版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wangwei_620/article/details/82907962
一.下载概述和技术分析
首先我们通过浏览器点击要下载的文件(注意这个文件可以是任意格式),然后服务器通过获取下载文件名,然后从服务器内部进行查找,边读边写到浏览器,指定下载路径,这个中间涉及到两个头,一个流,不同的浏览器的解码方式不同,我们必须设置不同浏览器的编码,在这我们是通过底层流的方式进行下载文件的.
二.代码实现
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URLEncoder;
@WebServlet(name = "DownloadServlet",urlPatterns = "/download")
public class DownloadServlet extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("UTF-8"); // 处理post请求乱码问题
this.doGet(request, response); // 主要加这一句
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/html;charset=UTF-8"); // 处理响应乱码问题:字节流需getBytes("UTF-8")
//1.获取要下载的文件的名称 11.jpg
String filename = request.getParameter("filename");
//2.读取要下载的文件
//a.获取文件在服务器上的完整路径
ServletContext context = getServletContext();
String realPath = context.getRealPath("/download/" + filename);
System.out.println("文件在服务器上的完整路径:"+realPath);
//b.读取文件 (输入流)
FileInputStream in = new FileInputStream(realPath);
//3.设置两个头
//a.设置响应文件的mime类型头
String mimeType = context.getMimeType(filename);
response.setContentType(mimeType);
//b.设置文件下载专用头
//如何解决处理下载文件中的中文乱码问题
//浏览器指定的解码方式我们就用,指定的编码方式
filename = URLEncoder.encode(filename,"utf-8");
System.out.println(filename);
response.setHeader("content-disposition","attachment;filename="+filename);
//4.获取输出流,将文件输出给浏览器.
ServletOutputStream out = response.getOutputStream();
int len = 0;
byte[] b = new byte[1024];
while ((len=in.read(b))!=-1){
out.write(b,0,len);
}
//5.关流
out.close();
in.close();
}
}
index.html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>定时刷新</title>
</head>
<body>
<a href="download?filename=11.jpg">美女下载</a><br>
<a href="download?filename=鲁金环.jpg">女朋友下载</a><br>
</body>
</html>三.下载中问题分析
- 首先在下载中如果有中文,谷歌浏览器是不支持解码的,因为谷歌默认是utf-8进行解码的,如果下载中有中文,就会出现乱码,英文名字的话没啥问题
- 如果是火狐浏览器下载的,又会出现问题,因为获取默认是通过BASE64进行解码的,

//如何解决处理下载文件中的中文乱码问题
//浏览器指定的解码方式我们就用,指定的编码方式
// filename = URLEncoder.encode(filename,"utf-8");
// System.out.println(filename);
//火狐浏览器
//通过工具类实现
String agent = request.getHeader("user-agent");
filename = DownLoadUtils.getName(agent, filename);工具类的实现方式如下,通过判断是否含有FireFox
import sun.misc.BASE64Encoder;
import java.io.UnsupportedEncodingException;
import java.net.URLEncoder;
public class DownLoadUtils {
public static String getName(String agent, String filename) throws UnsupportedEncodingException {
if (agent.contains("Firefox")) {
// 火狐浏览器
BASE64Encoder base64Encoder = new BASE64Encoder();
filename = "=?utf-8?B?" + base64Encoder.encode(filename.getBytes("utf-8")) + "?=";
} else {
// 其它浏览器
filename = URLEncoder.encode(filename, "utf-8");
}
return filename;
}
}

3.最变态的就是IE浏览器,直接不能发送中文给服务器出现400错误
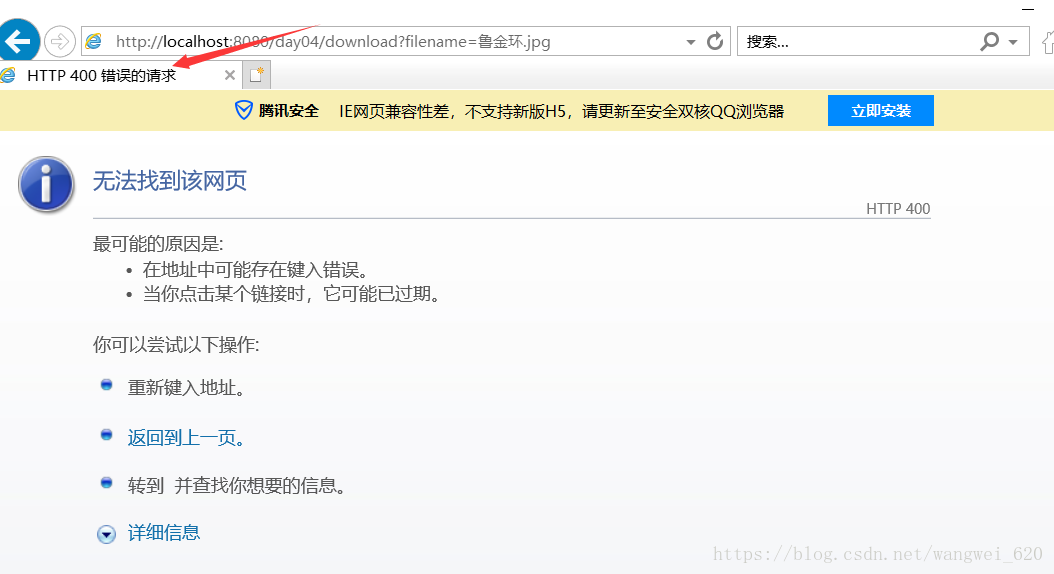
在index.html文件中通过js实现对IE浏览器中文请求的编码.
<script>
function isIE(){
//获取当前浏览器相关信息
var explorer = window.navigator.userAgent.toLowerCase() ;
//判断是否是ie浏览器
if (explorer.indexOf("msie") >= 0 || explorer.indexOf("rv:11.0) like gecko") >=
0) {
return true;
}else {
return false;
}
}
window.onload = function () {
if(isIE()){
//在是IE浏览器的情况下,对中文请求参数编码
var str = document.getElementById("ww").href;
str = encodeURI(str);
document.getElementById("ww").href = str;
}
};
</script>然后就可以通过IE下载带有中文字符的文件了
扫描二维码关注公众号,回复:
3865899 查看本文章

