1.聚合操作Aggregation介绍
Aggregation简单来说,就是提供数据统计、分析、分类的方法,这与mapreduce有异曲同工之处,只不过mongodb做了更多的封装与优化,让数据操作更加便捷和易用。Aggregation操作,接收指定collection的数据集,通过计算后返回result数据;一个aggregation操作,从input源数据到output结果数据,中间会依次经过多个stages,整体而言就是一个pipeline;目前有10种stages,我们稍后介绍;它还提供了丰富的Expression(表达式)来辅助计算。
2.Aggregation 语法介绍
聚合管道是一个基于数据处理管道概念的框架。通过使用一个多阶段的管道,将一组文档转换为最终的聚合结果。
参考网站和小例子:https://blog.csdn.net/congcong68/article/details/51620040
db.collection.aggregate(pipeline, options);
pipeline Array
# 与mysql中的字段对比说明
$project # 返回哪些字段,select,说它像select其实是不太准确的,因为aggregate是一个阶段性管道操作符,$project是取出哪些数据进入下一个阶段管道操作,真正的最终数据返回还是在group等操作中;
$match # 放在group前相当于where使用,放在group后面相当于having使用
$sort # 排序1升-1降 sort一般放在group后,也就是说得到结果后再排序,如果先排序再分组没什么意义;
$limit # 相当于limit m,不能设置偏移量
$skip # 跳过第几个文档
$unwind # 把文档中的数组元素打开,并形成多个文档,参考Example1
$group: { _id: <expression>, <field1>: { <accumulator1> : <expression1> }, ... # 按什么字段分组,注意所有字段名前面都要加$,否则mongodb就为以为不加$的是普通常量,其中accumulator又包括以下几个操作符
# $sum,$avg,$first,$last,$max,$min,$push,$addToSet
#如果group by null就是 count(*)的效果
$geoNear # 取某一点的最近或最远,在LBS地理位置中有用
$out # 把结果写进新的集合中。注意1,不能写进一个分片集合中。注意2,不能写进3.使用MongoTemplate操作Aggregation
Aggregation agg = Aggregation.newAggregation(
Aggregation.match(criteria),//条件
Aggregation.group("a","b","c","d","e").count().as("f"),//分组字段
Aggregation.sort(sort),//排序
Aggregation.skip(page.getFirstResult()),//过滤
Aggregation.limit(pageSize)//页数
);
AggregationResults<Test> outputType=mongoTemplate.aggregate(agg,"test",Test.class);
List<Test> list=outputType.getMappedResults(); shell命令:
db.getCollection('test').aggregate( [
{ $match : { score : { $gt : 70, $lte : 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } },
{ $sort:a},
{ $skip:10},
{ $limit:10}
] ); 类似sql:
select a,b,c,count(1) from test where ... group by (...)
4.需求例子:
文档结构,如图:
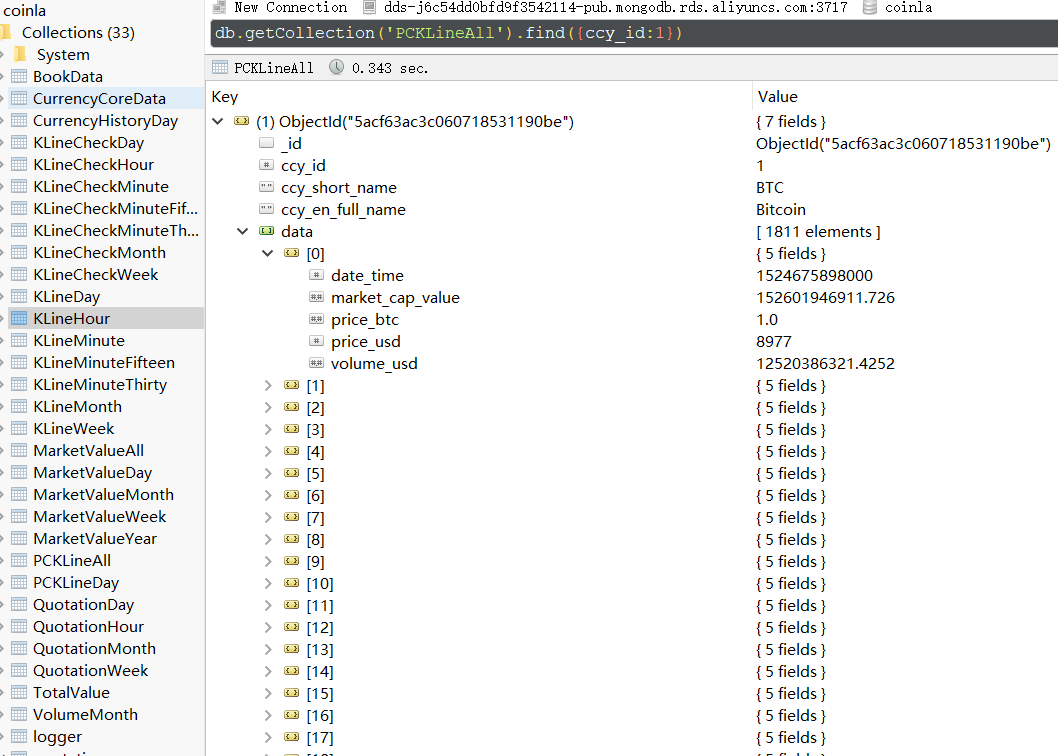
我要取文档ccy_id匹配1,并且嵌套文档的结果集的数量在40个
shell命令: 不使用聚合,使用$slice(正负数)

shell命令:使用聚合函数

在使用MongoTemplate操作的时候,我没有找到$slice的内置函数,我就只能使用聚合来查找了
Aggregation agg = Aggregation.newAggregation(
Aggregation.match(Criteria.where("ccy_id").is(1)),
Aggregation.unwind("data"),//将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
Aggregation.limit(40),//返回记录数
Aggregation.group("_id").push("data").as("data")//分组字段
/* Aggregation.sort(sort),//排序
Aggregation.skip(page.getFirstResult()),//过滤
//页数 */
); AggregationResults<XXX> results = this.mongoTemplate.aggregate(agg,"PCKLineAll",XXX.class);
List<XXX> list = results.getMappedResults(); List<XXX> list = results.getMappedResults();
ps:1.这样就能满足需求了,但是这里的条件可以使用in,使用后结果集就有问题
2.math放在unwind前面相当于where,放在unwind后相当于having
shell命令:使用聚合函数返回指定字段

Aggregation agg;
agg = Aggregation.newAggregation(
Aggregation.match(Criteria.where("type").is(0)),
Aggregation.group("_id").
first("user_id").as("user_id").
first("presentTotalProperty").as("presentTotalProperty").
first("bookList").as("bookList").
first("returnRate").as("returnRate")
).withOptions(Aggregation.newAggregationOptions().allowDiskUse(true).build());这种方式是来取只需要的字段,注意最后的withOptions(Aggregation.newAggregationOptions().allowDiskUse(true).build());是用来解除mongodb 查询数据默认占用最大内存的(默认100M).不然会抛出异常:
Exceeded memory limit for $group, but didn't allow external sort.
还有一种优化后的方式不采用聚合的方式:
DBObject dbObject = new BasicDBObject();
dbObject.put("type", 0); //查询条件
dbObject.put("presentTotalPropertySort", new BasicDBObject("$ne",0));
BasicDBObject fieldsObject=new BasicDBObject();
//指定返回的字段
fieldsObject.put("user_id", true);
fieldsObject.put("presentTotalProperty", true);
fieldsObject.put("returnRate", true);
//置顶返回内嵌文档的某个属性
/* fieldsObject.put("bookList.bookCurrencylist.currencyNumber", true);
fieldsObject.put("bookList.bookCurrencylist.currencyProperty", true); */
Query query = new BasicQuery(dbObject.toString(), fieldsObject.toString());
List<BookData> find = this.mongoTemplate.find(query, BookData.class);这里需要注意: 很多人不知道这几个对象的是哪个包下的,我标注出来:
com.mongodb.BasicDBObject.BasicDBObject()
org.springframework.data.mongodb.core.query.BasicQuery.BasicQuery(@Nullable String query, @Nullable String fields)
org.springframework.data.mongodb.core.query.Query
附带官方文档:https://docs.spring.io/spring-data/mongodb/docs/current/reference/html/#mongo.aggregation
参考网站:
https://blog.csdn.net/ruoguan_jishou/article/details/79289369(聚合操作示例)
https://blog.csdn.net/qq_33556185/article/details/53099085(聚合操作分页)
http://huangyongxing310.iteye.com/blog/2342307(超多示例)
https://www.cnblogs.com/nixi8/p/4856746.html(高级查询:聚合操作之基础)
http://shift-alt-ctrl.iteye.com/blog/2259216( Aggregation超级详细介绍)