写在前言:
1. 阅读,并不是为了记住所有的细节,而是要知晓这个事物的存在,并在合适的时机去使用它;
2. 当你跟随别人使用一个技术时,往往并不能感受其存在的必要意义,然而,当你带着问题去寻找解决方案时,在找到的那一刹,一定能深深地体会到其存在的合理性和必要性。
在做数据分析时,经常会遇到这样的问题:数据分布在多个数据源,当从这些数据源查询数据时,每个数据源都得到一个list,每个list中有着不同意义的字段数据,那么如何将多个list的数据内容合并成一个list来做统计分析?举个例子,我需要分析不同城市的人对某个page的点击次数,数据分布在MySQL和MongoDB中。
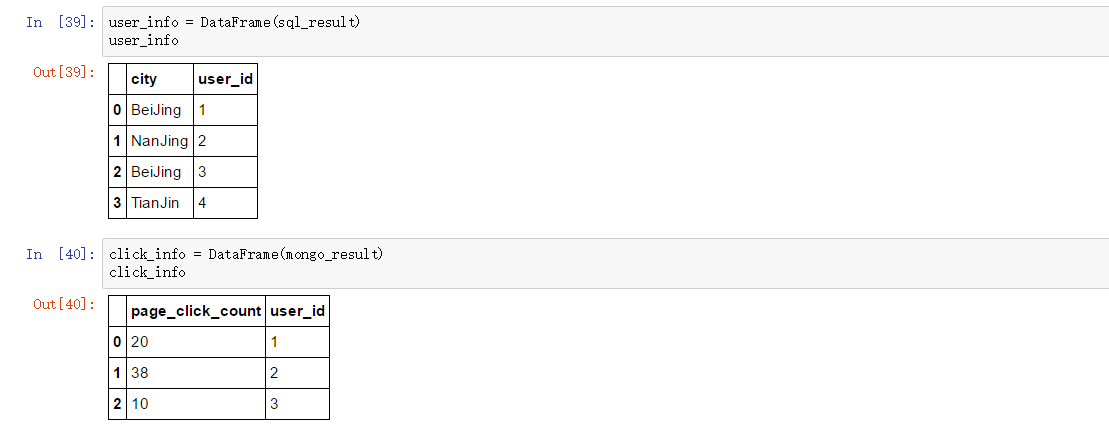
1)MySQL中查询出来的数据:
2)MongoDB中查询出来的数据:
[{'page_click_count': 20, 'user_id': 1},
{'page_click_count': 38, 'user_id': 2},
{'page_click_count': 10, 'user_id': 3}]
3)现在需要将两个列表融合起来,得到一个新的列表:
[{'city': 'BeiJing', 'page_click_count': 20, 'user_id': 1},
{'city': 'NanJing', 'page_click_count': 38, 'user_id': 2},
{'city': 'BeiJing', 'page_click_count': 10, 'user_id': 3},
{'city': 'TianJin', 'page_click_count': 0, 'user_id': 4}]
这样的问题在实际操作中会遇到很多,对应单纯的MySQL还好,如果是多个数据源或者MongoDB(MongoDB不支持JOIN),就会比较棘手了,我们且将这个问题称为异源数据融合问题(这里暂不考虑优化数据源的问题)。
要解决这个问题,通过程序编写逻辑来实现肯定是可以做到的,比如对第一个列表生成一个dict,然后循环第二个列表,如果发现dict中有user_id就插入对应数据到第二个列表中。然而,如果需要融合的不止2个,而是超过四五个,这么做就会显得很丑陋和繁琐了,此时,你可以选择自己封装一个API,或者寻找已有的解决方案。
在遇到这个问题之前,笔者就接触过一点pandas库的知识,但是因为没有很强的业务需求就没有深入使用,但是在大脑中还是保留着一个印象的:pandas是一个强大的数据分析工具包,其核心基础是数组和矩阵。带着上面的疑问和对panadas的一点点认知,开始google寻找解决方案。而pandas正好提供了这么一个强大的将数据规整化的方法:pandas.merge。
pandas.merge可以根据一个或多个键将不同的DataFrame中的行连接起来,实现了SQL JOIN风格的合并方法。以上面的问题为例,
1)构建数据结构DataFrame(Series与DataFrame是pandas的核心数据结构):
2)调用merge函数,实现数据合并:

是不是很简单?通过调用pandas.merge方法直接就解决了上述的问题,即使有多个数据源数据,也可以轻松的解决。如果你比较细心,那么一定会发现几个问题:
1)这里,并没有指定要用哪个列来做JOIN。默认的,如果没有指定,pandas就会将重叠列的列名作为键,不过,最好是显示指定一下:

但是,如果两个DataFrame对象的列名不同,该如何做呢?pandas也为你想到了,可以分别指定两个不同名字的列名来做JOIN:

2)原始数据中有四个用户id,而在上面的结果中,只有id为1,2,3的用户,那么id=4的那个用户信息哪里去了?id=4的数据消失是因为我们这里没有指定JOIN的方式,默认的,pandas使用的是INNER方式,跟SQL语法一样,只取能完全匹配的数据,如果需要保留id=4的用户信息,则需要使用LEFT的方式,如下:

通过pandas提供的merge方法,我们完美的解决了文章开始时提出的异源数据融合的问题,而pandas的强大之处远远不止于此,有需求就有解决方案,pandas的存在正是为了解决各个数据分析人员的痛楚,而我们要做的是合理使用其功能来解决实际问题。
附:关于pandas.merge的使用参数,可以进一步查看官方文档。
(全文完,本文地址:http://blog.csdn.net/zwgdft/article/details/53144591)
Bruce,2016/11/15