每天我们都在使用搜索引擎,比如Google,百度,Bing,通常我们搜索一个关键词,搜索引擎瞬间就能给出我们想要的页面。这实际上是一种非常棒的体验。可我们有没有想过为什么搜索引擎能够在数十亿的网页中瞬间找到我们理想的结果呢?一个很重要的原因就是:这些搜索引擎都使用了倒排索引技术(Inverted Index)。
如果没有倒排索引,搜索引擎在每次检索时,必须遍历所有的页面,然后在每个页面中查找是否包含了 我们搜索的关键词。这会导致一个巨大的工作量。
现在我们好奇倒排索引是怎么一回事?
1. 倒排索引是什么
为了便于说明问题,这里假定整个Web下有三个文档,每个文档包含一些单词。三个文档的内容如下 :
file1 : How are you
file2 : How do you do
file3 : What are you doing
下图是文档和单词之间的包含关系图,如下所示:
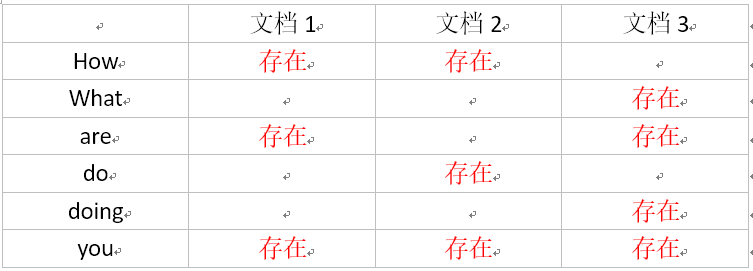
图中的“存在”表示了文档对单词的包含关系。对于这个图,可以从两个角度去分析:
- 从文档的角度来看,每列表示文档包含了哪些单词,不包含哪些单词。
- 从单词的角度来看,每行表示一个单词被哪些文档所包含,和不被哪些文档所包含。
而搜索引擎实现的就是单词–>文档的这种查找方式。要实现这种查找方式,可以有不同方式实现,比如“倒排索引”、“后缀树”等,这里主要介绍倒排索引的具体内容。
1.1 与倒排索引相关的一些概念
- 文档:一般搜索引擎的处理对象是互联网的网页,而文档的概念更加宽泛,代表以文本形似存在的存储对象。
- 文档集合:所有的文档构成的集合。例如所有Web网页就是一个文档集合 。
- 文档编号:在搜索引擎内部,会对每一个文档赋予一个唯一的内部编号,作为文档标识。
- 单词编号:与文档类似,对每一个单词赋予一个唯一的内部编号,作为单词的标识。
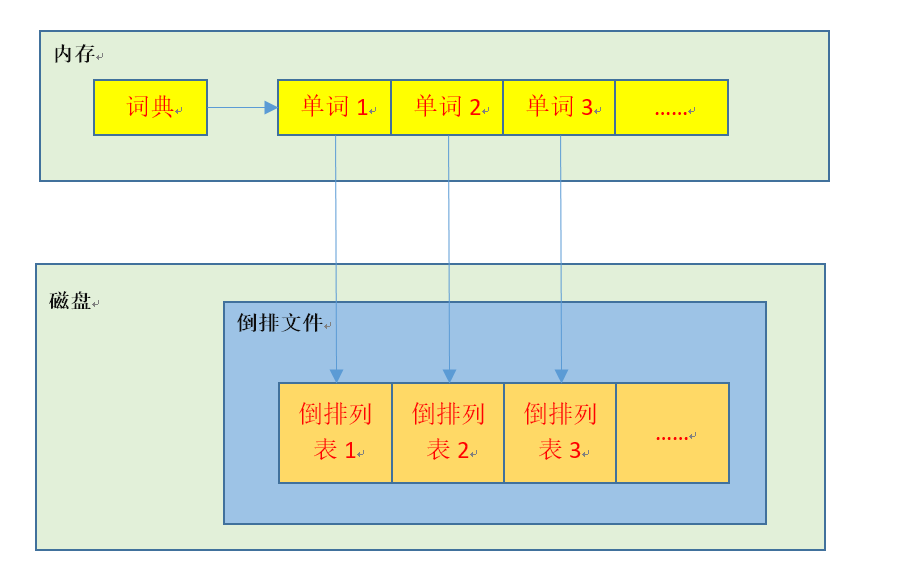
- 倒排索引:它是实现单词–>文档的具体存储形式,通过倒排索引,可以根据单词快速找到包含该单词的文档列表。倒排索引主要包含两部分:
- 1 单词字典:搜索引擎通过单词进行搜索,单词字典是文档集合中出现的所有单词构成的集合。单词字典内每条索引项记载着单词自身的一些信息和该单词所指向的倒排索引的列表。
- 2 倒排列表:它是指包含一个单词的所有文档的文档列表。
- 倒排文档:所有单词的倒排列表往往顺序的存储在磁盘的某个文档里,该文档称为倒排文档。
以上这些与倒排索引相关的概念,他们的联系可以通过下图进行表示:
1.2 倒排索引的处理
下面我们 结合最初的例子和上面介绍的概念,对倒排索引如何处理进行分析。
首先我们对三个文档给出文档编号

我们的目的是要对每个单词建立倒排索引。(这里附加说明一句,英文的单词有明显的分割,而中文的相对比较复杂,需要考虑中文的语义。所以如果对中文进行倒排索引,需要先对文档内容进行分词。)
对于英文文档,每一个词都很明确。我们只需要对所有单词赋予一个唯一编号,同时记录下哪些文档包含这些单词。如下图所示。
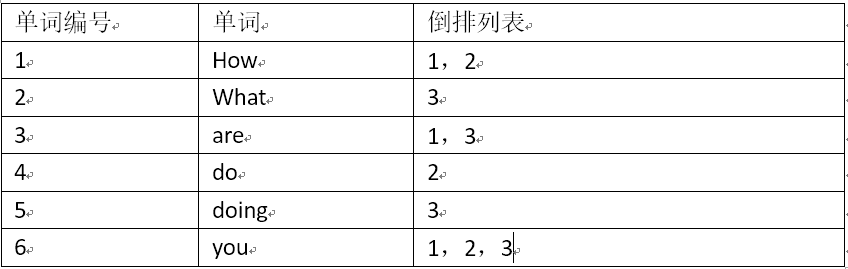
这里第一列为每个单词所对应的唯一编号,第二列为单词,第三列为单词所对应的倒排列表。显然地,这里的倒排列表十分简单,只记载了哪些文档包含了某个单词,没有其他多余的信息。实际上,我们通常还会记录一些其他的东西,比如词频。因为我们可以根据一个文档中某个单词出现次数,来对文档列表的所有文档进行排序。下图是加入词频后的倒排索引。
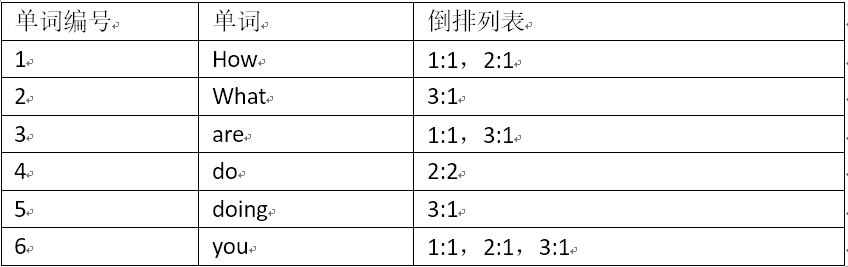
在上图中,倒排列表中”:”前是文档编号,”:”后是单词在该文档下的词频。因为这个示例比较简单,单词在每个单词中的词频为1,而现实情况通常单词在每个文档的词频相差很大,所以词频可以作为文档排序的一个依据。(需要注意的是:如果只使用词频作为排序标准,是有极大弊端的。现代搜索引擎通常使用PageRank 算法进行文档重要程度的估量)
除了词频之外,我们可以联想到还有一类信息可以记载,那就是文档频率信息。也即是说一个单词在多少个文档中出现过。它一般不放在倒排列表中,而是另外存放,只需要能被单词的倒排索引索引到即可。那么加入之后的形似如下图所示。

上面的信息基本是单词的索引系统中必需的信息,还有一类信息对于搜索引擎来说不是 必须具备的,得依据搜索引擎它自身的特性或者说是目的来决定是否添加。这类 信息指的是单词在文档中的位置信息。那么加入位置信息的倒排列表是如下结果:

到现在为止,单词的倒排索引已经基本完备了。通过这个索引系统,当用户输入一个关键词后,搜索引擎通过单词词典找到这个单词,继而找到该单词得到对应的单词索引–既包含了单词的一些基本信息,也包含了单词所对应的文档频率,倒排列表。倒排列表中的文档即是提供给用户的搜索结果。而通过文档频率,单词频率这些信息,能够对倒排列表中的文档进行排序,使之最符合用户需求的文档呈现在首页,达到满足用户体验的目的。
2. 基于MapReduce的倒排索引设计思路
在本节中,我们实现一种简单的倒排索引–包含文档和词频,不包含文档频率和单词位置。之后在此基础上可以继续改进,做出更加复杂的倒排索引。
那么我们要实现这种倒排索引,就需要获取三类信息:单词,文档名,词频。然后将其输出。我们知道,在MapReduce架构中,输出结果只有key,和value 。因此,我们的输出结果应该是一类信息作为key,另外两类信息组合作为value。
通常我们在做MapReduce处理时,主要是使用Map和Reduce 两个过程即可,主要是由于Map的输出结果 ,一个Reduce 即可处理 。当Map的输出结果,需要进行多种不同的处理才能得到我们想要的输出的时候,这时一个Reduce 通常无法实现,一般我们通过Combine 过程去解决。(这个思路在最基本的实例WordCount 也有体现,只是在WordCount 实例上不加Combine 同样可以 完成任务,而加了之后是为了先在本地进行词频统计,压缩了网络传输给Reduce的数据量,减缓了网络压力。)
2.1 Map过程的设计
- 对输入的value进行解析,得到文档中的所有单词。
- 获得< key value>所属的FileSplit 对象,得到文档名信息
- 将单词和文档名进行组合,作为输出的key;并把词频初始化为1,作为输出的value。(这里之所以将初始化为1的词频作为value,是为了下一步对词频进行加和)
经过Map过程的处理,得到结果 如下:
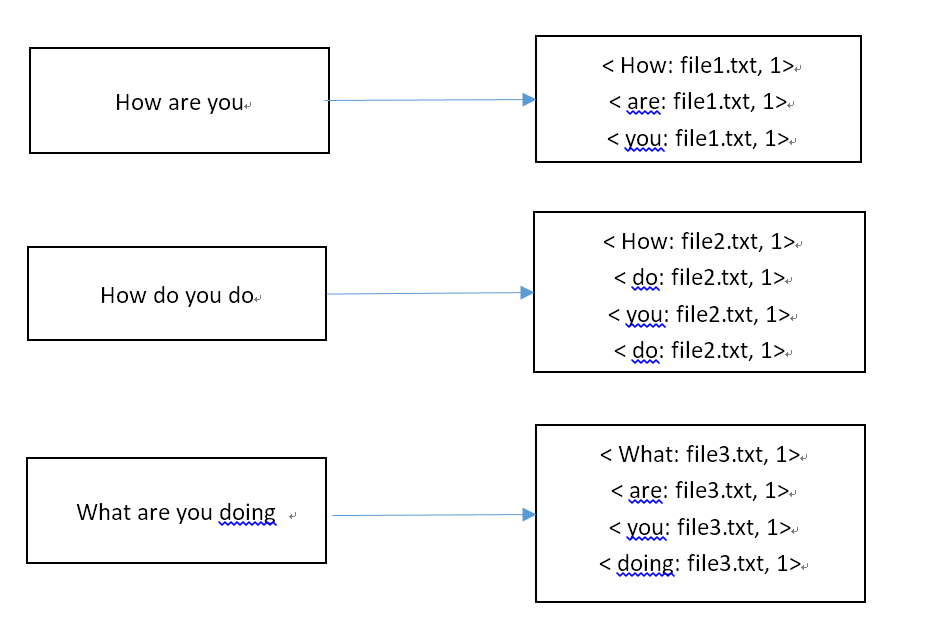
Shuffle 过程的处理结果(组合并排序)

2.2 Combine过程的设计
- 对相同的key的value进行加和,得到单词在一个文档下的词频。
- 因为我们最后Reduce过程要输出的结果是“单词–文档:词频”,所以我们需要在Combine 过程把key 和value进行一个调整,从原来的“单词:文档–>词频”转变成”单词–>文档:词频”(经过这样处理之后,在接下来的Shuffle过程就会对 单词进行排序,并将相同单词对应的文档放入一个列表中)
根据以上思路,Combine过程的输出结果如下:

Shuffle 的处理过程如下:

2.3 Reduce过程的设计
- Reduce的输入的key 为单词,list(value) 为对应的列表,列表里包含了文档和词频。
- 因此,Reduce的输出key 和输入的key 保持一致;输出的value 是把输入的value列表的每一个值,进行组合即可。
Reduce过程的输出结果,如下所示。

3. 源码分析
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class InvertedIndex_third {
/*Map过程*/
public static class MyMap extends Mapper<Object,Text,Text,Text>{
private Text keyInfo = new Text();
private Text valueInfo = new Text();
private FileSplit split;
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
split = (FileSplit)context.getInputSplit();//获得< key value>所属的FileSplit 对象
StringTokenizer str = new StringTokenizer(value.toString());
int SplitIndex = split.getPath().toString().indexOf("file");
while(str.hasMoreTokens()){
keyInfo.set(str.nextToken()+":"+split.getPath().toString().substring(SplitIndex));
valueInfo.set("1");
context.write(keyInfo, valueInfo); //输出形式<单词:文件名,“1”>
}
}
}
/*Combine过程*/
public static class MyCombine extends Reducer<Text,Text,Text,Text>{
private Text keyInfo = new Text();
private Text valueInfo = new Text();
public void reduce(Text key,Iterable<Text> values,Context context)
throws IOException,InterruptedException{
int sum = 0;
/*对词频加和*/
for(Text val:values){
sum += Integer.parseInt(val.toString());
}
/*转换输出方式*/
int SplitIndex = key.toString().indexOf(":");
keyInfo.set(key.toString().substring(0,SplitIndex));
valueInfo.set(key.toString().substring(SplitIndex+1)+":"+sum);
context.write(keyInfo, valueInfo);
}
}
/*Reduce过程*/
public static class MyReduce extends Reducer<Text,Text,Text,Text>{
private Text valueInfo = new Text();
public void reduce(Text key,Iterable<Text> values,Context context)
throws IOException,InterruptedException{
String result = new String();
/*对values中的值进行连接*/
for(Text val:values){
result += val.toString()+";";
}
valueInfo.set(result);
context.write(key,valueInfo);
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "172.16.10.15:9001");
String pathIn1 = "hdfs://172.16.10.15:9000/user/hadoop/invertedindexinput";
String pathOut="hdfs://172.16.10.15:9000/user/hadoop/invertedindexoutput";
Job job = new Job(conf,"word count");
job.setJarByClass(InvertedIndex_third.class);
job.setMapperClass(MyMap.class);
job.setCombinerClass(MyCombine.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(pathIn1));
FileOutputFormat.setOutputPath(job, new Path(pathOut));
System.exit(job.waitForCompletion(true)?0:1);
}
}
基于以上源码,我设置输入如下:
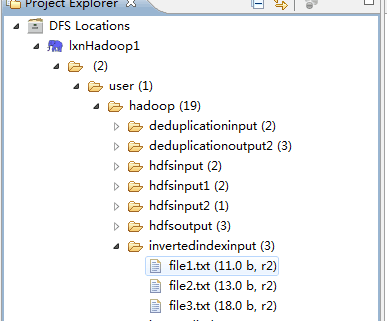
其中invertedindexinput 为我 设置的输入路径,里面有 三个文档,文档内容是上文中三个file内容一致。
下图是代码运行后的输出结果。
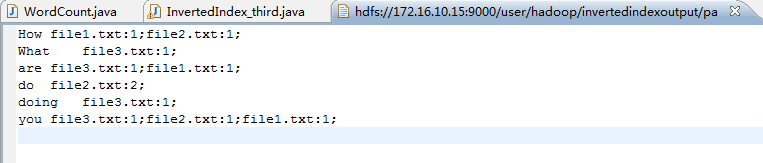
参考文献
- 搜索引擎索引之索引基础 http://blog.csdn.net/malefactor/article/details/7256305
- Hadoop集群(第9期)_MapReduce初级案例 http://www.cnblogs.com/xia520pi/archive/2012/06/04/2534533.html
- Hadoop 学习笔记 (六) MapReduce实现倒排索引 修改版 - 雨渐渐 http://www.tuicool.com/articles/zuaEJ3v