一 分词
支持三种分词模式:
1.精确模式,试图将句子最精确地切开,适合文本分析;
2.全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;
3.搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
def test_cut(sentence):
"""
测试分词三种模式
:param sentence:
:return:
"""
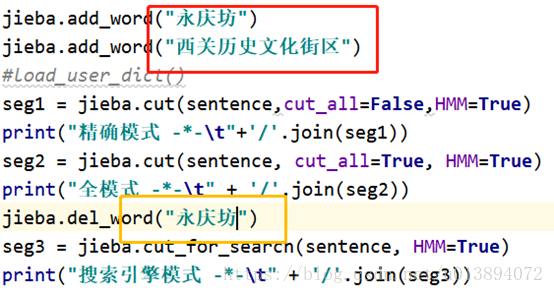
seg1 = jieba.cut(sentence,cut_all=False,HMM=True)
print("精确模式 -*-\t"+'/'.join(seg1))
seg2 = jieba.cut(sentence, cut_all=True, HMM=True)
print("全模式 -*-\t" + '/'.join(seg2))
seg3 = jieba.cut_for_search(sentence, HMM=True)
print("搜索引擎模式 -*-\t" + '/'.join(seg3))
分别支持简体和繁体中文的分词
但可以看出,默认字典下 繁体字支持的不够好。
可以导入自定义词典


def load_user_dict():
"""
导入相应的自定义词典,必须是UTF-8的编码
:return:
"""
jieba.load_userdict("./config/newdict.txt")
还可以自己在代码中动态在词典中添加词、删除词


二 抽取关键词
主要有两种方法
依据TFIDF抽取
def tfidf_extract(content):
keywords = jieba.analyse.extract_tags(content, topK=20, withWeight=True, allowPOS=())
# 访问提取结果
for item in keywords:
# 分别为关键词和相应的权重
print(item[0], item[1])
withWeight 表示是否包含权重,allowPOS表示允许通过哪几种词性的词,空表示全通过。POS标准与ictclas标准基本一致(后面附上)

TextRank抽取
def textrank_extract(content):
keywords = jieba.analyse.textrank(content, topK=20, withWeight=True, allowPOS=('ns', 'nr', 'vn', 'v'))
for item in keywords:
# 分别为关键词和相应的权重
print(item[0], item[1])
textrank的allowPOS默认包含('ns', 'n', 'vn', 'v')
关键词抽取可以自定义idf文件及停用词文件

def load_user_extract_file():
jieba.analyse.set_idf_path("./files/idf.utf8")
jieba.analyse.set_stop_words("./config/stopwords.txt")
并行分词
原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升
基于python自带的multiprocessing模块,目前暂不支持 Windows。
#开启并行分词
jieba.enable_parallel(4)
#关闭并行分词
jieba.disable_parallel()
词性标注
jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的jieba.Tokenizer 分词器

用法示例
def do_cut_pos(sentence):
jieba.posseg.POSTokenizer()
sentence_seg=jieba.posseg.cut(sentence.strip(),)
outstr = ''
for seg in sentence_seg:
outstr += '{}/{},'.format(seg.word,seg.flag)
return outstr

附:POS表(ICTCLAS)与 jieba 中的POS基本一致
1.名词(1个一类,7个二类,5个三类)
名词分为以下子类:
n名词
nr人名
nr1汉语姓氏
nr2汉语名字
nrj日语人名
nrf音译人名
ns地名
nsf音译地名
nt机构团体名
nz其它专名
nl名词性惯用语
ng名词性语素
2.时间词(1个一类,1个二类)
t时间词
tg时间词性语素
3.处所词(1个一类)
s处所词
4.方位词(1个一类)
f方位词
5.动词(1个一类,9个二类)
v动词
vd副动词
vn名动词
vshi动词“是”
vyou动词“有”
vf趋向动词
vx形式动词
vi不及物动词(内动词)
vl动词性惯用语
vg动词性语素
6.形容词(1个一类,4个二类)
a形容词
ad副形词
an名形词
ag形容词性语素
al形容词性惯用语
7.区别词(1个一类,2个二类)
b区别词
bl区别词性惯用语
8.状态词(1个一类)
z状态词
9.代词(1个一类,4个二类,6个三类)
r代词
rr人称代词
rz指示代词
rzt时间指示代词
rzs处所指示代词
rzv谓词性指示代词
ry疑问代词
ryt时间疑问代词
rys处所疑问代词
ryv谓词性疑问代词
rg代词性语素
10.数词(1个一类,1个二类)
m数词
mq数量词
11.量词(1个一类,2个二类)
q量词
qv动量词
qt时量词
12.副词(1个一类)
d副词
13.介词(1个一类,2个二类)
p介词
pba介词“把”
pbei介词“被”
14.连词(1个一类,1个二类)
c连词
cc并列连词
15.助词(1个一类,15个二类)
u助词
uzhe着
ule了喽
uguo过
ude1的底
ude2地
ude3得
usuo所
udeng等等等云云
uyy一样一般似的般
udh的话
uls来讲来说而言说来
uzhi之
ulian连(“连小学生都会”)
16.叹词(1个一类)
e叹词
17.语气词(1个一类)
y语气词(deleteyg)
18.拟声词(1个一类)
o拟声词
19.前缀(1个一类)
h前缀
20.后缀(1个一类)
k后缀
21.字符串(1个一类,2个二类)
x字符串
xx非语素字
xu网址URL
22.标点符号(1个一类,16个二类)
w标点符号
wkz左括号,全角:(〔[{《【〖〈半角:([{<
wky右括号,全角:)〕]}》】〗〉半角:)]{>
wyz左引号,全角:“‘『
wyy右引号,全角:”’』
wj句号,全角:。
ww问号,全角:?半角:?
wt叹号,全角:!半角:!
wd逗号,全角:,半角:,
wf分号,全角:;半角:;
wn顿号,全角:、
wm冒号,全角::半角::
ws省略号,全角:………
wp破折号,全角:——--——-半角:-------
wb百分号千分号,全角:%‰半角:%
wh单位符号,全角:¥$£°℃半角:$