paper:https://arxiv.org/abs/1512.02325
code:https://github.com/weiliu89/caffe/tree/ssd
一句话概述:SSD是One-stage的物体检测器,它是直接预测每个default box(在RCNN中称为anchor)是各物体类别的概率,并做回归。另外,SSD使用不同层的feature map来handle不同大小的物体。
网络结构
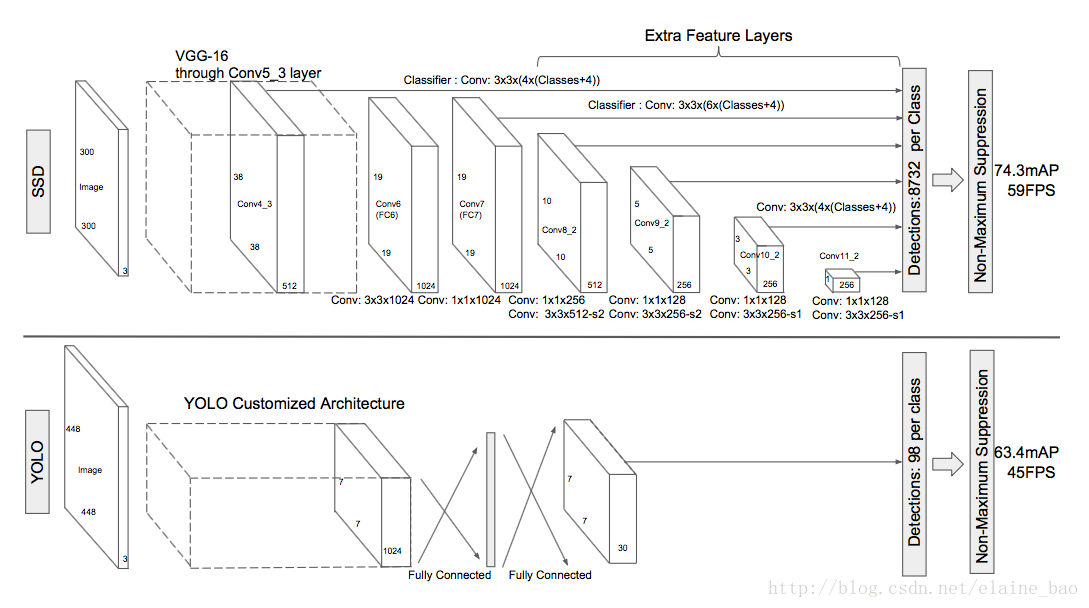
base network:和图像分类的标准结构一样(文中使用VGG-16),只是把分类相关的层去掉了,然后将 FC6,FC7 layer转成卷积层。将 Pool5 layer 的参数从 2×2−s2 转变成 3×3−s1,但是这样变化后,会改变感受野(receptive field)的大小。因此,采用了 atrous algorithm 的技术。 atrous algorithm其实就是 hole filling algorithm,这篇文章有比较详尽的解释:http://blog.csdn.net/u010167269/article/details/52563573
multiscale feature maps:如上图,在base network的基础上再加一些conv layer,这些层的尺寸逐渐变小,使得整个网络能够检测多尺度的物体。
conv predictors for detection:不同于YOLO使用全连接层做预测,SSD使用卷积层。multiscale feature layers通过conv layer输出score和location offsets,即上图中的Classifier,使用3*3的卷积核。
default boxes and aspect ratios:对于每个default box,预测c个类别的score和4个offsets,所以对于每个feature layer的每个位置来说,共有(c+4)*k个输出,其中k表示的是default box的数目,这个值在不同分辨率的feature map上不一样,例如上图中Classifier的k值有4和6两种。
训练策略
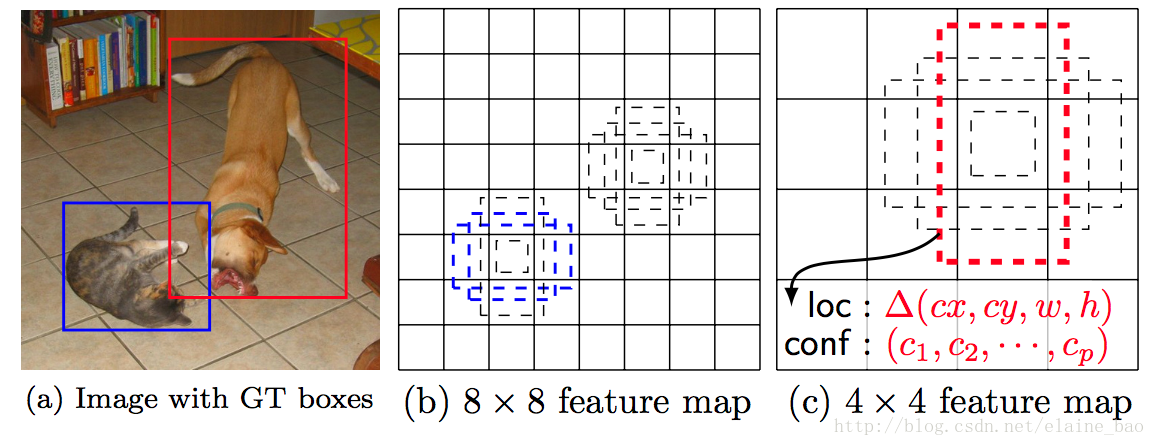
Matching strategy:训练的时候如何把default box和gt box匹配上?首先最大overlap的default box置为正,另外overlap>阈值(0.5)的也置为正。这个设定简化了学习问题,可以容许一个gt box对应多个default box。如下图,在两个scale的feature map上,猫这个object有两个default box对应,狗有一个default box对应。
Training objective:和其他物体检测算法一样,loss由分类loss和回归loss两部分组成,其中
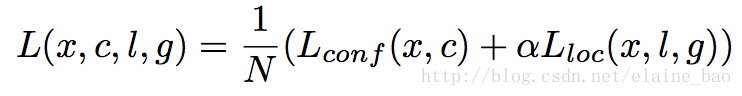
Choosing scales and aspect ratios for default boxes:如何选择default box的scale和aspect ratios?设计default box使得特定层的feature maps学习特定scale的物体。
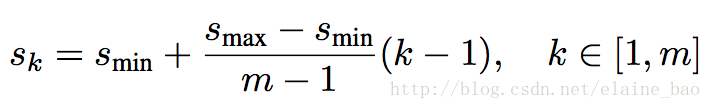
根据公式,最低层学习scale为0.2的box,最高层学习scale为0.9的box。
另外,aspect ratios取{1,2,3,1/2,1/3},这样我们就能计算每个default box的宽高:
另外在aspect ratio为1时本文还增加了一个default box,这个box的scale是:
Hard negative mining:为了避免数据imbalance的问题,选择default box中最高loss的那些负样本,使得正负样本比例接近于1:3。
Data augmentation:每张图片将通过以下方式之一进行randomly sampled:
- 使用原始的整张图片
- sample一个patch,它和物体的overlap占物体的gt box面积的系数分别为0.1,0.3,0.5,0.7,0.9.
- 随机sample一个patch.
采样的patch和原始图像大小的比例是[0.1,1], aspect ratio在[0.5,2]之间。如果gt box的中心落在采样的patch中,我们保留重叠部分。经过sampling以后,每个patch会被resize到固定大小,并且以0.5的概率进行水平翻转,另外还使用了亮度扭曲(photometric distortions),参考[14]。
实验
实验主要讲一下文章中作model analysis的部分。主要是通过控制变量来验证SSD的每个模块对最终性能的影响。

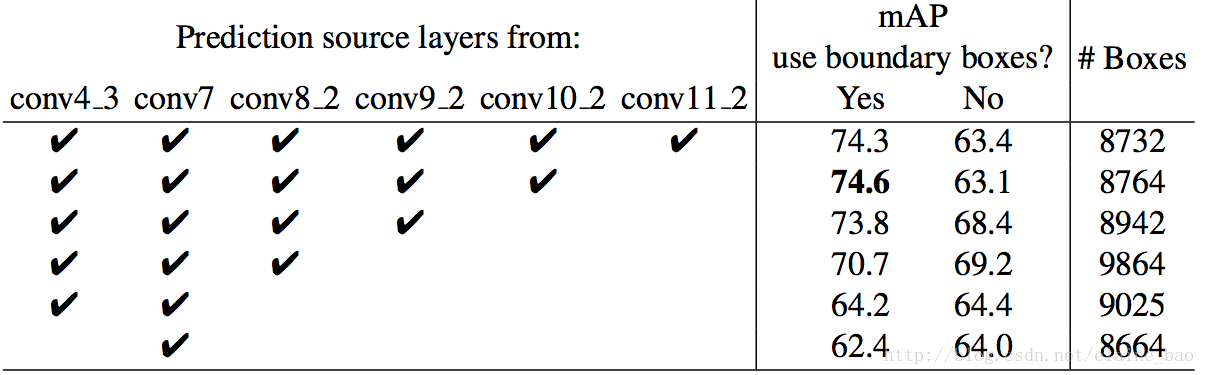
从上图中可以看出以下几点:
- 数据扩充对于结果的提升很明显
Fast和Faster R-CNN所采用的数据扩充策略是:使用原始图像,以及 0.5 的概率对原始图像进行水平翻转,然后进行训练。SSD还使用了额外的 sampling 策略,最终将 mAP 从 65.4% 提升到了 72.1%,提升了 6.7%。
我们还不清楚本文的 sampling 策略会对 Fast和Faster R-CNN 有多少好处。但是估计不会很多,因为 Fast和Faster R-CNN 在分类时使用了 feature pooling,这比人为做数据扩充还要更 robust。 - 使用更多的 default boxes,结果也越好
在SSD 中我们默认使用 6 个 default boxes(除了 conv4_3 因为大小问题使用了 3 个 default boxes)。如果将 aspect ratios 为 1/3、3 的 boxes 移除,performance 下降了 0.9%。再进一步将aspect ratios为 1/2、2 的 default boxes 移除,那么 performance 下降了近 2%。 - Atrous 使得 SSD 又好又快
我们参考 ICLR 2015, DeepLab-LargeFOV的文章,使用atrous version的 VGG16 版本。 如果我们使用原始的 VGG16 版本,即保留 pool5 的参数为2×2−s2,且不从 FC6/FC7 上采样 parameters,同时添加 conv5_3 来做 prediction,结果下降 0.7%,看起来差不太多,但是关键是速度慢了20%。 - 使用更多的不同分辨率的feature layers对结果提升更大
SSD的一个主要贡献在于在不同的输出层上使用不同scale的default box。为了验证其对性能的提升,我们 逐步减少layer,然后比较结果。为了公平期间,减少层的时候我们保持总box的数目不变,即在剩下的层中加多scale。下表显示了当逐步减少layer的时候,acc从74.3下降到了62.4。我们发现有一点,当去掉conv11_2的时候acc反而提升了,这说明这个层太coarse了,我们没有足够的large box来cover大的物体。