上一篇介绍了从数据角度出发,如果去处理不平衡问题,主要是通过过采样和欠采样以及它们的改进方式。
本篇博客,介绍不平衡问题可以采样的算法。
一、代价敏感学习
在通常的学习任务中,假定所有样本的权重一般都是相等的,或者说误分类成本是相同的。但是在大多数实际应用中,这种假设是不正确的。
最简单的例子就是在医疗中的癌症诊断,产生的误判导致的过晚的治疗将会危及患者生命;另外还有在风控领域,将一个盗刷行为判定为正常行为会比将正常行为判断为盗刷行为造成的损失要大的多。
因此所谓代价敏感学习主要考虑的是在分类问题中,不同的类别的样本在分类错误时导致不同的误分类成本时如何去训练模型。
通常,不同的代价被表示成为一个N×N的矩阵Cost中,其中N 是类别的个数。Cost[i, j]表示将一个i 类的对象错分到j 类中的代价。代价敏感分类就是为不同类型的错误分配不同的代价,使得在分类时,高代价错误产生的数量和错误分类的代价总和最小。

基于以上代价矩阵,代价敏感学习方法主要有以下三种实现方式,分别是:
1.从学习模型出发,主要是对算法的改进,使之能适应不平衡数据下的学习,如感知机,支持向量机,决策树,神经网络等分别都有其代价敏感的版本。以代价敏感的决策树为例,可从三个方面对其进行改进以适应不平衡数据的学习,这三个方面分别是决策阈值的选择方面、分裂标准的选择方面、剪枝方面,这三个方面中都可以将代价矩阵引入。
2.从贝叶斯风险理论出发,把代价敏感学习看成是分类结果的一种后处理,按照传统方法学习到一个模型,以实现损失最小为目标对结果进行调整,优化公式如下。此方法的优点在于它可以不依赖所用具体的分类器,但是缺点也很明显它要求分类器输出值为概率。

3.从预处理的角度出发,将代价用于权重的调整,使得分类器满足代价敏感的特性。其代表的算法是基于代价敏感的AdaCost算法。
下面具体介绍AdaCost算法,首先回顾一下AdaBoost 算法。Adaboost算法通过反复迭代,每一轮迭代学习到一个分类器,并根据当前分类器的表现更新样本的权重,其更新策略为正确分类样本权重降低,错误分类样本权重加大,最终的模型是多次迭代模型的一个加权线性组合,分类越准确的分类器将会获得越大的权重。具体算法如下:

而AdaCost算法修改了Adaboost算法的权重更新策略,其基本思想是对于代价高的误分类样本大大地提高其权重,而对于代价高的正确分类样本适当地降低其权重,使其权重降低相对较小。总体思想是代价高样本权重增加得大降低得慢。其样本权重按照如下公式进行更新。
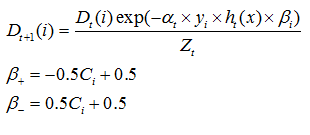
参考文献: