机器学习入门系列以本文为主导线,中间穿插着其他概念与网址
机器学习概述
定义
机器学习是一种在没有具体编程的情况下教计算机学习的能力。例如,机器学习通常被用来训练计算机来执行一些难以用编程手段来完成的任务。
学习过程
一般来说,无论是人还是机器学习过程大致都分为以下四个步骤:
a) 数据累积(data storage):使用观察、记忆和联想的方法来为进一步的推理提供事实依据;
b) 抽象思维(Abstraction):将存储的数据转换为更广泛的表示和概念;
c) 理论概括(Generalization):使用抽象化的数据来创建在新环境下采取进一步动作的知识和推论;
d) 评估过程(Evaluation):为学习过程提供反馈机制以衡量所学知识的实用性并带来潜在的效果提升;

种类
机器学习种类有:监督学习(supervised Learning)、强化学习(reinforcement learning)、非监督学习(unsupervised learning),如下图3-1。
a) 监督学习是最常见的一种机器学习,它的训练数据是有标签的,训练目标是能够给新数据(测试数据)以正确的标签。例如,将邮件进行是否垃圾邮件的分类,一开始我们先将一些邮件及其标签(垃圾邮件或非垃圾邮件)一起进行训练,学习模型不断捕捉这些邮件与标签间的联系进行自我调整和完善,然后我们给一些不带标签的新邮件,让该模型对新邮件进行是否是垃圾邮件的分类。
b) 非监督学习常常被用于数据挖掘,用于在大量无标签数据中发现些什么她的训练数据是无标签的,训练目标是能对观察值进行分类或者区分等。例如非监督学习应该能在不给任何额外提示的情况下,仅依据所有“花”的图片的特征,将“花”的图片从大量的各种各样的图片中将区分出来。
c) 强化学习通常被用在机器人技术上(例如机械狗),它接收机器人当前状态,算法的目标是训练机器来做出各种特定行为。工作流程多是:机器被放置在一个特定环境中,在这个环境里机器可以持续性地进行自我训练,而环境会给出或正或负的反馈。机器会从以往的行动经验中得到提升并最终找到最好的知识内容来帮助它做出最有效的行为决策。
机器学习分类

主要应用
a) 手写识别(handwriting recognition):它可以识别手写文字,这样就可以将手写文字直接转变为数字文字。
b) 语言转换(language translation):对口语或书面文字进行翻译。
c) 语音识别(speech recognition):识别语音并将语音片段转换成文本。
d) 图片分类(image classification):将图片进行合适的分类。
e) 自主驾驶(autonomous driving):使车能自己行驶。
特征
特征是用来形成预测或者模型的观察值。例如,在图片分类中,像素点就是特征;在语音识别中,声音的音调和音量就是特征;在自主汽车中,来自摄像机、距离传感器和GPU中的数据就是特征。
对于建立一个模型来说,提取有意义的特征是非常重要。例如,在分类图片时,当天时间就是无意义的特征,而在分类垃圾邮件时,当天时间就是非常有用的信息,因为垃圾邮件一般是在夜间发送的。
机器人中常见的特征类型:像素点(RGB数据)、深度数据(声纳或激光测距仪)、运动(编码器值)、方位选择或者加速(回转仪、加速器或罗盘)。
注:在大多数情况下,有越多的可用特征越好,虽然这可能更耗时;激光距离仪很贵,但它产生的特征(360 degree depth maps)对导航是很有用的;摄像机是便宜的,来自摄像机的深度数据处理是很耗费计算资源的。
分类正确度测定
分类正确度测定:true positive、true negative、false positive、false negative。具体含义如图1示:

图1:识别猫的测试结果
常用的度量有三种:precision、recall和accuracy。其中 # 表示数目,Precision=(#true positives)/(#true positives+ #false positives),
Recall=(#true positives)/(#true positive + #false negatives),
Accuracy=(# true positives + # true negatives)/(# of samples),
在信息检索领域,精确率(precision)和召回率(recall)又被称为:查准率和查重率。
其他机器学习算法测评指标:top3和top5的错误率:指正确label不在model预测的前三个或前五个答案当中。再解释一下,“top1正确”就是你预测的label取最后概率向量里面最大的那一个作为预测结果,你的预测结果中概率最大的那个类必须是正确类别才算预测正确。而“top5正确”就是最后概率向量最大的前五名中出现了正确概率即为预测正确。
这个指标的意义是:“ImageNet数据集Label有一定的误差,很多图片人类看来可以归为好几个类,所以就用top-x当一个重要的评测标准”
训练数据和测试数据
a) 训练数据:训练数据是用来学习模型的。训练数据的质量对生成一个成功的机器学习模型来说至关重要,理想的训练数据应该是多样化并尽可能与模型需要用到的特性相关的。
b) 测试数据:被用来对生成的模型的准确度进行评估的数据。测试数据不能用来训练模型。
c) 过拟合(overfitting):模型在训练数据上运行的很好但在测试数据上表现糟糕。也就是泛化性能不好,如果太追求在训练集上的完美而采用一个很复杂的模型,会使得模型把训练集里面的噪声都当成了真实的数据分布特征,从而得到错误的数据分布估计。过拟合可以通过正则化或交叉验证技术来避免。
d) 欠拟合(underfitting):训练样本太少,导致模型就不足以刻画数据分布了,体现为连在训练集上的错误率都很高的现象。
偏差(bias)和方差(variance)
a) 偏差:模型预测值与真实值间的预期差值。即模型本身的精准度,即算法本身的拟合能力。该值是模型预测值和真实值间差值的平均值,偏差越大,越偏离真实数据。
b) 方差:在该训练集中模型预测值的差值有多大。该值是表示模型预测值的离散程度,依赖于它的训练数据。方差越大,数据的分布越分散。
模型可能的情景
a) 高偏差:模型在训练数据上的预测值不准确,欠拟合会出现高偏差问题;
b) 高方差:模型在新数据集(例如测试数据)上的普适性不好,过拟合会出现高方差问题;
c) 低偏差:模型在训练数据上能准确预测;
d) 低方差:模型对新数据集的普适性较好;
注:偏差与方差通常是负相关的(如图3示),实际中我们要找方差和偏差都较小的点。

方差与偏差(红心表示真实值,蓝点表示预测值)
方差与偏差模型
机器学习算法
a) 监督学习(构建预测模型):
- 分类(classification):这种算法使用训练数据(训练数据中包含特征以及分类标签)来构建预测模型。这些预测模型可以使用它从训练数据中所挖掘出来的特征来对新的、未曾见过的数据集进行分类标签预测,而这种最终的分类结果是相互分离的。常用分类算法:逻辑回归、决策树、KNN、随机森林、支持向量机、朴素贝叶斯等
- 回归(regression):这种算法使用从输入数据中获得的特征参数来预测一些额外的特征,为了完成这一工作,算法会建立一个基于数据特征的模型,这个模型可以针对训练数据给出一些未知的特征,也可以用来预测新数据集的特征属性。这里输出的特征属性是连续的且互不分离的。常见的回归算法:线性回归、KNN、Gradient Boosting & AdaBoost等
b) 无监督学习(构建描述模型):
- 聚类(clustering):这类算法的主要目标是对输入数据进行归类,并将其划分为若干个不同的层级或是类别。算法中这一过程仅仅使用了输入数据中挖掘出来的特征而没有使用任何其他信息。与分类不同的是,聚类中输出数据的各个类别标签我们是无法获知的。常见的聚类算法包括k-means、k-medoids和层次聚类。
- 关联(模式挖掘)(association):这类算法主要用来从数据集中挖掘和抽取规则和模式。这里的规则阐述了数据中不同参数和属性之间的联系,同时也描画了数据中会经常出现的元素集和模式规律。这些规则和规律可以反过来帮助我们从企业机构的海量数据仓库中发现有意义的内容。常见的这类算法包括Apriori和FP Growth。
c) 半监督学习(使用「标签化」和「无标签」的混合数据):
- 分类
- 聚类
d) 增强学习:
- 分类
- 自动控制(control)
e) 神经网络(不好直接归在哪一类里,单拿出来说)
f) 推荐算法(不好直接归在哪一类里,单拿出来说)
机器学习种类
监督和非监督的学习算法细分(因为这两种是最常见的)
监督学习框架
Tool Uses Language
Scikit-Learn Classification, Regression, Clustering Python
Spark MLlib Classification, Regression, Clustering Scala, R, Java
Weka Classification, Regression, Clustering Java
Caffe Neural Networks C++, Python
TensorFlow Neural Networks Python
作者:七月在线
链接:https://zhuanlan.zhihu.com/p/31831309
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
神经网络(有些东西后面会细讲,先在这里说明一下概念和用处)
a) 生物启发:神经网络是受到大脑对信息的存储和处理方式的启发,大脑的核心组件是神经元,每一个神经元可以通过它的轴突接收来自其他神经元的信息,然后再由该神经元的树突将信息发送给其它神经元,各个神经元之间可是通过突触连接的。
b) 神经网络架构(如图4):包含输入层(蓝色)、隐藏层(绿色)和输出层(紫色)。每一层中的神经元接收来自上一层中的神经元的信息,每一个神经元都使用一个函数来处理它的输入并得到一个输出,然后将该输出发送给下一层的神经元。
c) 激活函数:激活函数被用于每个神经元,激活函数处理神经元的输入并得到输出。最常见的激活函数有sigmoid和Relu,激活函数一般是非线性的。
d) 推理过程:当模型学习好之后,我们如何使用模型对新数据进行推理,以图4为例,蓝色表示输入数据(输入层),绿色是隐藏层,紫色是输出层,输入层与隐藏层的权重用Hi weight表示(i代表神经元),同理,隐藏层与输出层间的权重用Oi weight表示。那么我们可以通过图6中的式子分别得到隐藏层和输出层的值(其中S表示应用于神经元上的激活函数,此处是sigmoid函数:


上图是该函数的图形表示,最终结果如图7示。可见最终得到了.35和.85,如果这是一个分类神经网络,那么我们最终可能会选择输出层的第二个神经元上的标签来对该输入值进行分类。

图4:神经网络架构

图5:层间权重值

图6:隐藏层的计算过程,上面的式子可以套用sigmoid公式进行计算。".13"代表0.13,后面的都省去了0.

图7:神经网络推理过程
e) 矩阵公式:上面输入层到隐藏层的三个计算公式都可以被表示为图8中的矩阵计算。矩阵计算相比上面的计算方式更适合计算机操作,可以极大增强计算并行性。同时GPU因为极好的矩阵计算能力,而被用来为神经网络训练和推理过程加速。

图8:输入层到隐藏层的计算
f) 训练神经网络步骤:
- 在训练数据集上执行推理过程;
- 计算预测值和训练集真实标签间的误差;
- 确定每个神经元上的误差(利用ii中的误差进行反向传播(back propagation)来计算得到具体每个神经元上的误差);
- 修改神经网络权重来减小误差(通过梯度下降法实现误差减小https://www.jianshu.com/p/c7e642877b0e)。
注:神经网络的初始权重是通过随机分配得到的。
g) 反向传播:求误差与要更新的权重的偏导值,该值即为要更新的误差(数学直观来说,偏导即为一个函数在给定变量所在维度,当前点附近的一个变化率。)。
h) 梯度下降:梯度下降可以用来减小神经网络的错误,梯度下降在预测值错误很小或者迭代次数已达最大值时结束。每次迭代都要在训练数据上通过最终的预测差值来计算每个权重差值,然后修改权重来减小最终误差。
关于梯度下降,可以看这篇博文,讲得十分通俗易懂: https://www.jianshu.com/p/c7e642877b0e

上面这个图,讲的是梯度下降的部分原理,看懂上面的博文,就十分简单名了。
i) 最大池化层:因为卷积层产生了大量的输出值,所以简化输出值是非常必要的。最大池化层是从一组数据组提取最大值。
基于梯度的有监督的学习算法(神经网络和许多其他模型)的几个重要函数
a) 判决规则(decision rule):y = F(W,X),表示深度学习的预测值推导过程,即向前传播。式中W表示层间连接的权重值矩阵,X则表示该层的输入向量,函数F()则是激活函数,例如sigmoid函数。神经网络的每一层都经过这样的一个判决过程,最终得到预测值即预计结果。
b) 损失函数(loss function):

表示预测值与实际值(标签)之间的距离或者差异,函数D(y,f),表示某种评估实际值y与预测值f间的差异的方式。
c) 损失梯度(gradient of loss):

,该过程是基于损失函数得到的最终误差来计算每个权重值对这个误差的贡献,即通过最终误差来计算每个小误差的过程,也可以叫反向传播(具体看下条)。
d) 更新规则(update rule):

该过程是将上面计算的每个权重值上的误差用来更新,以得到新的、更为精确的权重值。上式中η(t)是学习率。
e) 直接解决方案:正规方程(normal equation):不使用迭代方式,直接计算最优值。
反向传播
第一条(神经网络-d)中的推理过程即是一个完整的向前传播过程,通过向前传播,我们得到输出值[.35, .85],与实际值[.01, .99]还相差很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
a) 计算总误差:(总误差 square error)均差方法计算。

因为本例中有两个输出,所以分别计算O1和O2的误差,总误差为两者之和:

b) 隐藏层到输出层的权重更新。
为了便于描述,我们将H1、H2、H3与O1间的权重分别称为w4、w5、w6,并查看w5对整体误差产生了多少影响,具体公式如下(链式法则:利用整体误差对w5求偏导):

其中,out01表示最终结果0.35,net01表示没有进行sigmoid函数之前的结果-0.63,w5是1.0。可以看出我们是按照向前传播的顺序一点一点反向偏导得出具体权重误差,下面我们以w5权重更新为例,具体走一下。
1.计算
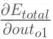

所以

2.计算


所以

= 0.34751053(1-0.34751053)=0.22674696;
3.计算


4.三者相乘


= 0.34 * 0.22674696 * 0.96 =0.07401020,
该值即为整体误差对w5的偏导值;
5.最后我们来更新w5的值:

= 1.0 - 0.5*0.07401020 = 0.96299489 (其中,η是学习率,此处取0.5)
回归问题
一个预测问题在回归模型下进行解决。回归模型回归模型定义了输入与输出的关系,输入即现有知识,而输出则为预测。一个预测问题在回归模型下解决的步骤:
a) 积累知识:我们将储备的知识称之为训练集 Training Set;
b) 学习:学习如何预测,得到输入与输出的关系。在学习阶段,应当有合适的指导方针,这个合适的指导方针我们称之为学习算法 Learning Algorithm
c) 预测:学习完成后,当接受了新的数据(输入)后,我们就能通过学习阶段获得的对应关系来预测输出。
注:学习过程有两点要求:有方法评估学习正确性;当学习效果不好时,有方法纠正学习策略
线性回归(liner regression)
线性回归属于监督学习,因此方法和监督学习应该是一样的,先给定一个训练集,根据这个训练集学习出一个线性函数,然后测试这个函数训练的好不好(即此函数是否足够拟合训练集数据),挑选出最好的函数(cost function最小)即可;
a) 单变量线性回归:学到的函数是线性的且只包含一个自变量和一个因变量的回归分析称为单变量线性回归。
- 单变量线性回归模型:

,x是特征(feature),h(x)是假设模型(hypothesis),该模型得到预测值;我们假定数据特征与分类间满足该回归模型,那么如何知道这个函数模型拟合的好不好?
- 损失函数(Cost function):

,其中,

表示向量x中的第i个元素;

表示向量y中的第i个元素,y表示实际值;m为训练集的数量。损失(代价)函数是用来评判函数拟合好不好的,损失函数越小,线性回归得越好(和训练集合拟合得越好),最小是0,表示完全拟合。若我们知道函数拟合不好时(损失函数值较大),如何进行调整呢?
- 梯度下降(gradient descent):找出使损失函数值最小的参数(即

),不止有梯度下降一种方法,还有正规方程式(normal equation)方法,第二种方法后面提,此处我们只讲梯度下降方法:
[1] 先确定向下一步的步伐大小,我们称为学习率(Learning rate);
[2] 任意给定一个初始值:

;
[3] 确定一个向下的方向,并向下走预先规定的步伐,并更新
;
[4] 当下降的高度小于某个定义的值(收敛),则停止下降;
- 梯度下降算法如下图

b) 多变量线性回归:学到的函数是线性的且包含两个或以上个自变量的回归分析称为多变量线性回归。
- 多变量线性回归模型:

,具体表示同单变量线性回归;
- 多变量线性回归模型评估与单变量相同;
- 多线性回归模型的梯度下降的方法见上面单变量线性回归,此处具体说一下算法(下图):

c) 注意:
- 初始点不同,获得的最小值也不同,因此梯度下降求得的只是局部最小值;
- 越接近最小值时,下降速度越慢;
- 如果初始值
就在local minimum的位置,此时导数(derivative)为0,因此
不会变化;
- 随时观察学习率值,如果cost function变小了,则ok,反之,则再取一个更小的值;
- 下降的步伐大小(学习率)非常重要,因为如果太小,则找到函数最小值的速度就很慢,如果太大,则可能会出现overshoot the minimum(因为学习率过大,导致越过最小值,这种现象会导致无法收敛到最小值)的现象,所以如果学习率取值后发现损失函数值增长了,则需要减小学习率的值;
多项式回归(polynomial regression)
学到的函数是多项式(如平方、三次方等)的即为多项式回归,具体还细分一元多项式回归和多元多项式回归,类比单变量线性回归和多变量线性回归,很好理解。