为什么一开始就没想到呢?
我们设计程序逻辑时候,往往会按照顺序流的思想来设计。将自己的思路局限于需求里面。
常见的如下:
1.可能会按照需求提出的功能点来组织,也可能按照已有的模块来归来。
2.对功能的认知不够深入,哪些功能是独立的,哪些功能又是有相关性的。
这点很容易犯。往往由于进度时间压迫我们没有做深入的理解,从思考层次来说仅仅是达到解决问题的水平,并没有进一步做优化。如果你坚持程序是一件艺术品,不是一次就能雕琢出的理念,你应该继续打磨雕琢你的设计。
3.自己技术水平认知的局限。比如不懂设计模式要领。
4.现有程序结构的限制。
同样反过来看,当你积累这些经验的时候,那么是不是你的第一次设计就应该朝着这些方向靠拢呢。
为啥做了好多每次设计没有改善呢?
没有总结之前的设计经验!
设计和写作一样,需要大量的积累。而且积累的东西要随时想着应用到你的作品中去。光积累不用等于没有实践。
这样会导致深层次的设计奥义是无法领悟的。
因此设计的时候要积累灵感,后面还要学会去应用。
案例背景
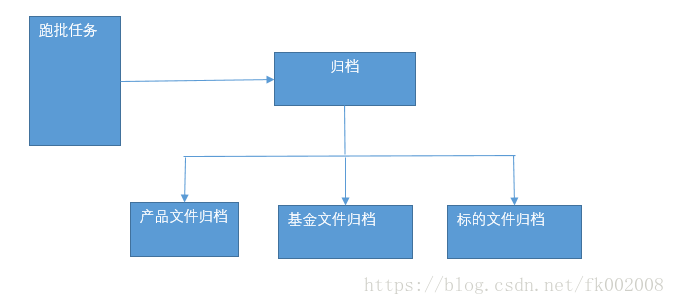
我们要做的一个任务就是归档。
系统中涉及到 产品,基金,标的 等一些实体概念。
每一个实体下面会有几种不同的文件,需要根据文件的一些特征,比如文件分类,上传时点,功能等进行标记
然后归档到对应的实体下面去。
最后页面可以通过一个树展示这些被归档的文件。
涉及到概念
产品下面会有多个基金
一个基金可以投资一个标的,多个基金可以投资一个相同的标的。
先有产品,然后衍生出基金,然后基金投资标的。
每一个种类的文件都会对应一个业务的绑定,bizId和bizType 进行记录。
但是,文件不一定直接和产品或基金关联,而是和产品下面的一个子业务关联起来。
如果这些子业务属于产品,就归档到产品上,是基金归档到基金上。
但是也有一些文件同时是产品的也是基金的,此时会归档到基金上,标的也是一样。
问题
现在需要根据一些固定的规则将这些文件 归档到产品,基金,标的上。
最终按照如下的规则展示:
产品记为 P ,基金记为F,标的记为 T
如果 存在 P->F ,那么展示树 P为父亲目录,F为孩子目录
P->F->T 同上,还要在F目录下增加一个 T的子目录
归档的文件作为叶子节点存储在上面的树形目录中
第一版串行的设计
从上面的概念和问题出发,我们自然得到如下的设计
将产品,基金,标的 三个概念分类,然后这三个类可以进行抽象
具体思路:
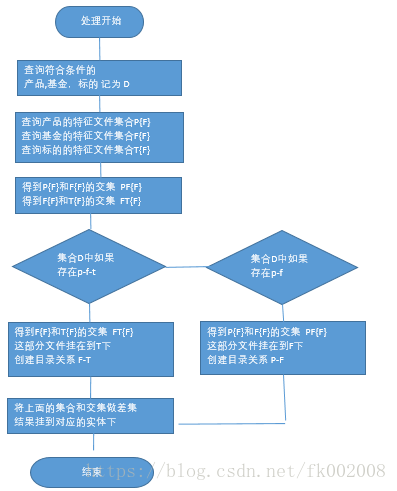
先查询出符合条件的产品,基金,标的
将查询结果作为一个结果集合
结果集合中的一行 包含了 P , F ,T 的信息
如果P-F不存在,那么F为空, 同样 T为空
然后根据这个结果集合查询符合特征的文件
将文件挂到对应的实体下面。
中间需要进行文件集合的交集运算,产品的文件集合和基金的文件集合交集
基金的文件集合和标的的文件集合进行交集运算
如果存在 P-> F,那么 第一个交集的文件挂在到 F下 ,同时创建树的目录关系,P-F
如果存在 F->T, 那么第二个交集的文件挂到 T下,同时创建树的目录关系,F-T
然后将剩下的文件集合和交集的差集挂到对应的实体目录上
设计的缺陷
这版设计可以完成任务
但是呢,各个任务之间必须串行。
在归档的过程中是 既有归档,也有树关系的创建。
因为我们查询了一次,想在一次使用查询出来 产品,基金,标的的结果集合既进行归档,也进行树关系创建。
如果文件的数量很大,那么这个串行的跑批任务时间就会很长的。
能进一步进行优化吗?
肯定是可以的
优化后的方案
其实呢,我们上面的设计完全被 产品,基金,标的这些概念给束缚住了,我们以这些为主体进行分块。
但是一个产品下面会有多个种类的文件,基金下面也是。
由于产品基金标的存在的关系让我们思维总局限于 这些关系的维护上面了。
其实呢我们目标任务就是归档,因此具体的目标应该是文件才对。
如果我们将文件进行分类,那么各个文件之间应该是相互独立的,这样各个独立文件的归档其实是可以并行的。
至于说 P-F , F-T这种关系,导致的文件的归档问题,
那么也可以将其看成为 文件的一种特征。
这样不同的文件之间是互不影响的,因此可以设计成并行的任务.
拆分出并行的任务
文件特征查询如下
只和产品关联的文件,查询结果记为 P{F}
只和基金关联的文件,查询结果记为 F{F}
只和标的关联的文件,查询结果记为 T{F}
查询和产品,基金都关联的文件,结果并入到 F{F}中
查新和基金,标的都关联的文件,结果并入到 T{F}中
然后可以对这些独立的文件进行归档。
因此我们可以使用一个接口来规范。
接口设计原则
一组相似操作,我们可以使用接口来规范行为。
因此我们可以做一个 ActiveTask接口
public interface ActiveTask{
List<FileModel> loadFile();
void executeActive(List<FileModel> list);
}功能剥离技巧
面向对象要求对象的功能要单一。因此功能的切割就很重要了。
本着功能单一的出发点,上面的设计中,归档和树的创建其实是两个功能的。
只不过我们想一次使用查询的产品,基金,标的数据结果将两件事情都给办了。
上面的树的创建其实依赖两个方面:
查询的产品,基金,标的数据结果:这个里面有关系
以及归档的结果:这个里面是标记了需要创建文件夹的产品,基金,标的。
结合第二个创建出文件夹目录,结合第一个创建文件夹之间的关系。
只要解决了结果的共用即可。
第二个好解决:只要将该树的创建人物放入到 上面所有的并行的归档任务之后即可
第一个呢?
再来一次循环?
临时表的使用
如果一个查询在多次使用到,而且循环中可能出现查询这种情况,我们可以考虑下临时表的使用。
如果将上面查询的产品,基金,标的数据结果 灌入到临时表里面,那么临时表就充当了一个共享的桥梁。
一个结果可以在多个不同的任务之间使用。而且不用给任务做输入值了。
并行任务的抽离特点
如果将一个串行任务改造成一个并行的任务,那么有几点要注意下:
各个任务有独立的特征
任务尽量不要对表进行更新,直接做插入即可。
如果有更新,可以转化为 插入的操作
例如上面的各个并行的归档任务,任务的结果会
创建归档结果,更新被归档的文件的状态为 已归档。(有得文件反复利用,不可以更新。)
那么这个更新其实可以转化为插入操作的。
我们如果将需要更新的文件id加入到一个临时表里面,等所有的并行任务结束之后,使用临时表关联文件表更新即可。
文件夹目录的创建
创建文件夹,我们根据归档的结果将归档结果中存储的实体信息创建文件夹目录。
这样做可以吗?
可以,但是不严谨。
因为可能出现极端情况,文件都和基金关联呢?标的也会有。
这样我们就可能出现文件夹目录的缺失。
有基金文件夹的时候肯定存在产品文件夹的。
因此需要进行目录的补全
目录的补全
我们可以倒着进行。
根据创建的标的的目录,我们使用标的的信息从我们的产品基金标的信息查询结果中可以得到
F-T的关系,这样我们将所有的F拿出,从而可以补全 基金的目录。
同样我们可以补全产品的目录。
树的创建
这个也可以倒着来。
根据
根据创建的标的的目录,我们使用标的的信息从我们的产品基金标的信息查询结果中可以得到
F-T的关系,然后创建 F-T的关系
同样创建P-F的关系
然后就可以将归档结果的文件挂载到创建的对应目录上
总结
设计不是一蹴而就的。需要进行反复的雕琢。
每次设计都要总结下自己的设计经验和设计灵感。
应用到下一次的设计中去。