python 抓取天涯帖子内容并保存
作者:大捷龙 csdn : http://blog.csdn.net/koanzhongxue
**
分析:天涯的帖子下载可以分为以下几个步骤
- 手动传入一个帖子首页的地址
- 打开文本
- 提取帖子标题
- 获取帖子的最大页数
- 遍历每一页,获得每条回复的是否是楼主、作者昵称、回复时间。
- 写入看文本
- 关闭文本
预备:
Python的文件操作:
一、打开文件
代码如下:
f = open(“d:\test.txt”, “w”)
说明:
第一个参数是文件名称,包括路径;第二个参数是打开的模式mode
‘r’:只读(缺省。如果文件不存在,则抛出错误)
‘w’:只写(如果文件不存在,则自动创建文件)
‘a’:附加到文件末尾
‘r+’:读写
二、读取内容
f.read(size)
参数size表示读取的数量,可以省略。如果省略size参数,则表示读取文件所有内容。
f.readline()
读取文件一行的内容
f.readlines()
读取所有的行到数组里面[line1,line2,…lineN]。在避免将所有文件内容加载到内存中,这种方法常常使用,便于提高效率。
三、写入文件
f.write(string) 将一个字符串写入文件,如果写入结束,必须在字符串后面加上”\n”,然后f.close()关闭文件
实战:
1 选取天涯帖子:《风云(中国第一本企业家自传)创业家园天涯论坛》
URL= http://bbs.tianya.cn/post-house-590038-1.shtml
2 打开帖子首页
url ='http://bbs.tianya.cn/post-enterprise-8487-1.shtml'
link = urllib2.urlopen(url)
html = link.read()
3 获取标题
HTML:
风云(中国第一本企业家自传)创业家园天涯论坛
#获取帖子的基本信息
#正则表达式,用于提取文章标题
gettitle = re.compile(r'<title>(.*?)</title>')
title = re.findall(gettitle,html)
4 获取最大页数
<strong>1</strong>
<a href="/post-enterprise-8487-2.shtml">2</a>
<a href="/post-enterprise-8487-3.shtml">3</a>
<a href="/post-enterprise-8487-4.shtml">4</a>
…
<a href="/post-enterprise-8487-354.shtml">354</a>
<a href="/post-enterprise-8487-2.shtml" class="js-keyboard-next">下页</a>
根据目标字符串写出正则表达式:
Python:
#正则表达式匹配HTML中的最大页数的信息。
getmaxlength = re.compile(r'<a href=".*?">(\d*)</a>\s*<a href=".*?"\s*class=.*?>下页</a>')
#用正则获取最大页数信息
maxlength = getmaxlength.search(html).group(1)5 获取发帖信息,是否是楼主、作者昵称、回复时间

根据目标字符串写出正则表达式:
Python:
getpagemsg = re.compile(r'<div class="atl-info">\s*<span>(.*?)<a href="http:.*uname="(.*)">.*\s*<span>时间:(.*?)</span>')
pagemsg = re.findall(getpagemsg,html)
6 获取每条回复的内容

根据目标字符串写出正则表达式:
Python:
gettext = re.compile(r'<div class="bbs-content">\s*([\S\s]*?)\s*</div>') #[\S\s]匹配任意字符
gettext1 = re.compile(r'<div class="bbs-content clearfix">\s*(.*?)\s*</div>')
text1 = re.findall(gettext1,html)
text = re.findall(gettext,html)7 获取下一页链接
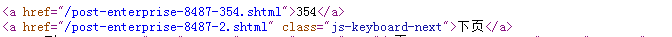
根据目标字符串写出正则表达式:
Python:
getnextpagelink = re.compile(r'<a href="(.*?)"\s*class.*?>下页</a>')
#获取帖子的下一页链接,读取页面内容
nextpagelink = 'http://bbs.tianya.cn'+getnextpagelink.search(html).group(1)
link = urllib2.urlopen(nextpagelink)
html = link.read()
8 完整的代码
#encoding=utf-8
#作者:大捷龙 csdn : http://blog.csdn.net/koanzhongxue
#http://bbs.tianya.cn/post-house-590038-1.shtml
#获取天涯的帖子内容
import urllib,urllib2,re
#url ='http://bbs.tianya.cn/post-house-590038-1.shtml'
url ='http://bbs.tianya.cn/post-enterprise-8487-1.shtml'
link = urllib2.urlopen(url)
html = link.read()
#获取帖子的基本信息
#正则表达式,用于提取文章标题
gettitle = re.compile(r'<title>(.*?)</title>')
title = re.findall(gettitle,html)
#正则表达式匹配HTML中的最大页数的信息。
getmaxlength = re.compile(r'<a href=".*?">(\d*)</a>\s*<a href=".*?"\s*class=.*?>下页</a>')
#用正则获取最大页数信息
maxlength = getmaxlength.search(html).group(1)
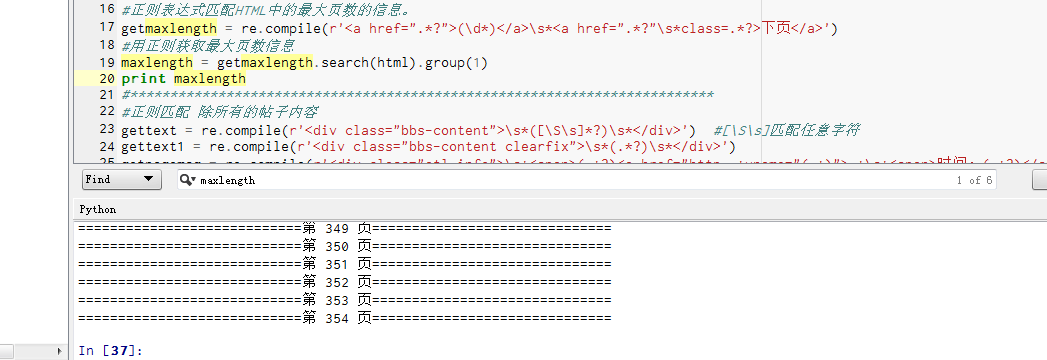
print maxlength
#*************************************************************************
#正则匹配 除所有的帖子内容
gettext = re.compile(r'<div class="bbs-content">\s*([\S\s]*?)\s*</div>') #[\S\s]匹配任意字符
gettext1 = re.compile(r'<div class="bbs-content clearfix">\s*(.*?)\s*</div>')
getpagemsg = re.compile(r'<div class="atl-info">\s*<span>(.*?)<a href="http:.*uname="(.*)">.*\s*<span>时间:(.*?)</span>')
getnextpagelink = re.compile(r'<a href="(.*?)"\s*class.*?>下页</a>')
#遍历每一页,获取发帖作者,时间,内容,并打印
filepath ='F:\Python_workspace\pic\\'+title[0]+'.txt' #utf-8编码,需要转为gbk .decode('utf-8').encode('gbk')
filehandle = open(filepath.decode('utf-8').encode('gbk'),'w')
#打印文章标题
filehandle.write(title[0].decode('utf-8','ignore').encode('gbk','ignore') +'\n')
str1 = ""
for pageno in range(1,int(maxlength)+1):
i = 0
filehandle.write('\n\n\n\n\n')
str1 = '============================'+'第 '+ str(pageno)+' 页'+'=============================='
print str1
filehandle.write(str1.decode('utf-8','ignore').encode('gbk','ignore') +'\n')
#获取每条发言的信息头,包含作者,时间
pagemsg = re.findall(getpagemsg,html)
if pageno is 1:
#获取第一个帖子正文
text1 = re.findall(gettext1,html)
#因为第一条内容由text1获取,text获取剩下的,所以text用i-1索引
#获取帖子正文
text = re.findall(gettext,html)
for ones in pagemsg:
if pageno > 1:
if ones is pagemsg[0]:
continue #若不是第一页,跳过第一个日期
if 'host' in ones[0]:
str1= '楼主:'+ ones[1] +' 时间:' + ones[2]
filehandle.write(str1.decode('utf-8','ignore').encode('gbk','ignore') +'\n')
else:
str1= ones[0] + ones[1] + ' 时间:' + ones[2]
filehandle.write(str1.decode('utf-8','ignore').encode('gbk','ignore') +'\n')
if pageno is 1: #第一页特殊处理
if i is 0:
str1= text1[0].replace('<br>','\n')
filehandle.write(str1.decode('utf-8','ignore').encode('gbk','ignore') +'\n')
else:
str1 = text[i-1].replace('<br>','\n')
filehandle.write(str1.decode('utf-8','ignore').encode('gbk','ignore') +'\n')
else: #非第一页的处理
try:
str1 = text[i].replace('<br>','\n')
filehandle.write(str1.decode('utf-8','ignore').encode('gbk','ignore') +'\n')
except IndexError,e:
print 'error occured at >>pageno:'+str(pageno)+' line:'+str(i)
print '>>'+text[i-1]
print e
i = i +1
if pageno < int(maxlength):
#获取帖子的下一页链接,读取页面内容
nextpagelink = 'http://bbs.tianya.cn'+getnextpagelink.search(html).group(1)
link = urllib2.urlopen(nextpagelink)
html = link.read()
filehandle.close()
9 见证效果