神经网络本质上是利用线性变换加激活函数达到非线性变换的效果,从而将原始的输入空间特征投向稀疏可分的空间。最后去做分类或者回归。正是因为有激活函数,才使得神经网络有能力去模拟出任意一个函数。
本文简单介绍下常见的激活函数,以及它们各自的优缺点。
sigmoid
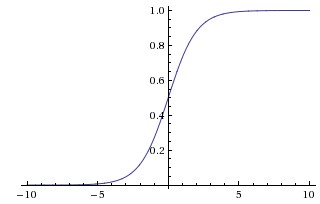
上图是sigmoid函数的图像,表达式为
图像上可以看出它把所有的实数映射到0和1之间,特别的是,小的负数很容易被映射到接近0,大的正数很容易被映射到接近1。映射后的值也就能自然而然地表示一个神经元被激活的概率。因此,人们常常把它用作激活函数。但是,实际应用时基本上要抛弃它了,原因总结有三点:
1.计算相对比较复杂。大量的神经元参与sigmoid函数计算时候很容易导致训练速度的降低,当然这不是主要原因
2.观测sigmoid图像,当输入在0附近时,函数的导数值比较大,往两边看,导数值几乎接近于0了。回忆BP算法时在更新权值 的时候, 的梯度里含有神经元输入的导函数的值。这样就很容易导致当输入值比较小或者比较大的时候, 的梯度接近于0了, 也就几乎停止了更新,这样的神经元就处于饱和状态。另外同样的道理,sigmoid对 的初始值比敏感,一旦初始值比较大时,大部分神经元就处于饱和状态了,神经网络学起来会很慢甚至效果很差。关于权值初始化可以戳这里
3.sigmoid还有个问题就是它的输出是0到1,都是正数。对应下一层的输入也就是正数,当一个神经元的输入固定为正数时,
的梯度也就固定为正数或者负数(这个取决于具体的梯度表达式),
就会如下图一样,锯齿式更新至收敛,训练很慢。
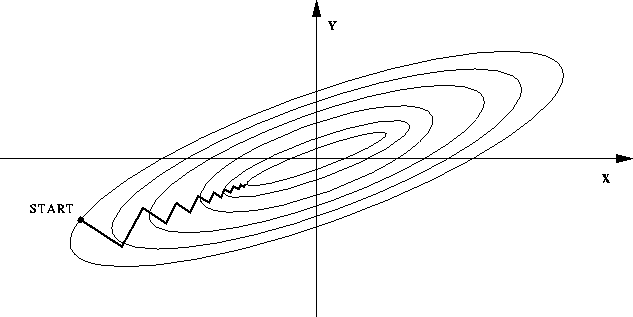
但是,因为我们通常是batch训练数据的,所以数据的梯度加起来更新,可以减缓这样的现象。相比第2点,这个缺点并不是那么严重。
Tanh
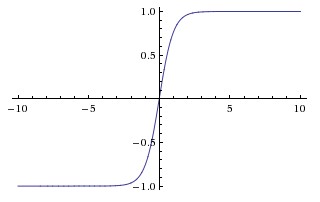
上图是tanh的函数图像。表达式为
图像上可以看出它把所有的实数映射到-1和1之间,相比sigmoid它同样面临sigmoid的第1,2个问题。但是它没有sigmoid的第3个问题。事实上tanh总是比sigmoid效果要好。
ReLU
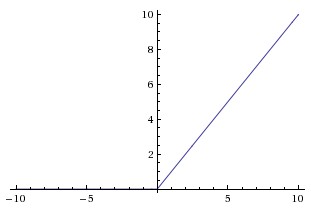
上图为ReLu的函数图像,它的函数表达式也十分简单:
先来看看ReLu有啥优点:
1.计算简单,只需要和0比较下。
2.实验证明相比其他两个激活函数,使用它梯度更大, 更新更快。这也源于它具有线性的特征。
缺点就是它使得神经元变得“脆弱“,很容易“挂掉“。例如,反向传播时计算了一个较大的梯度使得 变化很大,正向传播计算时发现神经元的输入值在小于0的区间,输出也为0,一旦发生这样的情况,下次反向计算梯度的值又为0,这样该神经元的对应的权值就不再更新了,对应的输出也就一直为0。可以看出这样的“挂掉“在训练过程中一旦发生就无法挽救。而且这样的现象在learning rate比较大的时候很容易发生,避免这种现象的一个方法就是调小learning rate。
总结
怎么选用激活函数呢?最简单的办法就是
1.隐藏层中彻底抛弃sigmoid吧,如果是二分类问题输出层就选择sigmoid,配合交叉熵损失函数
2.尝试用用tanh,但是通常情况下它比ReLU差。
3.首选ReLU,不过注意learning rate,以及监控神经元是不是还“活着“