本文分析Map及它的三个具体实现类HashMap。
首先先看Map接口的注释,总结如下:
1:Map是一个将键映射到值的对象,是以键值对(key-value)的方式存储的,一个键最多映射一个值,但是一个值可以对应 多个键,所以Map中键是不允许重复的,这个在下面存储的时候会做详细分析。
2:与其说Map是个接口,其实它更像是一个抽象类,因为里面包含了大量的内部实现,详细可以看代码了解。
3:它有三个主要的实现类HashMap、TreeMap、HashTable。
首先看一下它的属性:

1:DEFAULT_INITIAL_CAPACITY:代表HashMap初始容量为16,之后扩容都是之前的两倍。
2:MAXIMUM_CAPACITY:代表最大容量为2的30次方。
3:DEFAULT_LOAD_FACTOR:代表的是默认的装载因子,装载因子的计算方式是,size/capacity既存储对象的值/容量。
4:TREEIFY_THRESHOLD:代表当链表长度达到8时会自动转化为红黑树。
5:UNTREEIFY_THRESHOLD:链表长度小于6,红黑树会转化为链表。
6:MIN_TREEIFY_CAPACITY:在转变成树之前,还会有一次判断,只有键值对数量大于 64 才会发生转换。这是为了避免在哈希表建立初期,多个键值对恰好被放入了同一个链表中而导致不必要的转化。
前面说到过,HashMap底层是一个哈希表,但是在jdk1.8之后变成了数组+链表+红黑树的结构,现在我们就来着重分析HashMap的put()方法:
HashMap在执行put操作的时候,分为三种情况
1:首先会调用key值的hashCode()方法得到哈希值,并通过哈希算法转化为对应数组的下标,如果数组下标不存在元素,则直接把key跟value封装成一个entry对象存到对应下标下面:
2:第二种情况是数组下标已经存在数据,则调用key值的equals()方法,判断key值是否相等,如果相等,则用新的value代替旧的value。
3:如果调用key值的equals()方法返回false,则这种情况就是我们常说的哈希碰撞,碰到这种情况的话,HashMap是怎么解决的呢?这就要用到哈希表的另一个数据结构链表了,如果出现这种情况,会把key跟value封装成一个entry存到链表的头节点,完成对象的存储,当链表长度超过阈值(8)时,链表会转化为红黑树,提高检索效率。
所以,如果HashMap不重写hashCode()方法的话就是一个纯数组,如果在重写时返回一个固定值,则就是一个纯链表。
接下来来看下它的构造函数
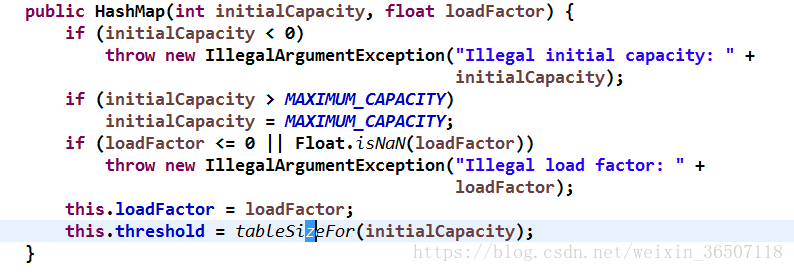
第一段initialCapacity < 0是判断初始化容量是否合理,第二段initialCapacity > MAXIMUM_CAPACITY是初始容量不能大于最大值,第三段loadFactor <= 0 || Float.isNaN(loadFactor)是判断加载因子是否合理,来看最后一段this.threshold = tableSizeFor(initialCapacity),threshold是调整大小的下一个大小值(容量*负载因子),既每次扩容之后的阈值大小,当size大于这个阈值时,hashMap会自动扩容,我们来看看tableSizeFor()方法,

这个方法返回的是大于入参,并最接近目标参数的2的整数次方的数,这里threshold是作为阈值存在的(最小值为1),当存储数据的量达到阈值时,HashMap会调用resize()方法进行扩容
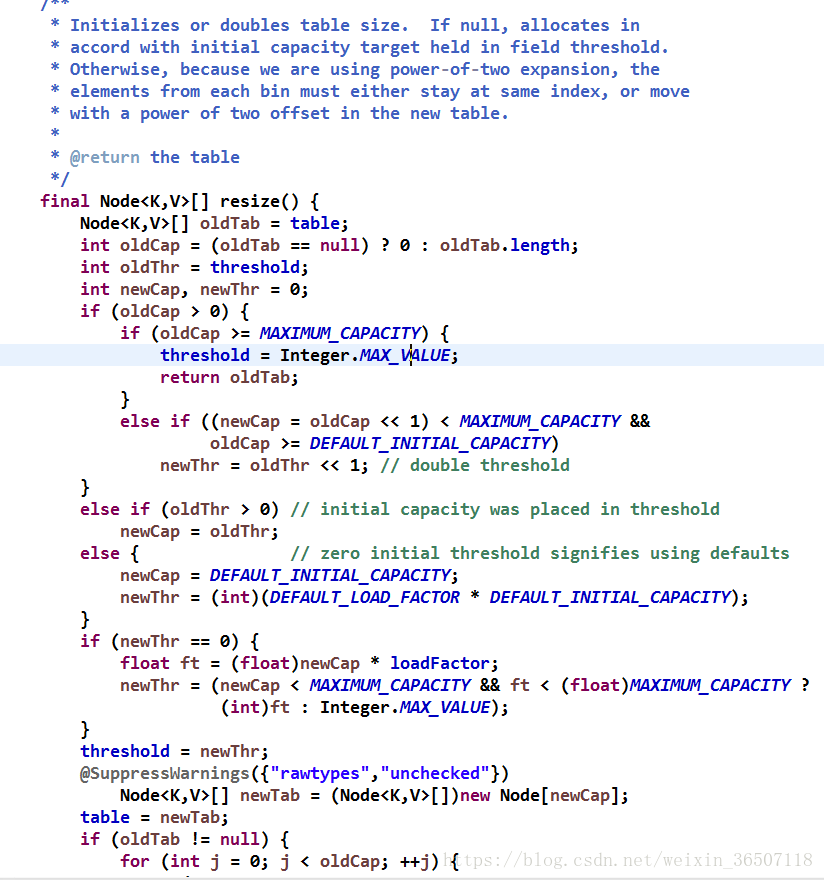
我们一段一段的分析:
oldCap、oldThr、newCap、newThr分别代表老的容量、老的阈值、新的容量和新的阈值。

当老容量大于最大值时,阈值也设为最大值。

如果老容量的两倍小于最大容量且老容量大于默认初始化容量时,新的阈值等于老的阈值的两倍,这里可以看出,一旦扩容,阈值是两倍两倍的增长的。

当老阈值大于0时,新容量等于老的阈值,这种情况,一般是初始化HashMap的时候给定容量为0,因为阈值最小是1,所以扩容时,容量会从0开始加(注意,当给定容量后,hashMap将不再使用默认大小16),这里有个值得注意的地方,当你使用给定容量的构造函数创建hashMap,并给定容量是0时,第一次put的时候,扩容并非为上述所示扩容容量为1,而是2即二进制0000000000000010,原因是什么我们来看一下。

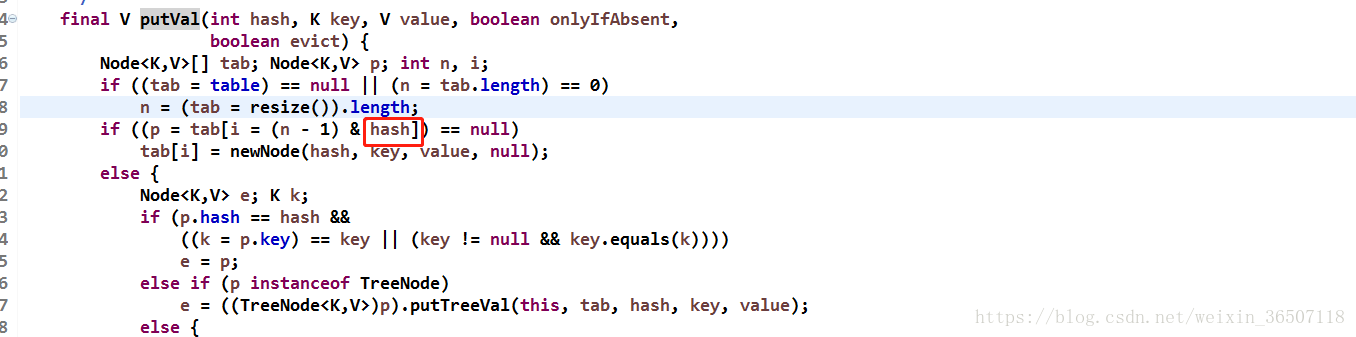
可以看到newCap为1时,ft为0.75,转化为int类型时threshold为0,再看下putVal()这个方法。

因为初始化容量给定为0,所以++size为1大于threshold,所以会重新调用resize()方法 ,这时resize()会做想要处理,

让新的容量左移一位,所以无论你给定容量还是不给定hashMap的容量一定是2的整数次方

其他条件下(初始化)时,新容量等于默认初始化容量,新阈值为12。
最后扩展一点,容量都为2的整数次方的原因是为了使hash更均匀,降低hash碰撞概率,hash的计算主要分为三个阶段:计算hashcode、高位运算与取模运算
· 首先上面的hash是由put方法中的hash(key)产生的,源码为:

这里通过hashCode()计算出key的哈希值,然后将哈希值h右移16位,再与原来的h做异或^运算——这一步是高位运算(异或不清楚的可以看博主后面的一篇文章https://mp.csdn.net/postedit/82986377)。如果不进行高位运算,那么hash值将是一个int型的32位数。而从2的-31次幂到2的31次幂之间,有几十亿的数,HashMap的table内存没那么大。所以这个散列值不能直接用来最终的取模运算,而需要先加入高位运算,将高16位和低16位的信息"融合"到一起,也称为"扰动函数"。这样才能保证hash值所有位的数值特征都保存下来而没有遗漏,从而使映射结果尽可能的松散。最后,根据 n-1 做与操作的取模运算。这里也能看出为什么HashMap要限制table的长度为2的n次幂,因为这样,n-1可以保证二进制展示形式是(以16为例)0000 0000 0000 0000 0000 0000 0000 1111。在做"与"操作时,就等同于截取hash二进制值的后四位数据作为下标。这里也可以看出"扰动函数"的重要性了,如果高位不参与运算,那么高16位的hash特征几乎永远得不到展现,发生hash碰撞的几率就会增大,从而影响性能。
总结来说就是HashMap的table下标计算方法(n-1)&hash,假如没做高低16位异或处理只使用hashCode(),那么hashCode32位将不会全部参与取模运算,因为基本上只有低位参与运算,所以如果不做高低16位异或处理,hash碰撞的几率会大大增加,所以做高低16位异或处理是为了减少hash碰撞的概率。