2016年7月,一名德国籍的大牛Abhishek Thakur在他的Kaggle博客发布了一篇文章,题目叫做《Approaching (Almost) Any Machine Learning Problem》。文章作者参加了上百次机器学习比赛,并取得了Kaggle的最高等级:Grandmaster。文章总结了作者参加Kaggle比赛形成的一套“万能模板”。希望通过这篇文章能给读者带来解决机器学习问题的思路,早日形成自己的机器学习方法论。
下面我们选择的翻译了文章部分内容,原文请点击这里。
数据科学家每天都在和数据打交道,有人说,其中超过60%-70%的时间用于数据清洗,加工,将数据转换成适合机器学习模型应用的格式。这篇文章的注意力放在第二步,也就是应用机器学习模型这部分内容。文中讨论的流水线(Pipeline)是我参加上百次机器学习比赛的总结。
一、Python工具库
我们选择Python做数据分析,首先,安装最基本的科学计算和机器学习库,例如numpy和scipy。然后,你可能需要下面的库:
- Pandas 查看和操作数据 (译者注:可以理解为命令行版本的excel)
- scikit-learn 机器学习模型
- xgboost 最好的gradient boosting库
- keras 神经网络
- matplotlib 画图
- tqdm 观察过程
此外,我不用Anaconda,它很简单而且为你做任何事,但我想要更多自由。
二、机器学习框架
总体框架图如下,建议读者先简单浏览架构即可,通读全文后再回来看,效果更好。
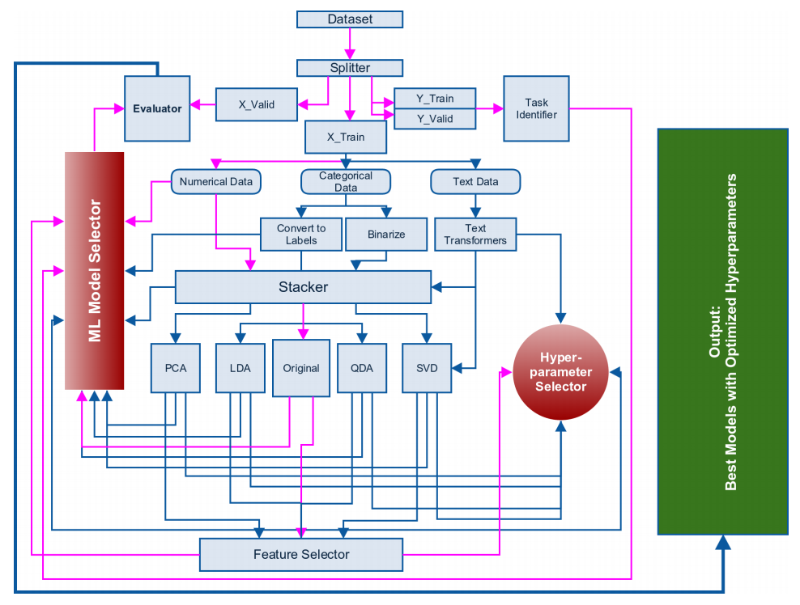
1. 识别问题类型, 分割训练集和验证集
第一步是识别问题的类型。你必须知道一个问题是分类问题还是回归问题;如果是分类问题,那么是二分类还是多分类问题。识别出问题类型后,我们将数据分割成两部分:一部分做训练集合,另一部分做验证集合。

分割训练集和验证集必须通过标签来做到,在任何分类问题中,请选择分层分割法(Stratified splitting)。在Python中,你可以用scikit-learn非常容易地实现stratified splitting。

在回归任务中,简单的k-重分割(k-fold splitting)已经足够了。这里还有一些复杂的分割数据方法,试图在分割后保留训练集合验证集标签的分布,我们把这部分内容留作家庭作业。

上面的例子中,我选择10%比例的数据作为验证集,你可以根据拥有数据量的大小自行选择。分割数据完成后,不要再碰验证数据集,任何训练集应用的操作必须首先保存,然后才能应用到验证集。任何情况下都不要用验证集合训练集做连接(Join)操作。这样做会达到非常好的评价分数,然而这是一个没有用的模型,因为它过拟合了。
2. 识别变量,形成特征
下一步是识别数据中不同的变量。 通常我们处理的变量类型包括以下三种:数值变量,类别变量和文本变量。我们以Titanic数据集为例,
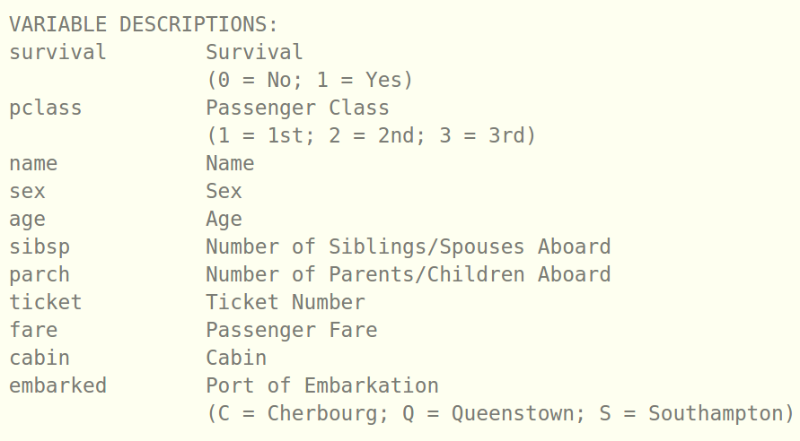
这里,survival是标签。我们已经在上一步的训练集合中分离出了标签,然后有pclass,sex,embarked,这些变量都是标签,或者说是类别变量;age,sibsp,parch,等等这些变量是数值变量;name是文本变量,虽然在本例中name对于预测survival并没有起到作用。
首先分离出数值变量,这些变量不需要处理,我们可以直接对这些数值变量应用正则化(normalization)和机器学习模型。
然后是类别变量。类别变量有两种处理方式,一种是转换成标签(Label Encoding),另一种是转换成二元变量(One-hot Encoding)。
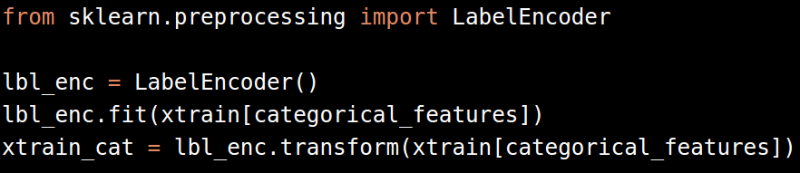
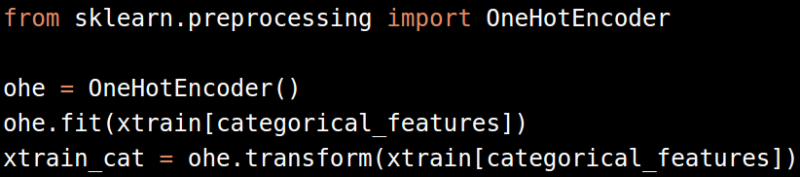
最后是文本变量。很遗憾Titanic数据集中没有合适的文本变量。一般我们处理文本变量的方法是,合并所有的文本形成一个变量,然后调用Count Vectorizer或者TfidfVectorizer算法,将文本数据转换成数字。


大部分情况下,TfidfVectorizer比CountVectorizer表现更好;而且,下面一组参数几乎任何时候都有效。
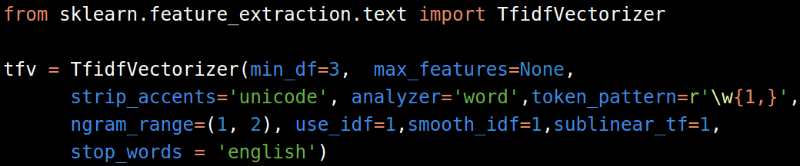
如果你只在训练集上使用这些文本向量,请把它们保存到磁盘,以便在验证集上继续使用。

2016-11-18更新
我们再举个例子,Santander银行产品推荐。比赛的数据包括用户个人基本信息,以及过去一年他们的行为。
首先使用pandas浏览数据
>>> import pandas as pd
>>> test = pd.read_csv('/home/data/SanRecommend/data/test_ver2.csv')
>>> test.head()
fecha_dato ncodpers ind_empleado pais_residencia sexo age fecha_alta \
0 2016-06-28 15889 F ES V 56 1995-01-16
1 2016-06-28 1170544 N ES H 36 2013-08-28
2 2016-06-28 1170545 N ES V 22 2013-08-28
3 2016-06-28 1170547 N ES H 22 2013-08-28
4 2016-06-28 1170548 N ES H 22 2013-08-28
ind_nuevo antiguedad indrel ... indext conyuemp \
0 0 256 1 ... N N
1 0 34 1 ... N NaN
2 0 34 1 ... N NaN
3 0 34 1 ... N NaN
4 0 34 1 ... N NaN
canal_entrada indfall tipodom cod_prov nomprov \
0 KAT N 1 28.0 MADRID
1 KAT N 1 3.0 ALICANTE
2 KHE N 1 15.0 CORUÑA, A
3 KHE N 1 8.0 BARCELONA
4 KHE N 1 7.0 BALEARS, ILLES
ind_actividad_cliente renta segmento
0 1 326124.90 01 - TOP
1 0 NA 02 - PARTICULARES
2 1 NA 03 - UNIVERSITARIO
3 0 148402.98 03 - UNIVERSITARIO
4 0 106885.80 03 - UNIVERSITARIO
[5 rows x 24 columns]按“数值变量”“文本变量”“类别变量”, 人工标注数据变量的类别。
| 变量名 | 样例 | 变量类别 |
|---|---|---|
| ncodpers | 15889 | ID |
| fecha_dato | 2016-06-28 | 日期 |
| fecha_alta | 1995-01-16 | 日期 |
| ind_empleado | F | 类别变量 |
| pais_residencia | ES | 类别变量 |
| sexo | V | 类别变量 |
| ind_nuevo | 0 | 类别变量 |
| indrel | 1 | 类别变量 |
| indext | N | 类别变量 |
| conyuemp | N | 类别变量 |
| canal_entrada | KAT | 类别变量 |
| indfall | N | 类别变量 |
| tipodom | 1 | 类别变量 |
| nomprov | MADRID | 类别变量 |
| ind_actividad_cliente | 1 | 类别变量 |
| segmento | 01 - TOP | 类别变量 |
| antiguedad | 256 | 数值变量 |
| age | 56 | 数值变量 |
| cod_prov | 28.0 | 数值变量 |
| renta | 326124.90 | 数值变量 |
这里我们遇到了两个问题: 1. ID,算哪种类型? 2. 时间,算哪一种类型?
留作思考题吧
LabelEncoding
>>> lbl_enc.fit(test['segmento'])
LabelEncoder()
>>> test_cat = lbl_enc.transform(test['segmento'])
>>> test_cat
array([1, 2, 3, ..., 2, 2, 2])>>> categorical_features = ['ind_empleado', 'pais_residencia', 'sexo', 'ind_nuevo', 'indrel', 'indext', 'conyuemp', 'canal_entrada', 'indfall', 'tipodom', 'nomprov', 'ind_actividad_cliente', 'segmento']
>>> numerical_features = ['antiguedad', 'age', 'cod_prov', 'renta']>>> featured_test = {}
>>> for feature in categorical_features:
... lbl_enc.fit(test[feature])
... featured_test[feature] = lbl_enc.transform(test[feature])
... print feature, featured_test[feature]
... 如果遇到这种错误,
Traceback (most recent call last):
File "<stdin>", line 3, in <module>
File "/home/renq/anaconda2/lib/python2.7/site-packages/sklearn/preprocessing/label.py", line 148, in transform
raise ValueError("y contains new labels: %s" % str(diff))
ValueError: y contains new labels: [nan nan nan ..., nan nan nan]
>>>我们应该回头处理下数据(NaN,即Not a Number), 例如,用0填充
test.fillna(0, inplace=True)如果一切顺利,你应该可以得到
ind_empleado [2 3 3 ..., 3 3 3]
pais_residencia [36 36 36 ..., 36 36 36]
sexo [2 1 2 ..., 2 2 2]
ind_nuevo [0 0 0 ..., 0 0 0]
indrel [0 0 0 ..., 0 0 0]
indext [0 0 0 ..., 0 0 0]
conyuemp [1 0 0 ..., 0 0 0]
canal_entrada [ 25 25 151 ..., 51 123 25]
indfall [0 0 0 ..., 0 0 0]
tipodom [0 0 0 ..., 0 0 0]
nomprov [31 3 19 ..., 5 5 48]
ind_actividad_cliente [1 0 1 ..., 1 0 0]
segmento [1 2 3 ..., 2 2 2]这样类别属性已经转换成了数字,我们可以进行下一步了,正则化特征,选择特征。
3. 正则化特征,特征选择
然后,我们来到了栈模块(stack module),这里的栈不是模型栈而是特征栈。在经过上一步的处理后,我们得到了不同的特征。
根据你得到的是稠密特征还是稀疏特征,你可以使用numpy模块的hstack或者sparse hstack把所有特征存进一个栈。

如果还有其他处理过程,比如PCA或者特征选择,我们还可以使用FeatureUnion模块。本文后面会继续提到分解和特征选择。
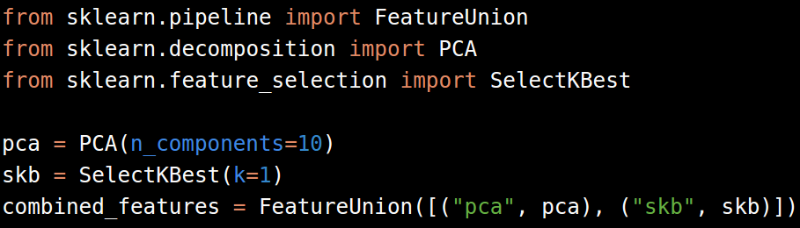
结果如下,
hstack: ['ind_empleado' 'pais_residencia' 'sexo' 'ind_nuevo' 'indrel' 'indext'
'conyuemp' 'canal_entrada' 'indfall' 'tipodom' 'nomprov'
'ind_actividad_cliente' 'segmento']
skb: SelectKBest(k=1, score_func=<function f_classif at 0x7fb3fc31cf50>)
combined features: FeatureUnion(n_jobs=1,
transformer_list=[('pca', PCA(copy=True, n_components=10, whiten=False)), ('skb', SelectKBest(k=1, score_func=<function f_classif at 0x7fb3fc31cf50>))],
transformer_weights=None)有了上面的特征,我们就可以开始应用机器学习模型了。现阶段,你只需要考虑基于树的模型就足够了。这些模型包括:
- 随机森林分类器 RandomForestClassifier
- 随机森林回归器 RandomForestRegressor
- ExtraTreesClassifier
- ExtraTreesRegressor
- XGBClassifier
- XGBRegressor
在直接使用上面的特征之前,首先需要进行正则化。对于使用线性模型而言,我们可以选择scikit-learn中的Normalizer或者StandardScaler。这些正则方法只针对稠密特征有效,在稀疏特征上不会给出好的结果。
假如上面的过程得到了一个“好的”模型,那我们可以继续优化超参数;假如没有得到
“足够好的”模型,我们可以通过下面的方法继续优化模型。
下一步包含分解方法:
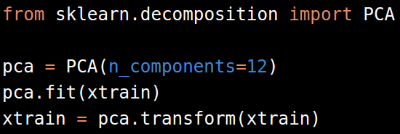
PCA
为了简单起见,我们不谈LDA和QDA变换。对高维数据,一般采用PCA算法分解数据。对图片数据,我们从10-15个components开始逐渐增加,直到结果质量充分提高;对其他类型数据,我们初始选择50-60个components。
SVD
对于文本数据,在文本转换成稀疏矩阵后,使用奇异值分解(Singular Value Decomposition, SVD)转换数据。Scikit-learn提供了一份SVD的变种算法TruncatedSVD。
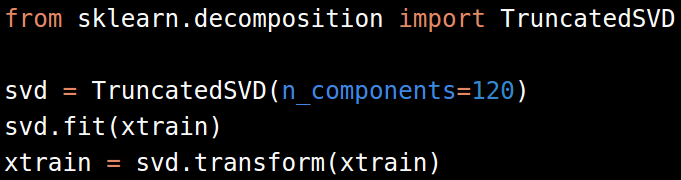
对于TF-IDF或者count向量化方法,SVD的components个数选择120-200之间一般是有效果的。更高的components个数会提高效果,但也需要更高的计算代价。
贪心特征选择
有多种方法达到特征选择的目的,其中最常见的一个是贪心特征选择(向前或向后)。在贪心特征选择中,我们选择一个特征,训练一个模型,然后在一项固定的指标上评估模型表现。然后我们一个一个地添加或者删除特征,记录每一步中模型的表现。最后选择让模型表现最好的特征集。贪心特征选择的一种实现,可以参考这里
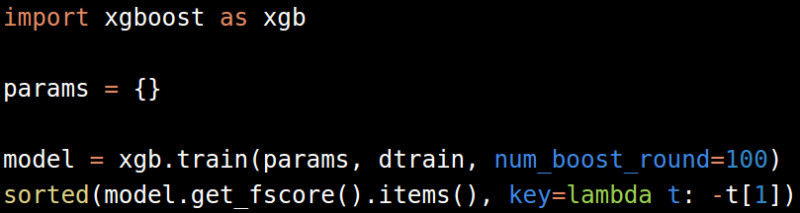
Gradient Boosting Machine
特征选择还可以通过Gradient Boosting Machine达到。推荐使用xgboost代替scikit-learn中的GBM实现,因为xgboost更快而且更加具有可伸缩性。
4. 模型选择,超参数优化
我们一般采用下面的算法选择机器学习模型:
- 分类
- 随机森林 Random Forest
- GBM
- 逻辑回归 Logistic Regression
- 朴素贝叶斯 Naive Bayes
- 支持向量机 Support Vector Machine
- k近邻 k-Nearest Neighbors
- 回归
- 随机森林 Random Forest
- GBM
- 线性回归 Linear Regression
- 岭回归 Ridge
- Lasso
- SVR
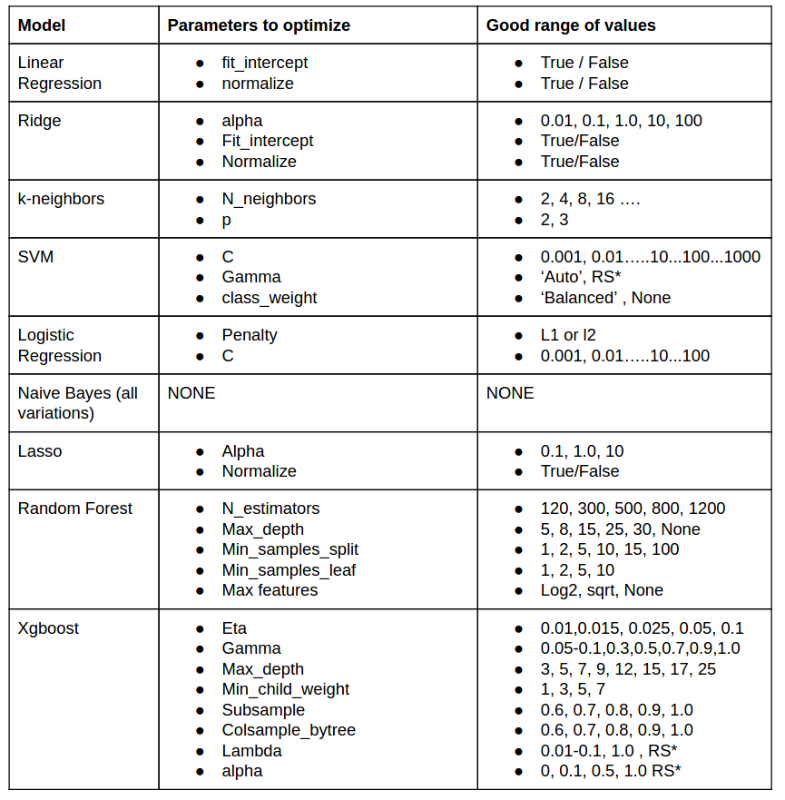
下面是作者给出他建议的模型和相对应的经验参数值,参数的选择经过时间和数据的积累。作者号称,上面的模型和参数组合已经超过了其他所有的模型。
5. 保存转换器
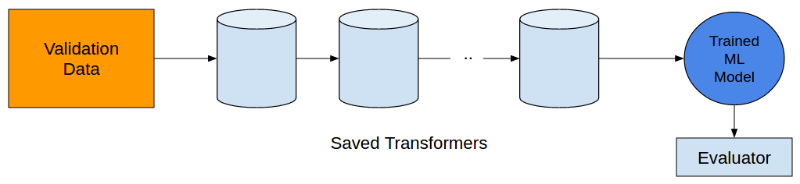
最后,记得保存转换器,在验证集应用训练出的模型。
三、总结
- 识别问题的类型,数据分割成两部分:训练集,验证集
- 识别数据中的变量,形成特征
- 正则化特征,选择特征
- 选择模型,优化超参数
- 保存转换器
作者 renqHIT
2016 年 11月 1日