摘要陈硕老师的“Linux多线程服务端编程 - 使用muduo C ++网络库”12种并发服务器模型,特整理于此,备学习使用。
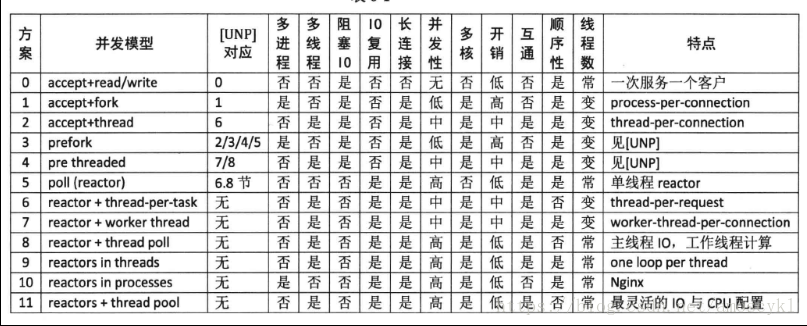
方案0:接受+读/写一次服务一个客户
这个不是并发服务器。
方案1:接受+ fork()进程每个连接
这个是传统的UNIX并发网络编程方案,也叫过程每次connextion。这种方案适合并发连接数不大的情况。“计算响应的工作量大于叉()的开销”每一个连接开启一个进程来处理。这种方案适合长连接,不适合短连接。
方案2:接受+线程每个连接线程
同样适合长连接,每一个连接开启一个线程,相对于方案1来说,开销是小了一点,但是对于多个并发连接,也是不合适的,线程数目太多,线程上下文切换也是需要很多时间的!
方案3:perfork()在UNP中存在
方案4:预先在UNP中存在
方案3和方案4是分别对方案1和方案2的改进
到目前为止,的上述方案都是阻塞式网络编程,程序流程通常阻塞在读()上,等待数据到达。
比较好的方法就是IO多路复用,也就是选择/轮询/ epoll / kqueue这一系列的“多路选择器”。让一个程序线程(控制线程)控制多个连接.IO复用其实复用的不是IO连接,而是复用线程。
Doug Schmidt指出,其实网络编程中有很多是事务性的工作,可以提取为公用的框架或库,而用户只需要填上关键的业务代码,并将回调注册到框架中,就可以实现完整的网络服务,这也是反应器模式的主要思想。
单线程Reactor的程序执行顺序是这样的,在没有事件的时候,线程等待在seleect/poll/epoll_wait等函数上。事件到达后由网络库处理IO,再把消息通知(回调)客户端代码。Reactor事件循环所在的线程通常叫IO线程。通常由网络库负责读写socket,用户代码负责解码、计算、编码。

注意由于只有一个线程,因此事件是顺序处理的,一个线程同时只能做一件事情。事件的优先级不能保证,因为从poll返回之后到下一次调用poll进入等待之前这段时间内,线程不会被其他链接上的数据或事件抢占。如果我们想延迟计算(把compute()推迟100ms),那么也不能用sleep()之类的阻塞调用,而应该注册超时回调,以避免阻塞当前IO线程。(理解的整个过程是这样的:poll返回以后,会对相应的套接字上的事件做相应处理,把得到的数据进程compute处理,然后再回应对端,如果在进行处理的过程中有别的套接字上存在时间,那么这个事件不会得到立即相应,而是等到回应结束再次进入poll才能得到回应。后半句的意思,如果在poll返回之后准备处理事件的时候,用户想让compute延迟100ms,那么不能使用sleep()这种阻塞式系统调用,应该注册延迟回调,这样就不会阻塞当前线程。这样的话,注册延迟以后,就可以继续做下面的操作,而不是等待100ms的事件耗尽,等到100ms时间到,计算操作就会被激活。)
方案5:poll(reactor) 单线程rector
这个方案就是上面的。这种方案的优点是由网络库搞定数据收发,程序之关心业务逻辑;缺点:适合IO密集的应用,不太适合CPU密集的应用,因为较难发挥多核的威力。
在使用非阻塞IO+事件驱动方式编程的时候,一定要注意避免在事件回调中执行耗时的操作,包括阻塞IO等,否则会影响程序的相应。
方案6:rector+thread-per-task thread-per-request(每一个请求一个线程)
这是一个过渡方案,需要处理数据请求进行处理时,不在Reactor线程计算,而是创建一个新线程计算,可以充分利用多核CPU。这是非常初级的多线程应用,因为它为每个请求(而不是每个连接)创建一个新线程。这个开销可以用线程池来避免,就是方案8.这个方案的缺点就是无序性,即同时创建多个线程去计算同一个连接上收到的多个请求,那么算出结果的次序是不确定的。
方案7:reactor+worker thread 特点:worker-thread-per-connection
为了让返回结果的顺序确定,我们可以为每个连接创建一个计算线程,每个连接上的请求固定发给同一个线程去算。先到先得。这也是一个过渡方案,因为并发连接数受限于线程数目,这个方案或许不如直接使用阻塞IO的thread-per-connection方案2
方案8: reactor+thread poll 主线程IO,工作线程计算
为了弥补方案6中为每个请求创建线程的缺陷,可以使用固定大小线程池,全部的IO工作都在一个Reactor线程完成,而计算任务交给thread poll。如果计算任务彼此独立,而且IO的压力不大,那么这种方案非常适用。
如果计算任务彼此独立,而且IO的压力不大,那么这种方案非常适用。
在这个方案中,thread poll只相当于处理操作。
这个方案和方案5的单线程Reactor相比变化不大,只是把计算和发回响应的部分做成一个函数,然后交给ThreadPool去做。
线程池的另外一个作用是执行阻塞操作。比如有的数据库的客户端指提供同步访问,那么可以把数据库查询放到线程池中,可以避免阻塞IO线程,不会影响其他客户连接(在方案5中是不可以调用阻塞函数的)
缺点是:如果IO的压力比较大,一个Reactor处理不过来,可以尝试方案9,它采用多个Reactor来分担负载。
方案9:reactors in threads one loop per thread(muduo) (一个线程管理一个连接)
方案的特点是one loop per thread,有一个main reactor负载accept连接,然后把连接挂载某个sub reactor(采用round-robin的方式来选择sub reactor),这样改连接的所用操作都在那个sub reactor所处的线程中完成。多个连接可能被分派到多个线程中,以充分利用CPU。新连接被挂载到sub reactor上,在这个sub reactor上进行新连接上数据的计算和回应。
Reactor poll的大小是固定的,根据CPU的数目确定。也就是说线程池是固定的。并且一个连接完全由一个线程管理,那么请求的顺序性有保证。
一个基本IO线程负责接受新的连接,接收到新的连接以后,使用轮询的方式在reactor pool中找到合适的子反应堆将这个连接挂载到上去,一个这个连接上的所有任务都在这个子反应器上完成。

方案10:每个过程一个循环的过程中的反应器(nginx)(一个线程管理一个连接)
如果连接之间无交互,这种方案也是很好的选择。工作进程之间相互独立。
方案11:reactor +线程轮询
方案8和方案9的混合,即使用多个反应器来处理IO,又使用线程池来处理计算。这种方案适合既有突发IO(利用多线程处理多个连接上的IO),又有突发计算的应用(利用线程池把一个连接上的计算任务分配给多个线程去做)

---------------------
作者:amoscykl
来源:CSDN
原文:HTTPS://blog.csdn.net/amoscykl/article/details/82988495
版权声明:本文为博主原创文章,转载请附上博文链接!