概述
在一般的项目开发中,对数据表的多表查询是必不可少的。而对于存在大量数据量的情况时(例如百万级数据量),我们就需要从数据库的各个方面来进行优化,本文就先从多表查询开始。其他优化操作,后续另外更新,敬请关注。
版权说明
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:Coding-Naga
发表日期: 2016年3月22日
链接:http://blog.csdn.net/lemon_tree12138/article/details/50921193
来源:CSDN
更多内容:分类 >> 数据库
数据背景
现假设有一个中学学校,学校中的年级有一年级、二年级、三年级,每个年级有两个班级。分别为101、102、201、202、301、302.
现在我们要为这个学校建立一个考试成绩统计系统。为此,我们对数据库的设计画了如下ER图:
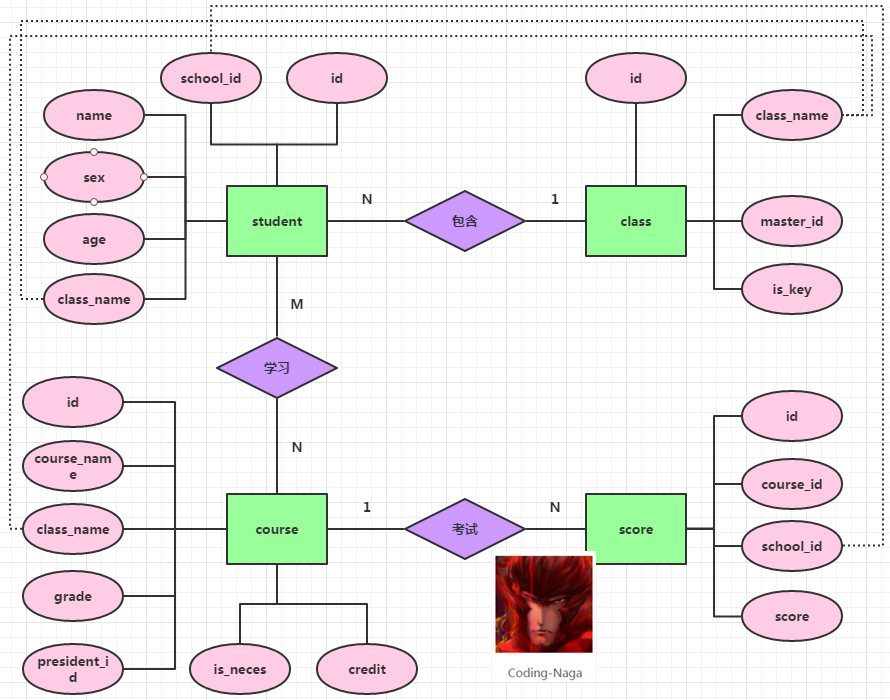
根据ER图,我们设计了数据表,结构如下:
class 班级表:
+------------+---------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| class_name | int(11) | NO | | NULL | |
| master_id | int(11) | YES | | NULL | |
| is_key | int(11) | NO | | NULL | |
+------------+---------+------+-----+---------+----------------+student 学生表:
+------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| school_id | int(11) | NO | | NULL | |
| name | varchar(30) | NO | | NULL | |
| sex | int(11) | NO | | NULL | |
| age | int(11) | NO | | NULL | |
| class_name | int(11) | NO | | NULL | |
+------------+-------------+------+-----+---------+----------------+course 课程表:
+--------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| course_name | varchar(10) | NO | | NULL | |
| grade | int(11) | NO | | NULL | |
| president_id | int(11) | YES | | NULL | |
| is_neces | int(11) | NO | | NULL | |
| credit | int(11) | NO | | NULL | |
| class_name | int(11) | YES | | NULL | |
+--------------+-------------+------+-----+---------+----------------+score 成绩表:
+-----------+---------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+---------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| course_id | int(11) | NO | | NULL | |
| school_id | int(11) | NO | | NULL | |
| score | int(11) | YES | | NULL | |
+-----------+---------+------+-----+---------+----------------+注:关于本文的数据库数据大家可以在文章最下方的相关下载中获取。资源链接中有两个版本的数据库,school.sql为初始数据库,school_2.sql为优化后的数据库。
连接(JOIN)简介
内连(INNER JOIN)
INNER JOIN 关键字在表中存在至少一个匹配时返回行。
我们也用下面的交集维恩图来描述内连操作:
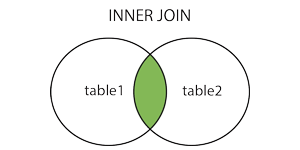
上面的维恩图只是表达了一个有限制情况(即存在JOIN ON),而对于没有约束的情况下,其实就是一个笛卡尔积运算。
*注:**INNER JOIN 与 JOIN 是相同的。一般情况下,在SQL语句中可以省略*INNER关键字。
左连接(LEFT JOIN)
LEFT JOIN 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
使用维恩图描述内连操作:
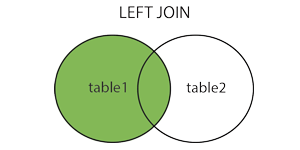
对于上面结果为 NULL的这一条,通过对实际测试的数据表进行操作,得到如下的测试结果:
+------------+-------+
| class_name | name |
+------------+-------+
| 202 | NULL |
| 301 | Bob |
| 302 | Alice |
+------------+-------+右连接(RIGHT JOIN)
RIGHT JOIN 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。
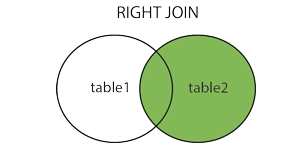
注:右连接可以理解成左连接的对称互补,详细说明可参见左连接。
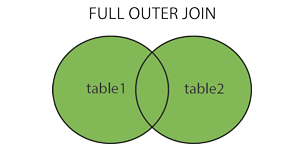
全连(FULL JOIN)
FULL OUTER JOIN 关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行.
FULL OUTER JOIN 关键字结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
联合(UNION)
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
MySQL的JOIN实现原理
在MySQL 中,只有一种Join 算法,就是大名鼎鼎的Nested Loop Join,他没有其他很多数据库所提供的Hash Join,也没有Sort Merge Join。顾名思义,Nested Loop Join 实际上就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有第三个参与Join,则再通过前两个表的Join 结果集作为循环基础数据,再一次通过循环查询条件到第三个表中查询数据,如此往复。
– 《MySQL 性能调优与架构设计》
多表查询实战
查询各个班级的班长姓名
优化分析
对于这个多表的查询使用where是可以很好地完成查询,而查询的结果从表面上看,完全没什么问题,如下:
+------------+---------+
| class_name | name |
+------------+---------+
| 101 | William |
| 102 | Peter |
| 201 | Judy |
| 202 | Polly |
| 301 | Grace |
| 302 | Sunny |
+------------+---------+可是,由于我们使用的是where,这个与内连接在有条件限制的情况下是一样的,其维恩图也可以一并参考。可是,如果现在我们假设,有一个新的班级303,或是这个303的班级暂时还没有班长。这个时候通过where就无法完成查询了。上面的结果中就已经很好地给出解释。
这个时候,我们就需要通过外连接中的左连接(如果采用右连接,那么相应的表位置也要进行替换)来进行查询了。在左连的查询中,因为是包含了”左表“的全部行,所以对于未选出班长的303来说,这个很有必要。采用左连操作的结果如下:
+------------+---------+
| class_name | name |
+------------+---------+
| 101 | William |
| 102 | Peter |
| 201 | Judy |
| 202 | Polly |
| 301 | Grace |
| 302 | Sunny |
| 303 | NULL |
+------------+---------+SQL展示
朴素的WHERE
SELECT cl.class_name, st.name
FROM class cl, student st
WHERE cl.master_id=st.school_id;INNER JOIN
SELECT cl.class_name, st.name
FROM class cl
JOIN student st
ON cl.master_id=st.school_id;LEAF JOIN
SELECT cl.class_name, st.name
FROM class cl
LEFT JOIN student st
ON cl.master_id=st.school_id;RIGHT JOIN
SELECT cl.class_name, st.name
FROM student st
RIGHT JOIN class cl
ON cl.master_id=st.school_id;利用 EXPLAIN 检查优化器
通过EXPLAIN我们分别检查上面WHERE语句和LEFT JOIN的优化过程。结果如下:
WHERE
+----+-------------+-------+------+---------------+------+---------+------+------+--------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+--------------------------------+
| 1 | SIMPLE | cl | ALL | NULL | NULL | NULL | NULL | 7 | |
| 1 | SIMPLE | st | ALL | NULL | NULL | NULL | NULL | 301 | Using where; Using join buffer |
+----+-------------+-------+------+---------------+------+---------+------+------+--------------------------------+LEFT JOIN
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | cl | ALL | NULL | NULL | NULL | NULL | 7 | |
| 1 | SIMPLE | st | ALL | NULL | NULL | NULL | NULL | 301 | |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+对于上面的两个结果,我们可以看到有一个很明显的区别在于Extra。
Using where说明进行了where的过滤操作,Using join buffer说明进行join缓存。关于这两者的说明可参考这里。
从上面的结果中,还可以看到每种情况的两种查询操作都是经过了全表扫描。而这对于大量数据而言是很不利的。
现在,我们可以为被驱动表的join字段添加索引,再对其进行EXPLAIN检查。
添加索引
ALTER TABLE student ADD INDEX index_school_id (school_id);通过EXPLAIN我们分别检查上面WHERE语句和LEFT JOIN的优化过程。结果如下:
WHERE
+----+-------------+-------+------+-----------------+-----------------+---------+---------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+-----------------+---------+---------------------+------+-------+
| 1 | SIMPLE | cl | ALL | NULL | NULL | NULL | NULL | 7 | |
| 1 | SIMPLE | st | ref | index_school_id | index_school_id | 4 | school.cl.master_id | 1 | |
+----+-------------+-------+------+-----------------+-----------------+---------+---------------------+------+-------+LEFT JOIN
+----+-------------+-------+------+-----------------+-----------------+---------+---------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+-----------------+---------+---------------------+------+-------+
| 1 | SIMPLE | cl | ALL | NULL | NULL | NULL | NULL | 7 | |
| 1 | SIMPLE | st | ref | index_school_id | index_school_id | 4 | school.cl.master_id | 1 | |
+----+-------------+-------+------+-----------------+-----------------+---------+---------------------+------+-------+现在,可以很明显地看出rows列的数值,在被驱动表处都是1,这大降低了查询的复杂度。而且对于type列,也从一开始的ALL变成了现在的ref。还有一些其他的列也被修改了。关于type字段的说明可参考这里。
查询番外
根据学号查询一个学生的成绩单
WHERE 查询
EXPLAIN SELECT st.name, co.course_name, sc.score
FROM student st, score sc, course co
WHERE sc.school_id=st.school_id
AND co.id=sc.course_id
AND st.school_id=100005;JOIN 查询
EXPLAIN SELECT st.name, co.course_name, sc.score
FROM student st
JOIN score sc ON sc.school_id=st.school_id
JOIN course co ON co.id=sc.course_id
WHERE st.school_id=100005;结果
+----+-------------+-------+--------+---------------------------------------+--------------------+---------+---------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------------------------------+--------------------+---------+---------------------+------+-------+
| 1 | SIMPLE | st | ref | index_school_id | index_school_id | 4 | const | 1 | |
| 1 | SIMPLE | sc | ref | index_school_id_sc,index_course_id_sc | index_school_id_sc | 4 | const | 3 | |
| 1 | SIMPLE | co | eq_ref | PRIMARY | PRIMARY | 4 | school.sc.course_id | 1 | |
+----+-------------+-------+--------+---------------------------------------+--------------------+---------+---------------------+------+-------+优化总结
- 对于要求全面的结果时,我们需要使用连接操作(LEFT JOIN / RIGHT JOIN / FULL JOIN);
- 不要以为使用MySQL的一些连接操作对查询有多么大的改善,核心是索引;
- 对被驱动表的join字段添加索引;
Ref
- 《高性能MySQL(第3版)》
- 《MySQL 性能调优与架构设计》
- SQL教程 | 菜鸟教程
- http://bbs.chinaunix.net/thread-4069615-1-1.html
- http://s.petrunia.net/blog/?p=18