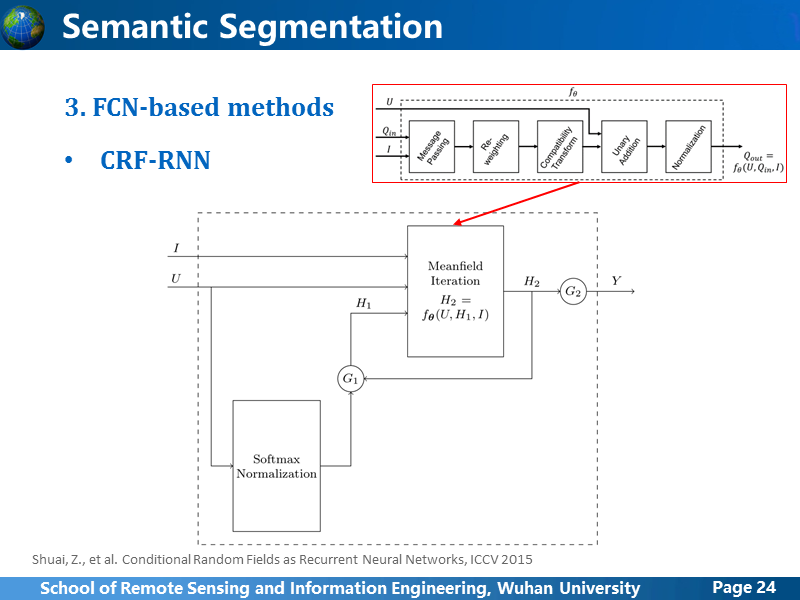
至于CRF-RNN的架构,我没看论文里讲的一大堆是什么,反正简单来讲就是一个优化过程,代码是开源的,我记得在某一篇论文里层讲过,所有的语义分割网络都可以进行CRF优化,这里就不多讲。

这是结果对比,确实效果好,更加精细化一些,作者在论文里说,训练的时候为了避免梯度消失问题,CRF-RNN迭代次数是5,而测试的时候是10,虽然论文里没有说inference time 但是肯定是只高不低。
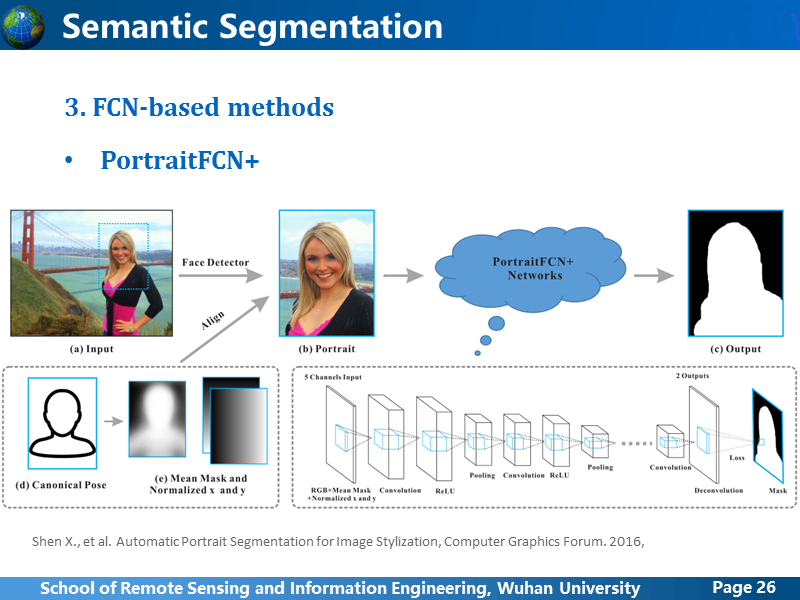
这篇PortriaitFCN+的论文是前段时间去上海参加RACV会议后,听到港中大贾佳亚教授他们组的研究,我就去他们团队网站上,瞄了一些他们的论文,感觉他们组的很多研究其实说不上很高深,更像是一个个tricks,很多方法都是基于现有的方法,稍加改造,然后加上一些不错的idea,就搞出成果,所以可能成果发表上比较快。他们的这篇主要是从图像上扣取人体的半身照,前面讲过FCN做这样的分割,结果是比较粗糙的,他们组没在网络上进行优化,而是在输入上,加上一些辅助信息,通过标准半身姿势模型,生成Mean Mask,也就是一个概率图,表示人体分布的概率,然后对每张图像计算与标准姿势的x和y方向的偏差,除此以为所有东西都是现成的,为了简单,实现起来更加容易,他们只做上半身,而且上半身区域的确定还是使用现成的人脸检测算子定位,如果mean mask和Graph-Cut 结合在一起,效果肯定也不会差。不过我觉得他们的想法还是很有趣,说以单独拿出来简单讲一下。
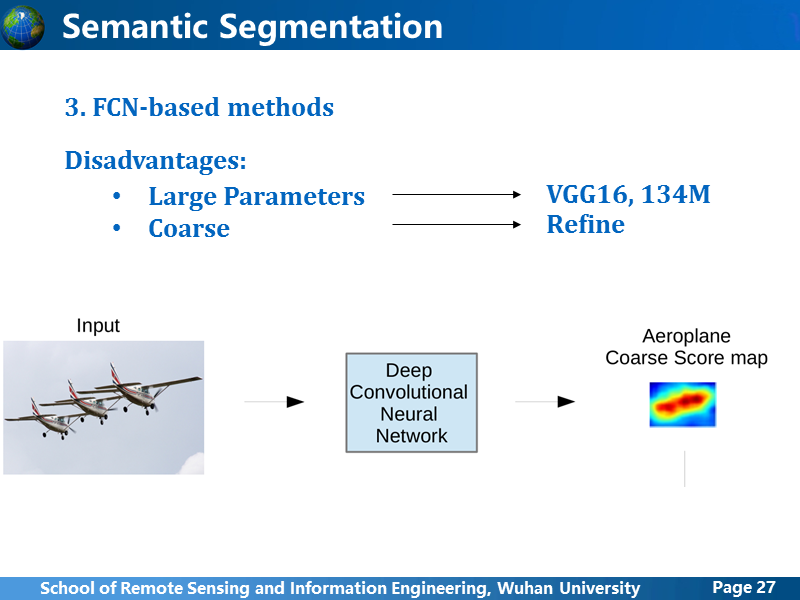
这里简单总结一下,基于FCN架构的方法,基本特点都是使用卷积学习网络全连接层的粗糙的feature map,上采样生成与原图一样大小的预测结果,这样的做法,很明显的弊端有两个:第一,因为扩大了卷积层和全连接层的plane size,使得网络参数规模巨大,VGG16框架下,参数规模为134M,这就导致计算量的增大;第二,受限于显卡内存和计算量的限制,在最大化扩大全连接层输出的plane size后,得到的feature map比原图小的太多,FCN里输入图像是500x500的分辨率,而全连接输出的feature map大小只有10x10,用这样粗糙的feature map上采样,很难得到很精细化的分割结果。DeepLab和CRF-RNN都是在围绕着如何把粗糙的预测结果精细化上进行研究,但是提升有限。

FCN的两大弊端,刚刚已经介绍了,之后,就有一些探索,首先就是Encoder-Decoder系列的,这种方法主要是围绕着,既然直接把全连接或者某一阶段的卷积feature map上采样可能过于简单,能不能换一种上采样方法?这里主要介绍四个网络。
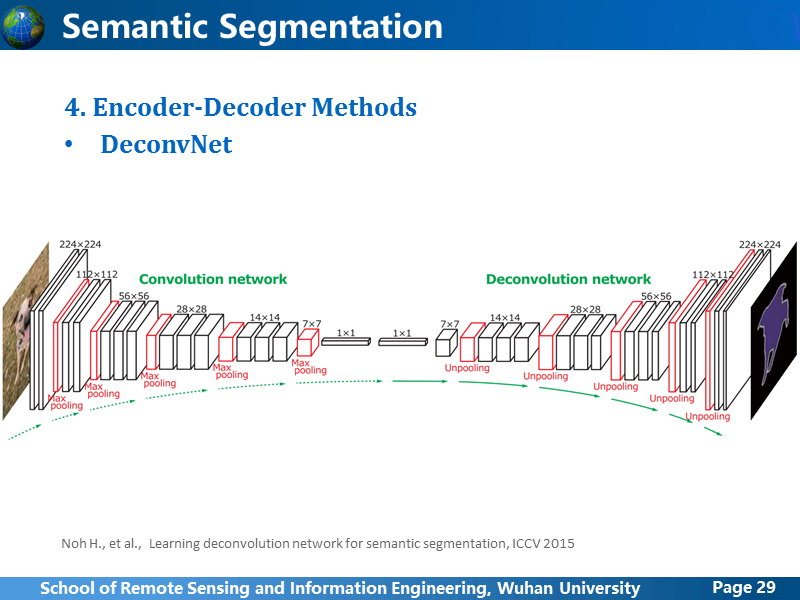
DeconvNet想到把粗糙的feature map上采样过程更新了策略,卷积阶段是一层一层进行下来,那把整个卷积过程镜像过来,就得到卷积阶段的整个逆过程,作者测试后发现可行,为了减少一些参数规模,作者就把全连接层缩减成一层,而且plane size也缩小,这就很有问题,前面提到FCN为了扩大全连接的feature map的plane size把输入图像的大小扩大,全连接输出也扩大,因此,DeconvNet的做法有些顾此失彼的感觉。而很明显的不足就是去卷积阶段其实利用的feature map仅仅是卷积阶段最后的feature map,没有从本质上解决之前FCN的问题。
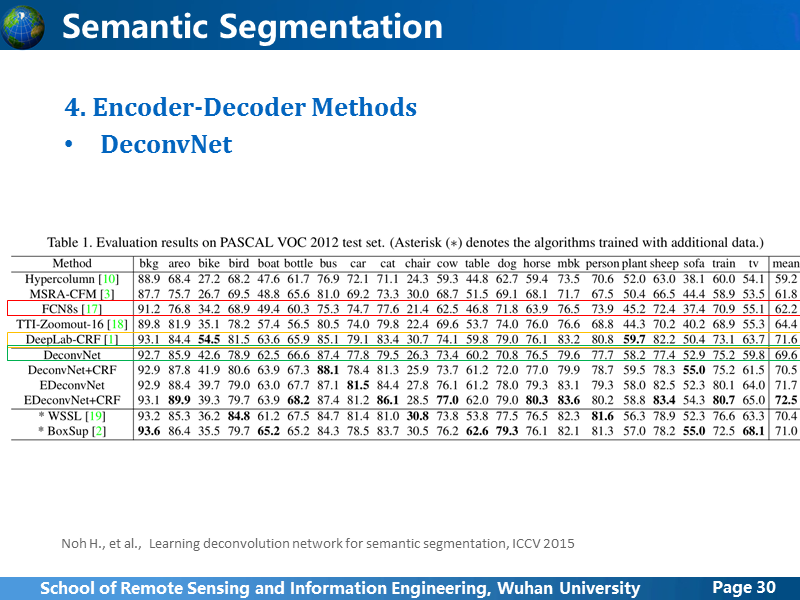
但是从结果上看,还是精度还是有所提升的,也就暗示着,这种上采样过程是可取的。
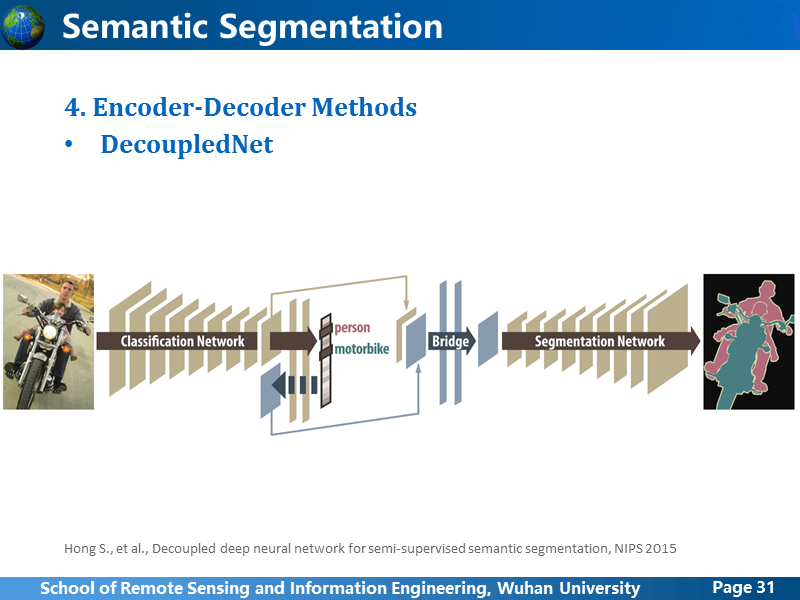
DecoupledNet有意模仿DeconvNet,在去卷积逆过程的时候,把卷积阶段和全连接都镜像过来,这样比DeconvNet存在的问题更大,原本FCN的结构网络参数就很大,这样double之后参数规模相当于扩大了2倍,DeconvNet应该是意识到了这样的问题,所以缩减了全连接层,而DecoupledNet却忽视这个问题,抱着试试看的心态去做,跟DeconvNet一样,去卷积阶段其实利用的feature map仅仅是卷积阶段最后的feature map,没有从本质上解决之前FCN的问题。不用想试验结果应该不是不如DeconvNet的。
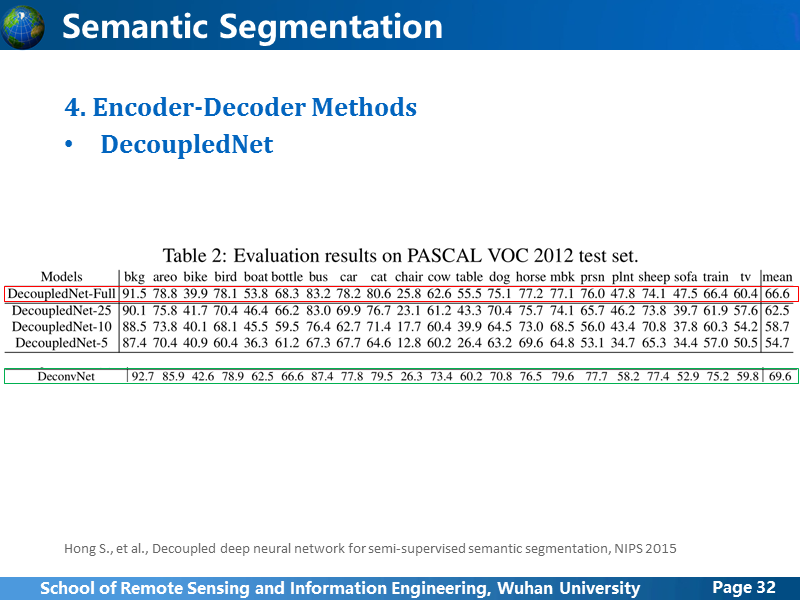
虽然作者没有列出跟其他方法的对比,但是相互参照其他论文,就可以看出,试验结果果然一般。
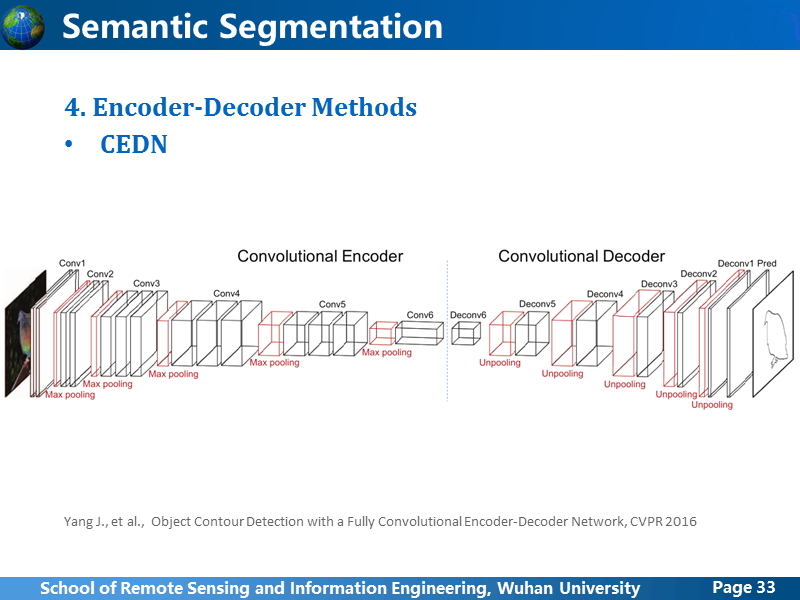
CEDN也是基于Encoder-Decoder的架构,但是有别于前面的语义分割,他想要做更加低级的contour detection,但使用的其实是语义分割网络。但是相比前面的两个网络,做了很多简化,首先全连接层去除掉,卷积之后直接就开始去卷积,而去卷积过程也并非是卷积阶段的完全镜像,也做了缩减。

这是作者论文里的效果图,第四列是CEDN的结果,最后一列是由contour 概率图+MCG方法的分割结果,效果还不错,但是前面已经介绍过,MCG最大的问题就是速度慢。
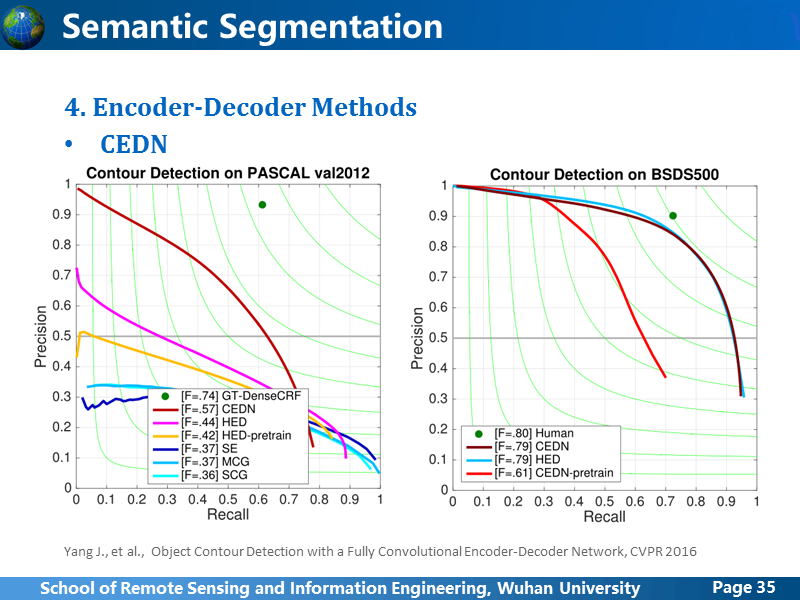
作者主要跟HED 边缘检测的方法进行了对比,从在VOC2012和BSDS500上分别进行了测试,HED的方法我后面也会简单介绍一下,这里的实验其实是有问题的,首先说一下HED-pretrain是指HED在BSDS500数据集上训练的结果,CEDN-pretrain是CEDN在VOC上训练的结果,从CEDN在两个数据集上的测试效果,可以看出,两个数据集之间的差异性还是很大。从BSDS500的实验结果来看,其实HED是要比CEDN好的,而且后面讲了HED的网络框架后,大家也会明白,在理论上HED肯定也是比CEDN要好一些的,作者在VOC上训练的时候,输入图像随机裁剪出几张224x224大小的图像,而HED原文中是resize成400x400,作者虽然没说在实验的时候HED采用的是crop还是resize,但是从结果来看,很有可能是resize,而且是resize成224x224,如果大家以后做图像像素级语义,千万要注意这个细节,如果能不对原始数据进行变换,那就尽量不要,不得已要转换,也要尽量采取影响最小的方法,如果CEDN的作者在使用HED在VOC上训练时,采用同样crop的方法或者保持HED原本resize的400x400的做法,HED的精度肯定是要比它高的,因此作者在VOC2012上比较的结果其实没什么意义,有故意拉低HED方法的嫌疑。
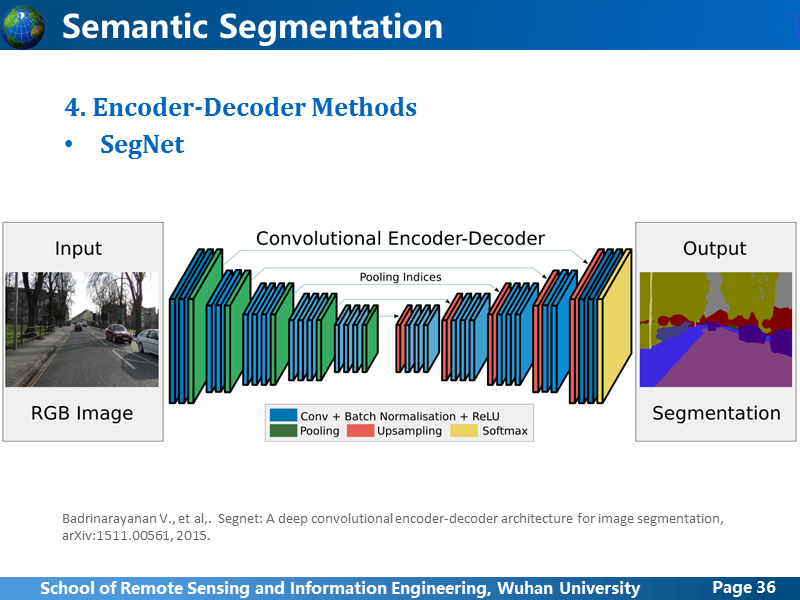
从前面的方法来看,Encoder-Decoder的演变趋势是,Encoder后的全连接或者卷积层逐渐简化到消失,SegNet就是这样一个简化版的网络,所有Encoder后紧跟着就开始Decoder。
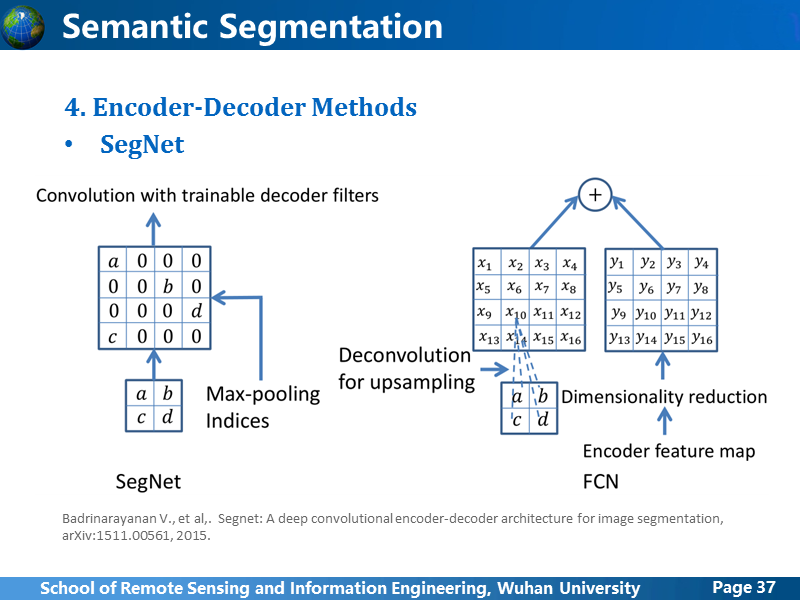
在上采样上,进行了新的尝试,之前的FCN网络上采样也提到过,使用深层的卷积feature map上采样后,跟卷积阶段对应大小的feature map叠加在一起,上采样操作是学习得到的,segNet使用一种叫Max-Pooling索引的方法,在encoder阶段,每个pooling层都输出两个pooling的feature map,一个输出到后面的卷积层,一个在用在decoder阶段的上采样,上采样的过程不是学习得到的。
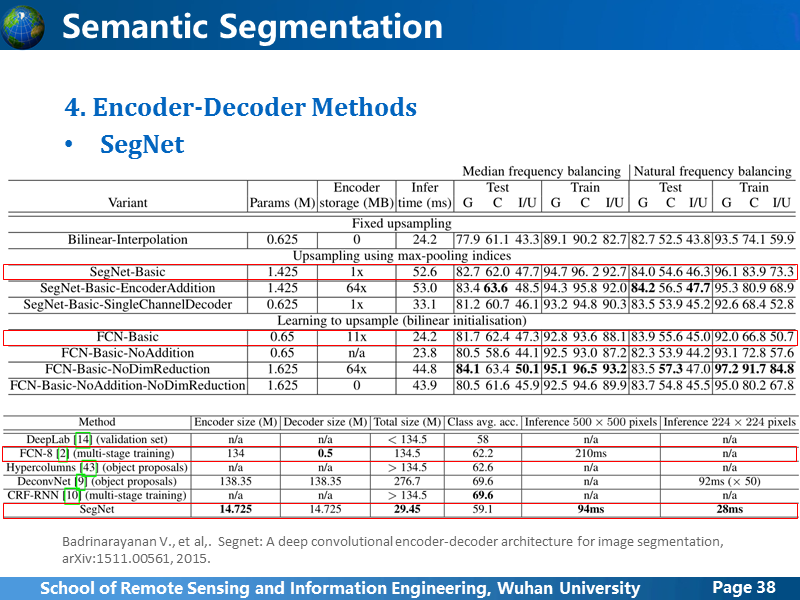
从结果上看,有精度有一点提升,不过文章里没说清楚,FCN方法前面已经讲过其实不是一个,大家引用的时候,一般都会指明使用的是FCN-8s,但是SegNet作者对比使用的FCN-Basic不清楚是FCN-8s还是FCN-32s,上面的测试结果是作者基于街景的小数据集,只有500多张样本11类,结果显示SegNet-Basic精度略高于FCN-Basic,下面的测试是基于VOC 2012数据集1000多张样本20类,FCN-8s略高于SegNet,我猜测,FCN-Basic指得应该是FCN-32s,总体来说,SegNet算是Encoder-Decoder方法种的最精简版,全连接层没有,上采样层参数也不通过学习得到,主要是为了减小网络参数规模,减小计算量,希望能够做到实时,效果还过得去。

这是SegNet的街景数据的分割结果。

尺度问题在传统视觉中一直都备受关注,在深度卷积网络中,梯度消失问题很棘手,小物体,微弱的目标,在深层卷积中一般很难保留下有效的特征,通过融合多尺度下的卷积特征是目前比较有效的解决办法,多尺度的方法总体来讲也有两个方向,第一种是,通过resize输入的训练数据,通过调整分辨率在多尺度上学习特征,然后再融合;第二种是,直接利用卷积不同阶段的feature,因为pooling过程的存在,使得不同阶段同样大小卷积窗口映射到原始图像上的感受野大小按照一定的比例指数型增长,因此卷积过程本身就有多尺度的feature,但是需要寻求一种策略强化某些有效的特征。MSCNN和HED就分别是这两种方法中的代表。

MSCNN的做法是,把卷积过程分成3路,控制每一路的输入图像大小,卷积核大小和pooling,使得3路在不同尺度上学习特征,最后把3路的feature 上采样到同样大小,然后融合得到最终结果。
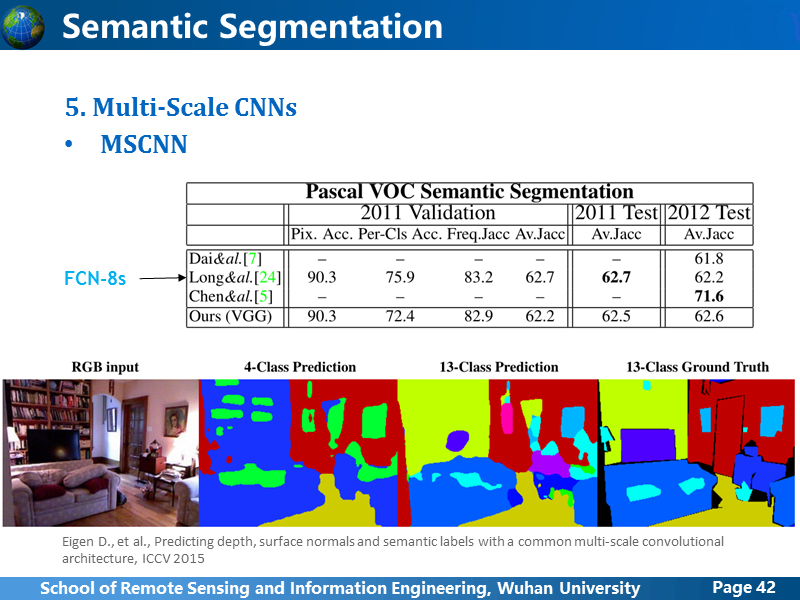
从统计精度上看,其实跟FCN-8s没多少区别,但是作者更多的贡献在于,提出了一种同时可以有效用于深度预测/表面法相估计和语义分割的通用网络,前面的网络,当然也能实现这些功能,但是毕竟没人做。
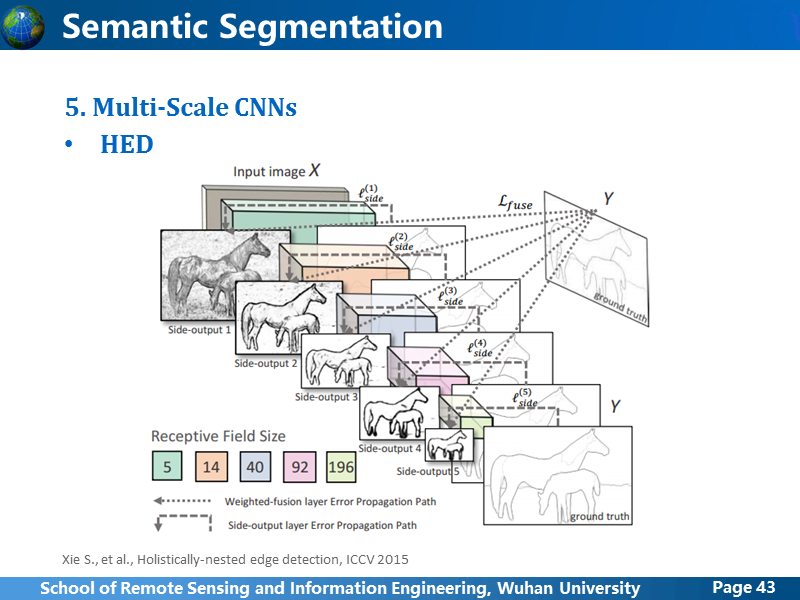
在讲CEDN的时候,就提到了HED网络。HED网络,也是用语义分割进行边缘检测,跟CEDN不同,它融合了各个卷积阶段的feature,并且通过统计各个卷积阶段的预测结果,进行整体监督,取得了边缘检测领域的最好成绩,这张图很形象,很容易理解,后面讲我们把这个网络应用在语义分割上时,会讲更多细节。
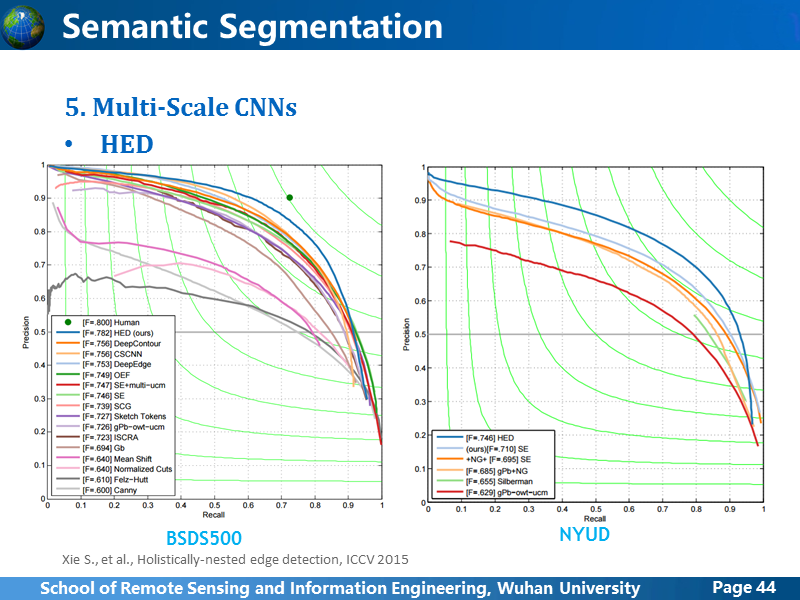
这是HED分别在BSDS500和NYUD上的跑分,发挥比较稳定,都是最好成绩。前面也分析了,CEDN在VOC2012上测的结果应该是拉低了HED的精度。

这两个篇论文都是FaceBook 的同一个研究员发表的,他的思路跟前面的方法最大的差异在于,前面我们讲的语义分割,是直接给图上的所有像素给出对应类别的label,而这个作者提出这种方法其实是出于提取目标proposal的目的,也就是说,重点在于生成Object的mask,并不是为了语义分割。
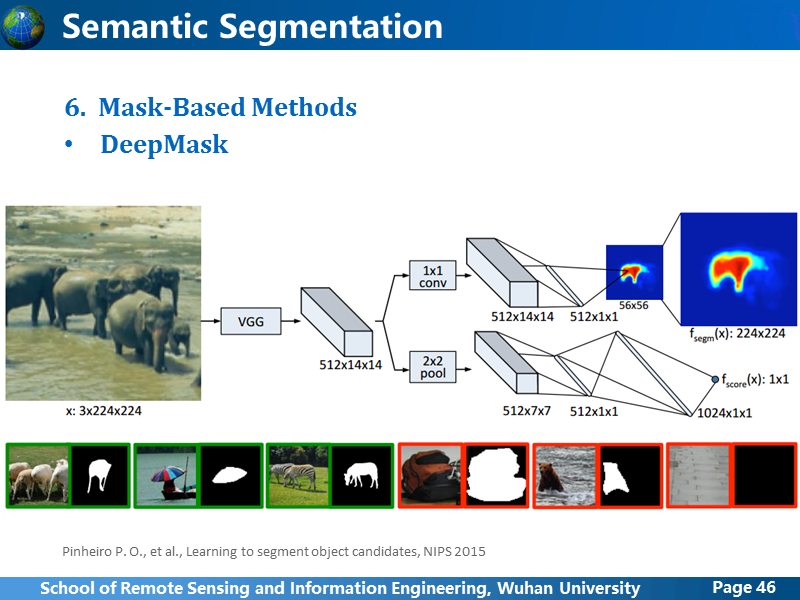
首先看DeepMask,应该算是该系列的第一个版本,卷积最后网络分成两个分支,一个用于生成分割mask,另一个用于预测这个patch中含有目标的可能性,从结构上看,就可以知道效果肯定是不如FCN-8s的,原因也就不讲了。另外,按照这个架构,输入整张图像,如果含有多个目标,要提取哪个目标?作者绕开这个问题,从输入的patch中生成分割mask,然后预测这个patch中含有目标的可能性。我感觉这种做法,没有太大的意义,使用语义分割生成整张图像的像素级label更有价值。
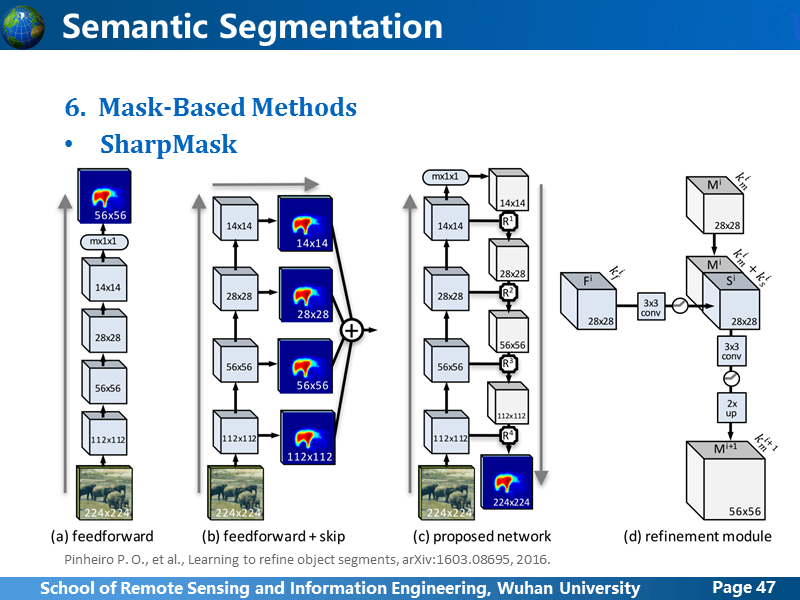
SharpMask,是在DeepMask的基础上完善,在逐级上采样过程中,融合各个卷积阶段的feature map,这种思路还不错,可以考虑用在语义分割中。

SharpMask 的测试结果。
后面部分的PPT略。