这段时间在做调研,我们小组负责了解微软的Azure的情况,按照官网教程,我搭建了一遍官网示例——汽车价格预测,过程如下:
一、创建模型
1.获取数据
若要进行机器学习,首先需获取数据。 可以使用机器学习工作室随附的多个示例数据集,也可以从多种源导入数据。 本示例将使用工作区中包含的示例数据集“汽车价格数据(原始)”。 此数据集包含各辆汽车的条目,包括制造商、车型、技术规格、价格等方面的信息。
下面介绍如何将数据集导入试验中:
(1)创建新的试验,方法是:单击“机器学习工作室”窗口底部的“+新建”,选择“试验”,并选择“空白试验”
(2)试验有一个默认名称,显示在画布顶部。 选中该名称,将试验重命名为某个有意义的名称,例如“汽车价格预测”, 名称不需唯一
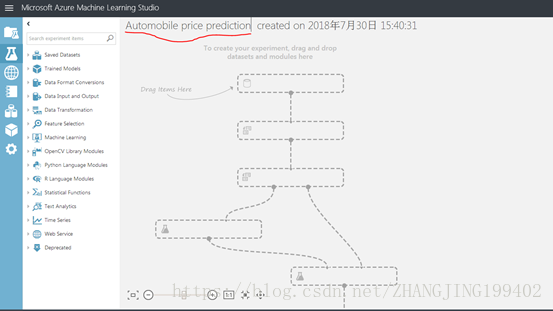
(3)试验画布左侧是数据集和模块的控制板。 在此控制板顶部的“搜索”框中键入automobile,找到标有“汽车价格数据(原始)”的数据集。 将该数据集拖放到试验画布上
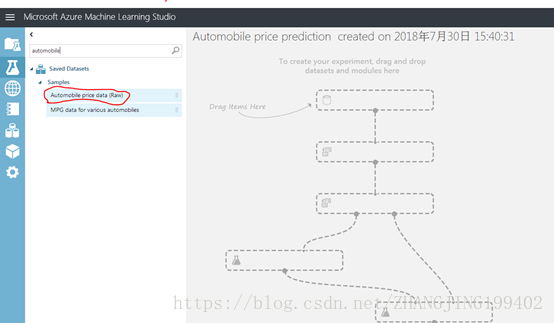
要查看此数据的大致情况,请单击汽车数据集底部的输出端口,并选择“可视化”
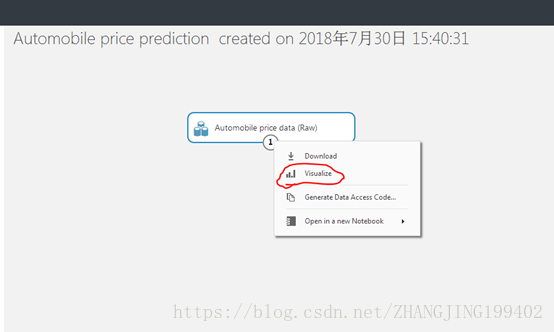
可视化结果如下图
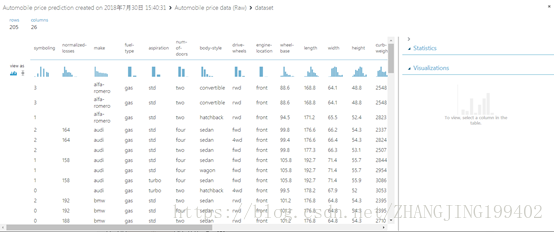
2.准备数据
数据集通常需要经过一定的预处理才能进行分析。 例如,可能已注意到,在多个行的列中存在缺失值。 需要清除这些缺失值,使模型能够正确分析数据。 在本例中,将删除包含缺失值的所有行。 此外,“规范化损失”列包含较大比例的缺失值,因此要将该列从模型中完全排除。
首先添加一个彻底删除“规范化损失”列的模块,然后添加另一个删除任何有缺失数据的行的模块:
(1)在模块控制板顶部的“搜索”框中键入“选择列”,查找选择数据集中的列模块,然后将其拖放到试验画布上。 使用此模块可以选择要将哪些列包含在模型中,或者从模型中排除。
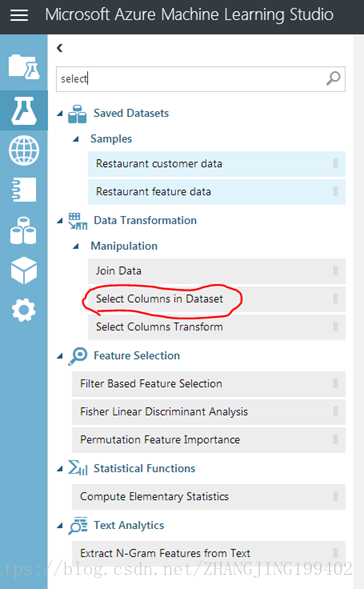
(2)将“汽车价格数据(原始)”数据集的输出端口连接到选择数据集中的列模块的输入端口。
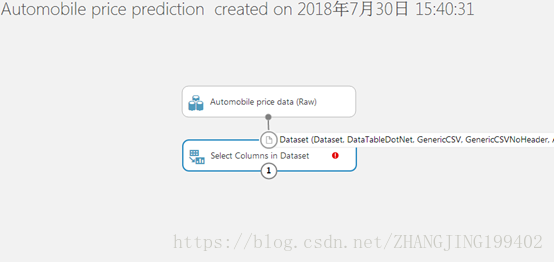
(3)单击红色感叹号Value required
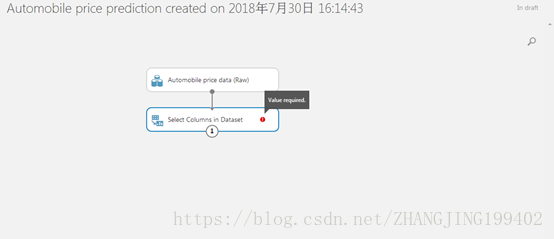
得到下图,单击右边Launch column selector
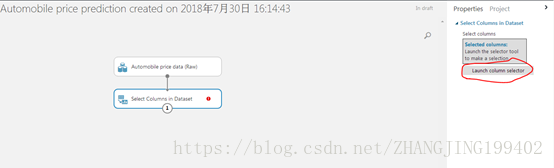
于是
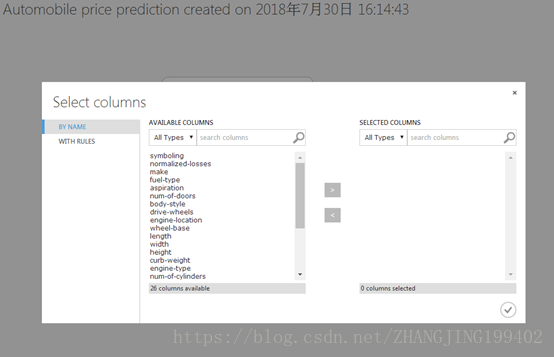
单击左侧“With rules”
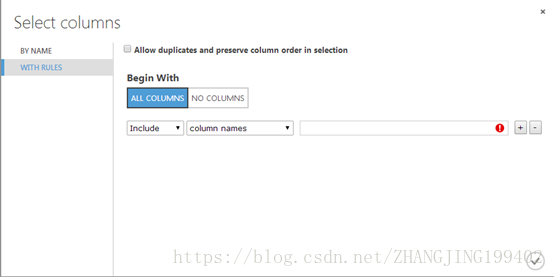
在Begin with下面,单击ALL COLUMNS。 这会指示选择数据集中的列传递所有列(但要排除的列除外);
在下拉列表中,选择“exclude”和“column names”,并在文本框内部单击。 此时会显示列的列表。 选择“nomalized losses”,该列随即添加到文本框中;
单击复选标记(“确定”)按钮,关闭列选择器(单击右下角对号)
此时右侧显示如下:属性窗格显示“normalized losses”列已排除

(4)将清理缺失数据模块拖到试验画布,然后将其连接到选择数据集中的列”模块。 在“属性”窗格的“清理模式”下选择“删除整行”。 这会指示清理缺失数据清理数据,删除存在缺失值的行。 双击该模块并键入注释“删除缺失值行”。
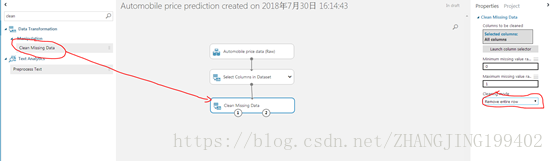
(5)通过单击页面底部的“run”运行此试验,试验运行完以后,所有模块都会出现绿色复选标记,表示已成功完成。 另请留意右上角的“已完成运行”状态。

试验到目前为止所完成的工作就是清理数据。 要查看已清理的数据集,请单击清理缺失数据模块左侧的输出端口,并选择“可视化”。 请注意,此时不再包含“规范化损失”列,并且也没有缺失值。
现已清理数据,接下来可以指定要在预测模型中使用哪些特征。
3.定义特征
在机器学习中, 特征是用户感兴趣的某些内容的各个可测量属性。 在此处的数据集中,每个行代表一辆汽车,每个列是该汽车的特征。
若要找到一组理想的特征来创建预测模型,需要针对要解决的问题进行试验,并且具有相关知识。 有些特征比其他特征更适合用于预测目标。 另外,某些特征与其他特征有很强的关联性,可以将其删除。 例如,city-mpg(市区油耗)和 highway-mpg(高速公路油耗)密切相关,因此可以保留一个,删除另一个,不会对预测产生明显影响。
让我们构建一个模型,它使用数据集中的一部分特征。 以后还可以返回此处,选择不同的特征,再次运行试验,并确认是否获得了理想的结果。 不过,让我们先尝试使用以下特征:
make, body-style, wheel-base, engine-size, horsepower, peak-rpm, highway-mpg, price
将另一选择数据集中的列模块拖放到试验画布上。 将清理缺失数据模块左侧的输出端口连接到选择数据集中的列模块的输入端口。
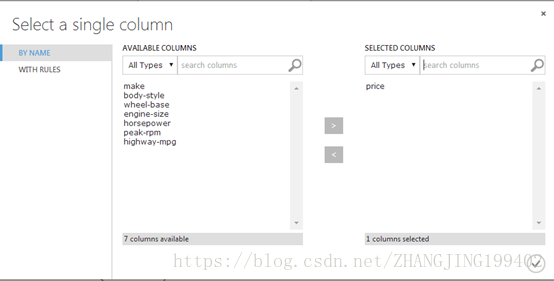
如下图选中上述特征:
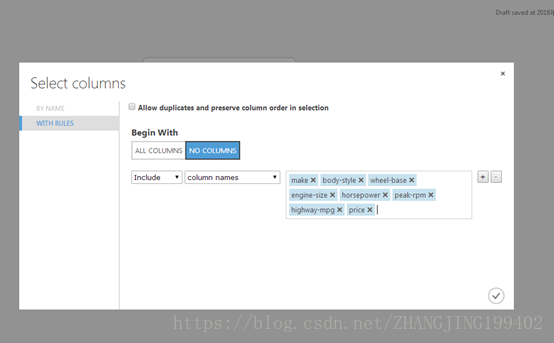
此时会生成经过筛选的数据集,只包含需要传递到下一步使用的学习算法中的特征。 稍后可以返回,选择不同的特征重试生成结果。
二、模型
选择并应用学习算法
准备好数据后,构造预测模型的过程包括训练和测试。 我们将使用数据对模型定型,然后测试模型,看其预测价格时准确性如何。
分类 和回归 是两种监督式机器学习算法。 分类可以从一组定义的类别预测答案,例如颜色(红、蓝或绿)。 回归用于预测数字。由于要预测价格(一个数字),因此需使用回归算法。 就此示例来说,我们将使用简单的线性回归 模型。
对模型定型时,我们会为其提供一组包含价格的数据。 模型会扫描数据,查找汽车特征与其价格的关联性。 然后,我们会测试模型 - 我们会为模型提供一组熟悉的汽车特征,看模型预测已知价格的准确性如何。我们会将数据拆分为单独的定型数据集和测试数据集,用于模型定型和测试。
(1)选择拆分数据模块并将其拖到试验画布,然后将其连接到最后一个选择数据集中的列模块的输出。
(2)单击拆分数据模块将其选中。 找到“第一个输出数据集中的行的比例”(位于画布右侧的“属性”窗格中),将其设置为 0.75。 这样,我们将使用 75% 的数据进行模型定型,保留 25% 的数据用于测试(可在以后使用不同的百分比进行试验)。
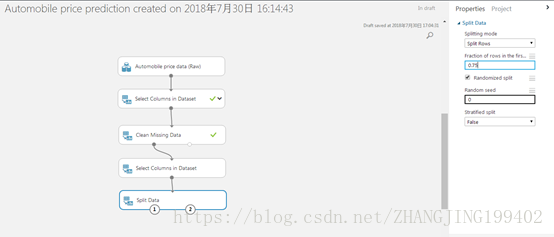
(3)运行试验。 运行试验时,选择数据集中的列和拆分数据模块会将列定义传递到接下来要添加的模块。
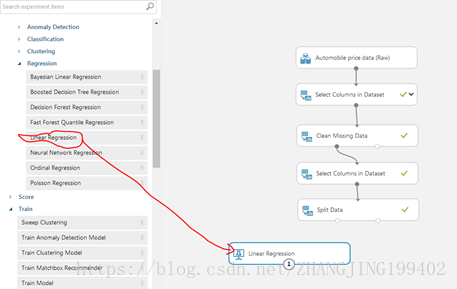
(4)要选择学习算法,请在画布左侧的模块控制板中展开“machine learning”类别,并展开“Initialize Model”。 此时会显示多个可用于初始化机器学习算法的模块类别。 对于本试验,请选择“回归”类别下的线性回归模块,然后将其拖放到试验画布上。 (也可以在控制板的“搜索”框中键入“线性回归”找到该模块。)
(5)找到训练模型模块并将其拖到试验画布。 将线性回归”模块的输出连接到定型模型模块左侧的输入,将拆分数据”模块的定型数据输出(左端口)连接到定型模型”模块右侧的输入。
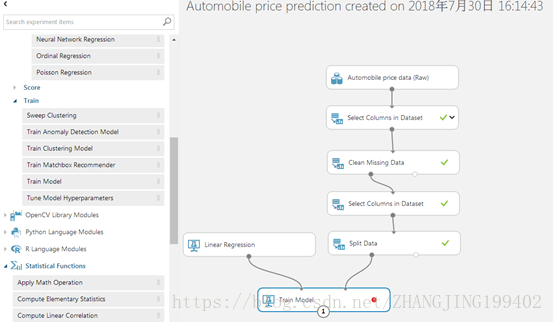
(6)选择“训练模型模块,单击属性窗格中的启动列选择器,并选择价格列。 这是模型要预测的值。在列选择器中选择“价格”列,方法是将其从“可用列”列表移至“所选列”列表。
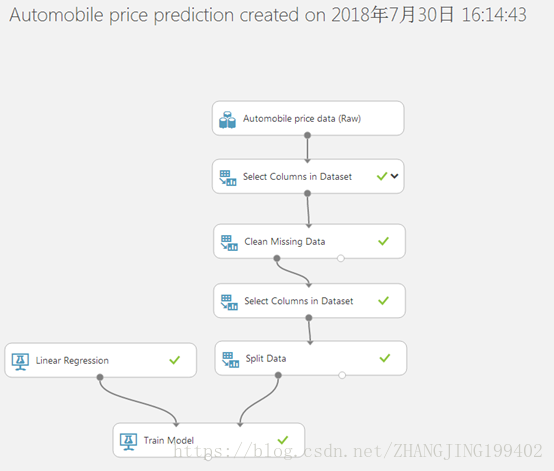
(7)运行试验
我们现在获得了一个经过定型的回归模型,用来为新的汽车数据评分,以便进行价格预测。
三、对模型进行评分和测试
预测新汽车价格
使用 75% 的数据训练模型后,可以使用该模型为另外 25% 的数据评分,确定模型的运行情况。
(1)找到评分模型模块并将其拖放到试验画布上。 将定型模型模块的输出连接到评分模型的左侧输入端口。 将拆分数据模型的测试数据输出(右侧端口)连接到评分模型.
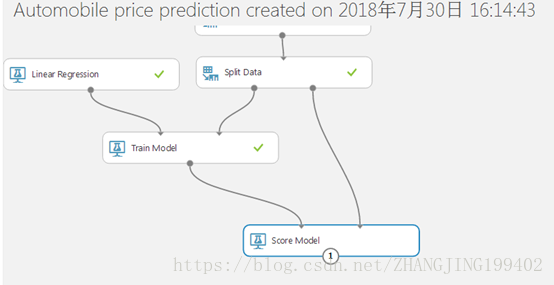
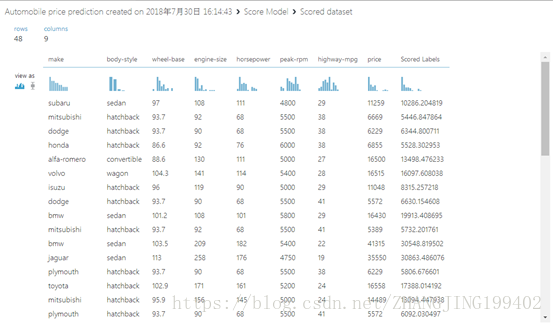
(2)运行试验,查看评分模型模块的输出(单击评分模型的输出端口,并选择“可视化”)。 输出显示价格预测值,以及来自测试数据的已知值
(3)最后,我们对结果的质量进行测试。 选择评估模型模块并将其拖放到试验画布上,然后将评分模型模块的输出连接到评估模型的左侧输入。
注:之所以评估模型模块上有两个输入端口,是因为可将其用于并列比较两个模型。 可在以后向试验添加另一算法,并使用评估模型查看哪一个算法的结果更好。
(4)运行试验
要查看评估模型模块的输出,请单击输出端口,并选择“可视化”。
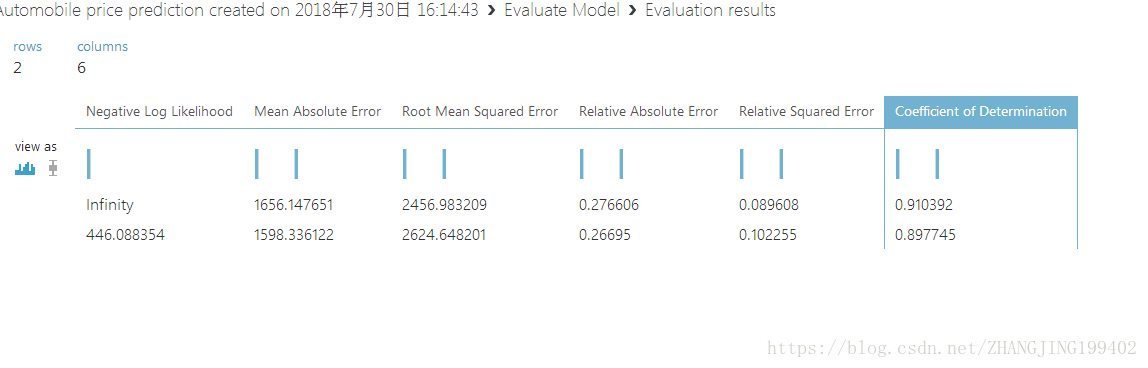
可视化如下
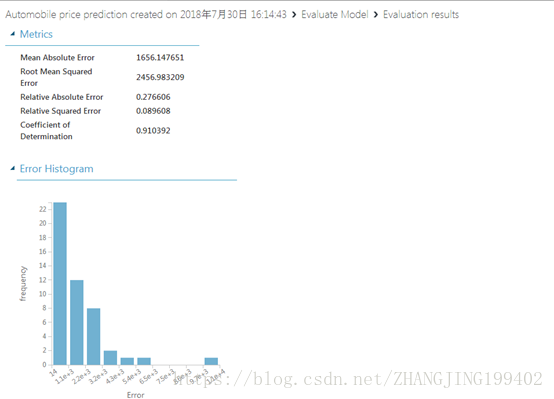
针对本例中的模型显示了以下统计信息:
平均绝对误差 (MAE):绝对误差的平均值( 误差 是指预测值与实际值之间的差异)。
均方根误差 (RMSE):对测试数据集所做预测的平均误差的平方根。
相对绝对误差:相对于实际值与所有实际值平均值之间的绝对差异的绝对误差平均值。
相对平方误差:相对于实际值与所有实际值平均值之间的平方差异的平方误差平均值。
决定系数:也称为 R 平方值,这是一个统计度量值,表示模型的数据拟合度。
每个误差统计值越小越好。 值越小,表示预测越接近实际值。 对于 决定系数,其值越接近 1 (1.0),预测就越精确。
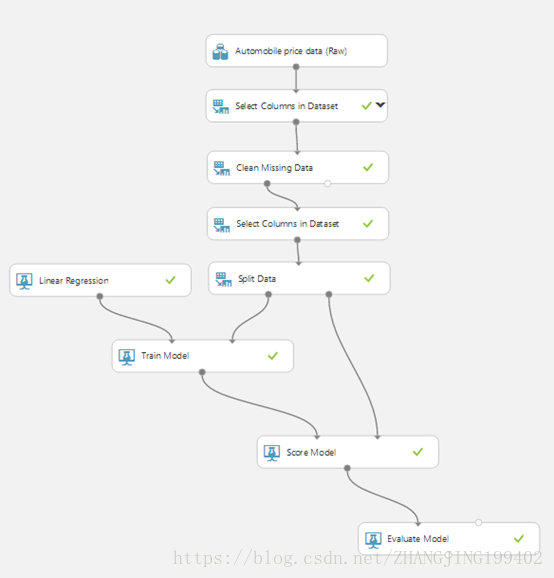
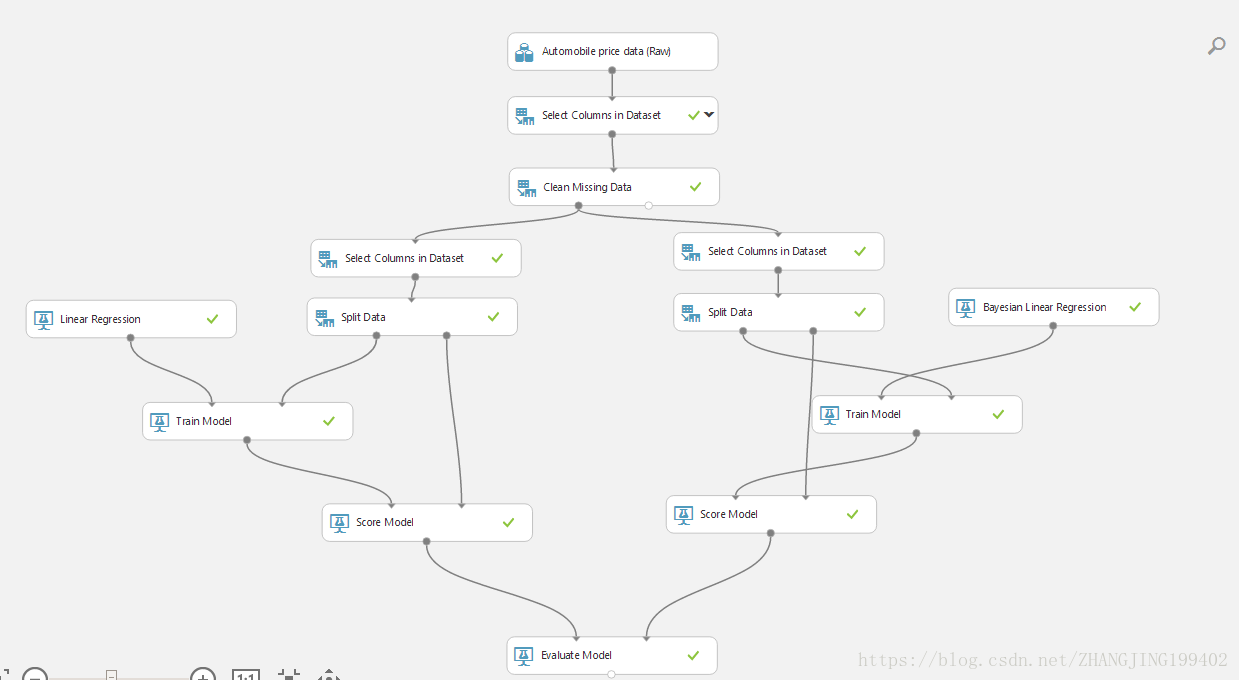
四、最终试验
最终试验看起来应与下图类似:
另外加了贝叶斯线性回归做对比最终效果如下:
可视化如下,可以观察到,最终效果贝叶斯线性回归比线性回归差一点