计算机能识别的只有1和0,也就是二进制,而1和0可以表达出全世界的所有文字和语言符号。
我们人类采用的是十进制算术法,主要原因是因为我们有10个手指头。如果我们只有2个手指头的话,我们就会用二进制计数,就会逢二进一,那可能是这样计数的:1,10,11,20,21,30,31,40。。。。。。其中1代表十进制中的1,10代表10进制中的2,11代表十进制中的3,20代表10进制中的4。。。。。。不过这样太麻烦了,我们可以用纯2进制表达,因为是逢二进一,所以除第一位外,每一位肯定是前一位的两倍。 比如1在二进制中还是用1表示;2在二进制中用10表示,其中1是2的一次方;3在二进制中用11表示;4用100表示,5用101表示。。。。。。从第一位开始的数字(1或0)乘以2的0次方,然后依次是乘以2的1次方,2次方,3次方直到无限大,得出的数就是十进制。所以,虽然电脑只认识0和1,但是可以表达任何数字。
那如何表达文字和符号呢?这就涉及到字符编码了,字符编码强行将每一个字符对应一个十进制数字,再将十进制数字转换成计算机理解的二进制,而计算机读到这些1和0之后就会显示出对应的文字或符号。下面是ASCII(美国信息交换标准代码)
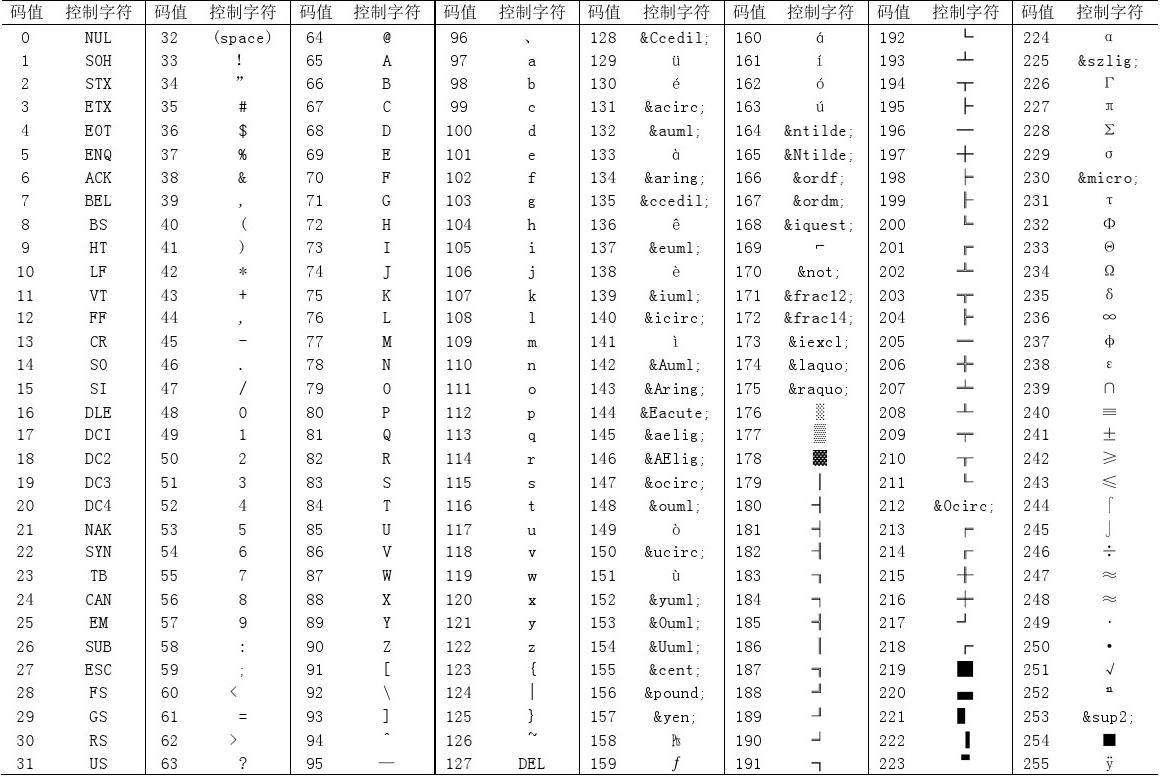
可以看到,255个就够用了,因为美国是用字母的,那么如何让计算机去断字呢?要知道,计算机读的一堆二进制数字是没有空格的。解决办法是用8个二进制代表一个字母或符号,因为8个二进制可以表达的最大数是255,正好用8个二进制就能表示了,那干脆所有的都用二进制表示吧。
那你老美的编码问题解决了,我们中国呢?中国文化博大精深,我们可以有上万个汉字呢。于是我们于1980年推出了自己的GB2312编码,支持常用的汉字。后来又相继推出了 GBK1.0和 GB18030,简单说后来推出的就是支持更多的汉字,而且支持少数民族文字和日韩里面的所有汉字。其他国家也纷纷推出了自己国家的字符编码。那么问题来了,如果把一个国家出的软件,装到另一个国家的操作系统里面,由于编码不同,就会出现一些乱七八糟的东西,简称乱码。
为了解决这个问题,ISO(国际标准化组织)于推出了Unicode,也就是万国码。在万国码中,每个字符用16个二进制来表示。按理说,这个问题为完美解决了,但是老美不干了,我们以前用8个二进制就能表示的,你现在让我们用16个二进制来表示,那不是白白浪费空间吗。为了安抚老美,utf-8诞生了。 UTF-8,是对Unicode编码的压缩和优化,简单说就是对ASCII码的内容用1字节保存,欧洲的字符用2个字节保存,东亚的字符用3个字节保存. 现在世界上使用最广泛的编码。不过这样咱们吃亏了啊,咱们以前是用2个字节的。
在操作系统方面windows中文版默认是用GBK编码,Mac OX和linux是用utf-8
python2默认是用ASCII编码,不过到了python3默认就用utf-8了。不过python2可以在代码的第一行加上如下声明,这样就会用utf-8去解码了。
#! -*- coding: utf-8 -*- #!encoding :utf-8