初始集群状态
| 机器名 |
IP |
作用 |
linux系统 |
| master |
192.168.218.133 |
CentOS-6.9-x86_64-bin-DVD1.iso |
|
| slave1 |
192.168.218.135 |
CentOS-6.9-x86_64-bin-DVD1.iso |
|
| slave2 |
192.168.218.134 |
CentOS-6.9-x86_64-bin-DVD1.iso |
修改所有机器上的zk环境变量
sudo vim ~/.bash_profile
source ~/.bash_profile

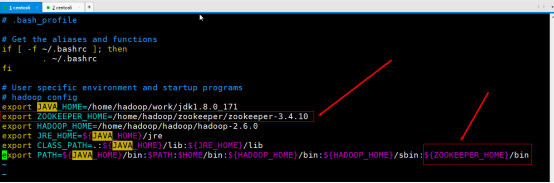
export ZOOKEEPER_HOME=/home/hadoop/zookeeper/zookeeper-3.4.10
:${ZOOKEEPER_HOME}/bin

修改配置文件zoo.cfg
所有zookeeper节点的配置文件zoo.cfg都是一样的,只有myid文件不一样

重命名mv zoo_smaple.cfg zoo.cfg
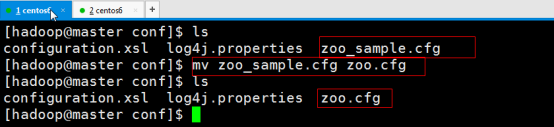
sudo vim zoo.cfg

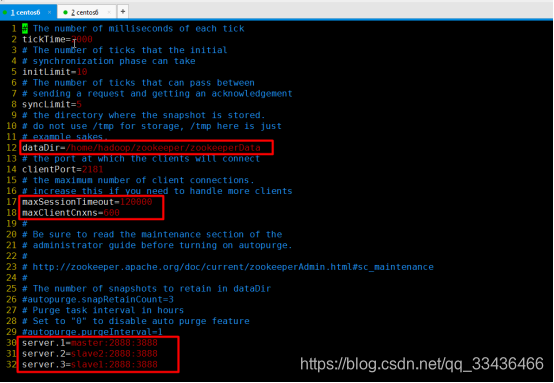
dataDir=/home/hadoop/zookeeper/zookeeperData
maxSessionTimeout=120000
maxClientCnxns=600
server.1=master:2888:3888
server.2=slave2:2888:3888
server.3=slave1:2888:3888
根据zoo.cfg到各个机器上手动创建dataDir目录
mkdir -pv /home/hadoop/zookeeper/zookeeperData

根据zoo.cfg到各个机器上手动创建myid文件
master : echo 1 > myid
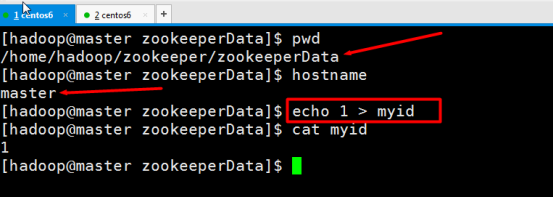
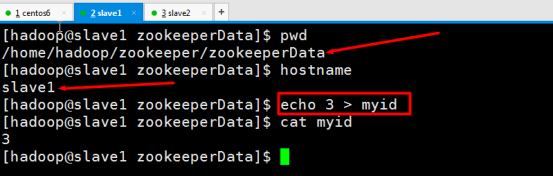
slave1 : echo 3 > myid
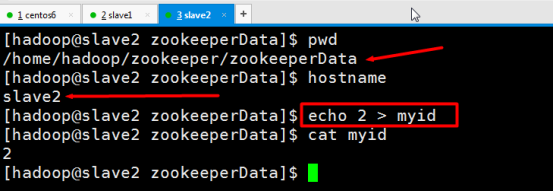
slave2 : echo 2 > myid
每台机器都要启动zk

查看zk的状态
zkServer.sh status



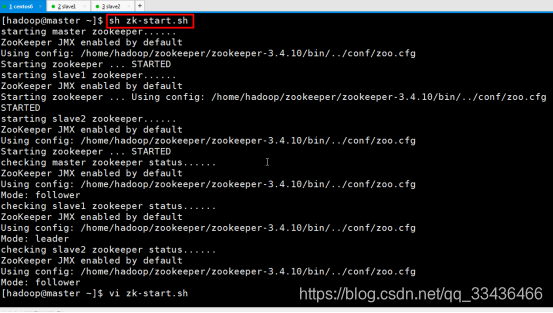
每台服务器都执行zkServer.sh status,其中有一台应该显示:“Mode:follower”,其他显示“Mode:leader”
jps -l

批量启动zk脚本开发
vi zk-start.sh
![]()

#!/bin/bash
#调用zkServer.sh start启动zk服务
for host in master slave1 slave2
do
echo "starting $host zookeeper......"
ssh hadoop@$host "source ~/.bash_profile;/home/hadoop/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start"
done
#调用zkServer.sh status查看zk状态
赋予脚本执行的权限
chmod u+x zk-start.sh
运行脚本
sh zk-start.sh
zk集群结构
zk集群中节点有3中角色
leader 主节点
follower 从节点,会参与集群leader的选举
observer 从节点,不会参与集群leader的选举
leader选举机制:集群启动之时,比如,server1先启动,启动之后,探测集群中是否有leader,如果没有,就开始往集群中广播投票:选自己。接着server2上线了发现集群中没有leader,也投票选举:选自己,接着server1和server2都受到两个投票信息,两个节点都没有成功当选leader,再来一轮投票,server1会投server2(投id更大的),server2投自己(投id更大的),此时两人都得到选举信息:结果是server2得到两个投票得分,server2当选leader,此时集群进入正常工作状态,然后server3上线了探测发现有一个leader了自动进入follower状态。集群运行中,如果leader宕机,剩下的机器会自动进入选状态重新选举,选举的依据是:优先考虑节点所持有的数据的版本号,次之在考虑id。
zk的基本使用
zk的自带命令行客户端使用
zkCli.sh
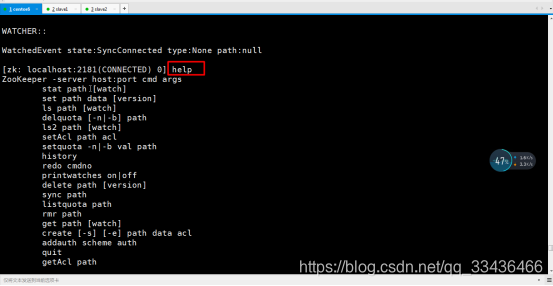
zk中的数据本质上是一些<key,value>
zk中的一个数据叫做一个znode
一个znode中的数据不能太大,通常在10kb以内,官方要求最多不能超过1mb,如果太大则会导集群中各节点的数据无法实时同步保持一致性
znode类型
ephemeral节点:临时几点,临时节点的生命周期跟客户端回话绑定,一旦客户端回话失败,那么这个客户端创建的所有临时节点都会被删除
persistent节点:持久节点,一旦被创建就会一直存在,除非手动删除
sequential节点:带自增序号的节点,在同一个节点下创建sequential节点,zk会给子节点名字自动拼接一个自增的序列号
zk的节点事件监听功能
ls path watch
zk的客户端api基本使用
String connectString = "192.168.218.133:2181,192.168.218.134:2181,192.168.218.135:2181";
int sessionTimeout = 2000;
Watcher watcher = null;
try {
ZooKeeper zk = new ZooKeeper(connectString, sessionTimeout, watcher);
String path = "/aaa/bbb";
boolean watch = false;
Stat stat = new Stat();
byte[] data = zk.getData(path, watch, stat);
System.out.println(new String(data));
zk.close();
} catch (IOException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}