0、引言
这是国外培训ppt课程的节选内容。
以下是我们的Core Elasticsearch:Operations课程中的一些很棒的幻灯片,它们有助于解释分片分配的概念。 我们建议您更全面地了解这一点,但我会在此提供我们培训的概述:
分片分配是将分片分配给节点的过程。 这可能发生在初始恢复,副本分配,重新平衡或添加或删除节点期间。 大多数时候,你不需要考虑它,这项工作是由Elasticsearch在后台完成的。 如果您发现自己对这些细节感到好奇,本文将探讨在几种不同情况下的分片分配。
由于是图解,为方便阅读,我分了4篇文章逐一呈现。
1、认知前提
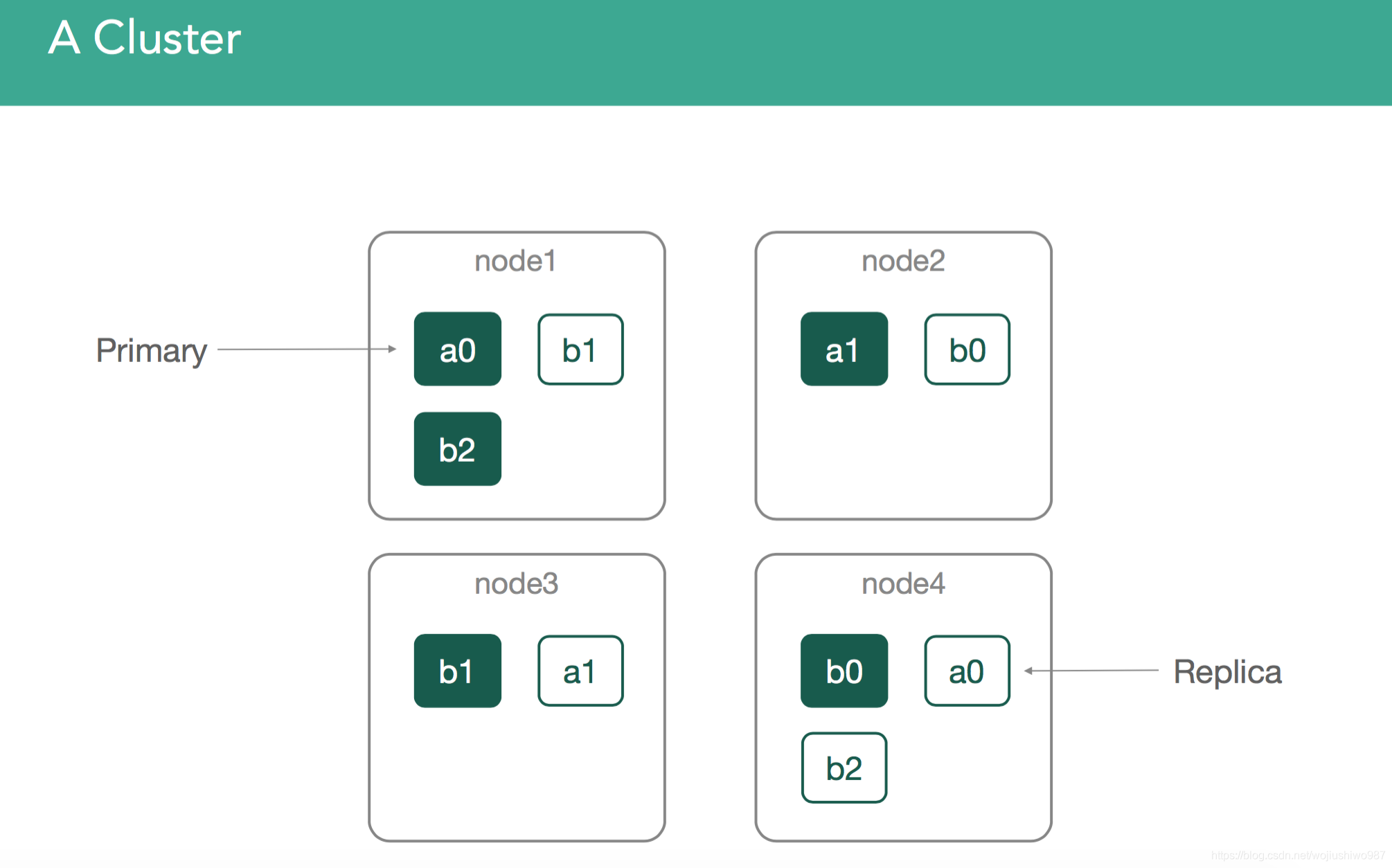
这是我们的4节点集群,我们将在内容中使用这些示例:
2、创建索引
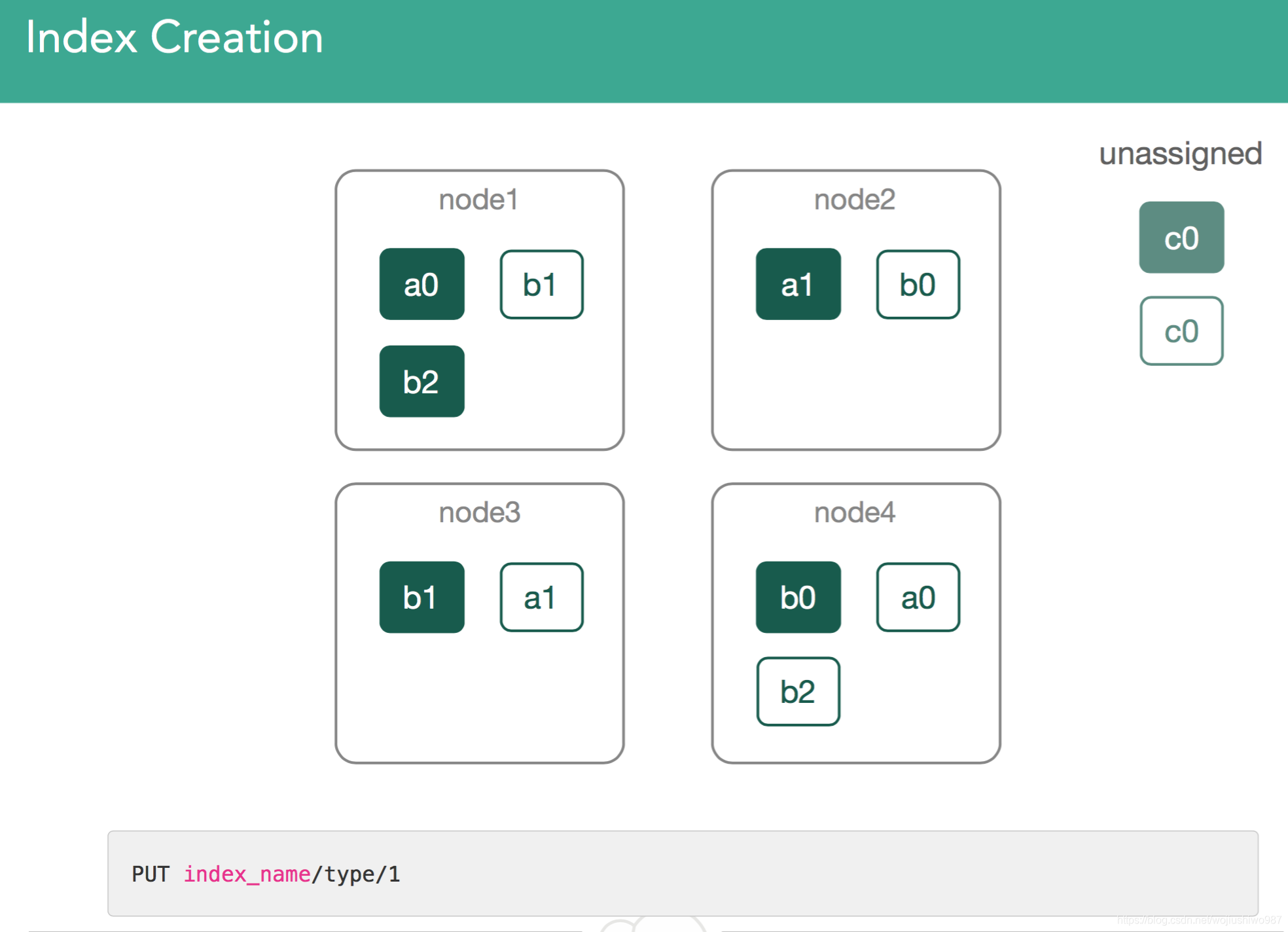
图1:创建索引c
这是最简单的用例。 我们已经创建了一个索引c,为此我们必须分配新的分片。 如上,通过使用Kibana中的Console插件将第一个文档索引到新索引c中,使用灰色框中的命令进行索引相关操作。
对于索引c,我们创建了一个主分片和一个副本分片。 Master主节点需要创建索引c,并分配两个分片c0(主分片和副本分片)。 集群平衡的方式如下:
1、通过查看群集中每个节点包含的平均分片数,然后尝试使该数字尽可能接近相同
2、通过评估集群中的每个索引级别,并尝试在这些索引之间重新平衡分片。
这个过程有一些限制,这些限制是由分配决策者强加的。 主节点评估集群尝试做出的每个决策,并做出是/否决定。
3、分片分配机制
最干净的示例是您不能将主分片和副本分片数据放在同一节点上。
3.1、基于冷热节点类型设置分片
这允许您仅在具有某些属性的节点上放置分片,并接受或拒绝集群做出的决策。
这是控制此配置的用户驱动决策的示例。

知识点:集群的冷热数据分离。
当使用elasticsearch进行更大时间的数据分析用例时,我们建议使用基于时间的索引和分层架构,其中包含3种不同类型的节点(主节点,Hot热节点和Warm暖冷节点),我们将其称为“冷热数据分离 “架构。每个节点都有自己的特征,如下所述。
主节点
我们建议每个群集运行3个专用主节点,以提供最大的弹性性能。使用这些时,您还应将discovery.zen.minimum_master_nodes设置为2,这样可以防止出现“裂脑”情况。
利用专用主节点,仅负责处理集群管理和状态,提高整体稳定性。
因为它们不包含数据也不参与搜索和索引操作,所以它们在繁重索引或长时间的搜索期间可能不会遇到对JVM的相同需求。因此不太可能受到长时间垃圾收集暂停(gc pause)的影响。
因此,可以为它们配置CPU,RAM和磁盘配置,远低于数据节点所需的配置。
热节点
此专用数据节点执行集群中的所有索引操作。他们也拥有最新的、最常被查询的索引数据。
由于索引是CPU和IO密集型操作,因此这些服务器需要功能强大,并且需要连接SSD存储。
我们建议至少运行3个热节点以实现高可用性。
根据您希望收集和查询的最新数据量,您可能需要增加此数字以实现性能目标。
暖冷节点
这种类型的数据节点旨在处理大量不经常查询的只读索引。
由于这些索引是只读的,因此热节点倾向于使用大型连接磁盘(通常是机械磁盘)而不是SSD。
与热节点一样,我们建议至少使用3个热节点以实现高可用性。
和以前一样,需要注意的是,大量数据可能需要额外的节点来满足性能要求。
另请注意,CPU和内存配置通常需要接近热节点的配置。这只能通过测试类似于您在生产环境中遇到的查询来确定。
相关冷热节点设置和操作参考:
https://www.elastic.co/blog/hot-warm-architecture-in-elasticsearch-5-x
3.2、基于磁盘使用率分片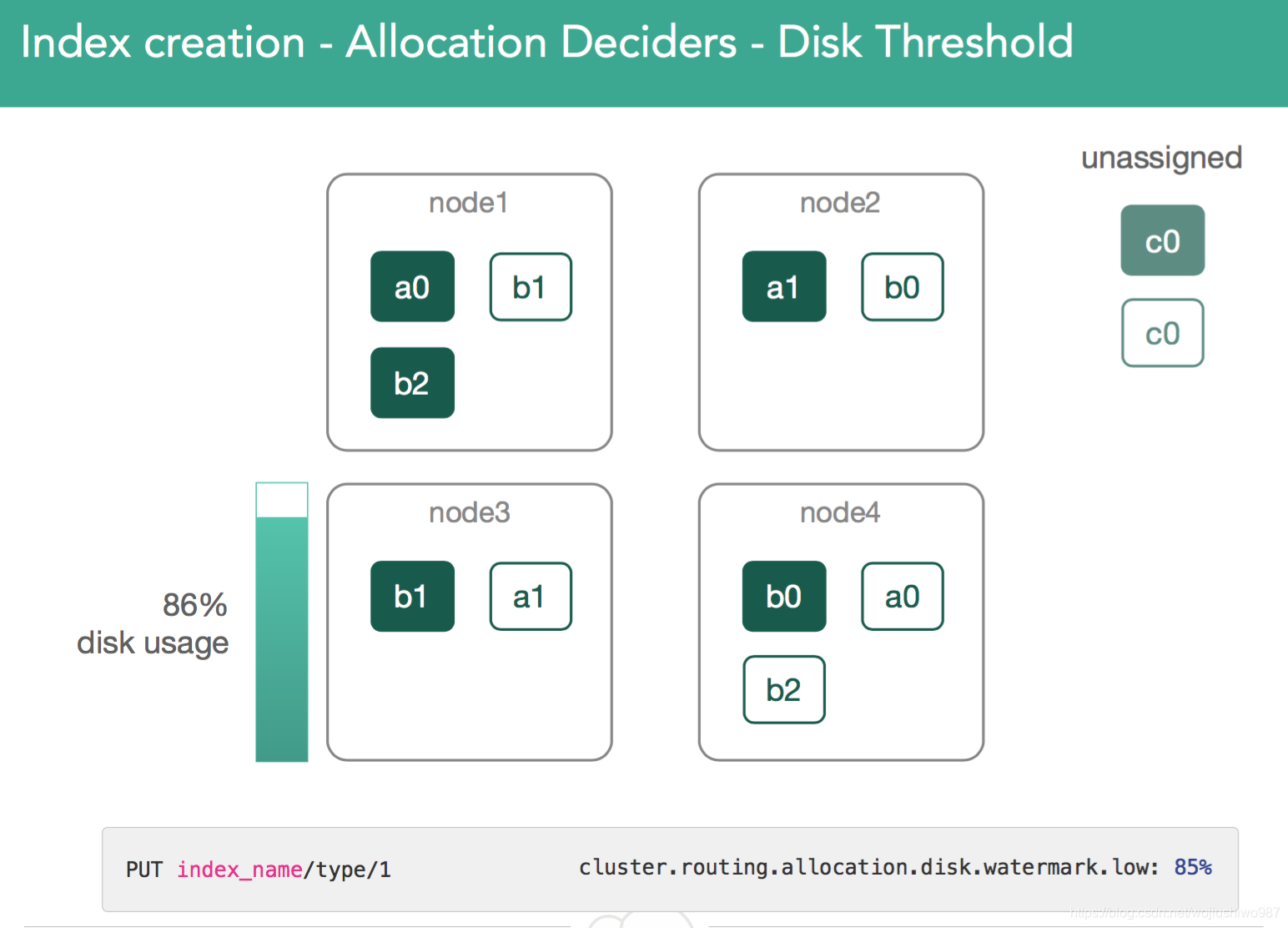
Master主节点监视群集上的磁盘使用情况并查看高/低警戒水位线。
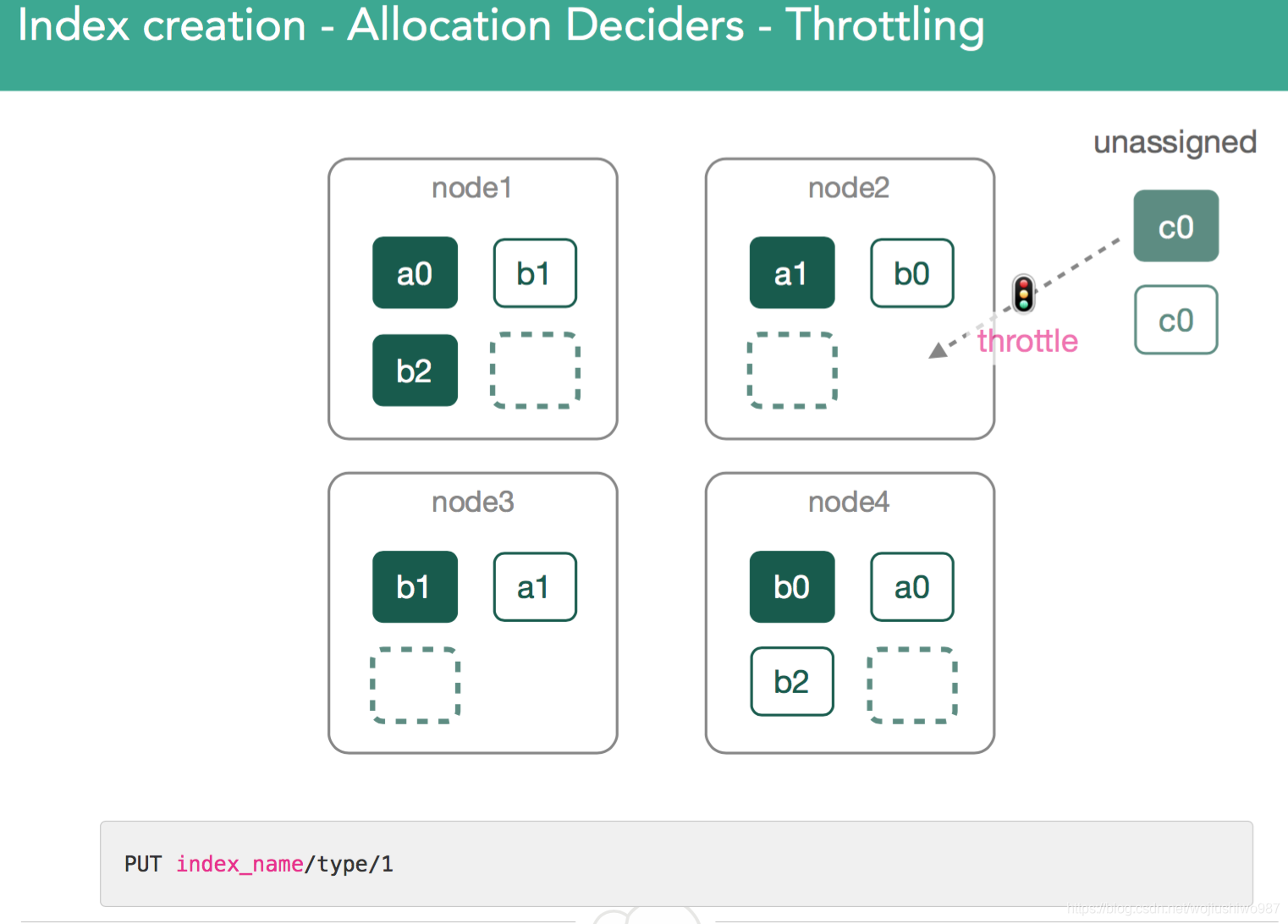
3.3、分配分片的节流机制
节流——意味着原则上我们可以为节点分配一个分片,但是有太多的分片在后台需要持续恢复。
为了保护节点并允许恢复,分配决策器可以告诉集群等待并重试在下一次迭代中将分片分配给同一节点。
4、分片的初始化过程
一旦我们确定了主分片所属的位置,它就会被标记为“初始化”,并且决策将通过修改后的集群状态广播到集群,集群状态可供集群中的所有节点使用。
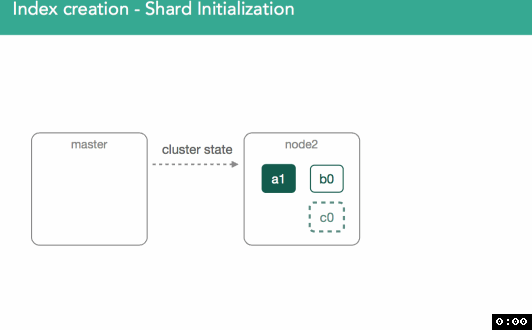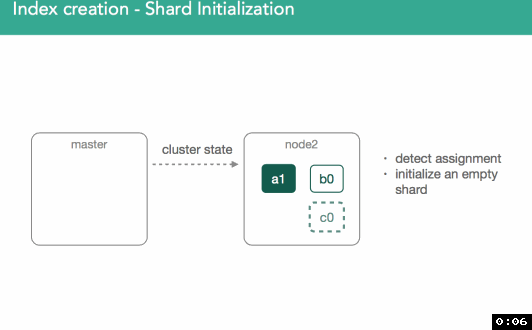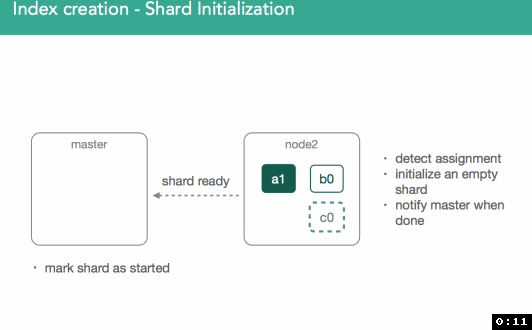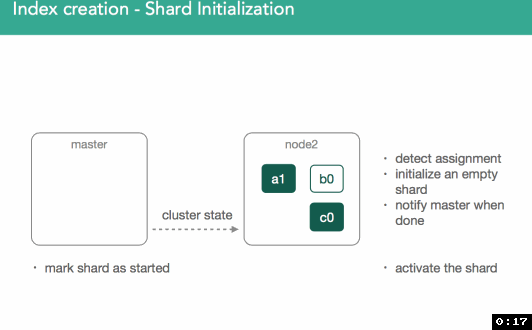
标记初始化后,节点将检测到它已分配新的分片, 将创建一个空的lucene索引,一旦完成,将通知主节点已准备好分片,主节点将分片标记为已启动,并发送另一个已修改的集群状态。
一旦分配了主分片的节点获得更新的集群状态,它就会将该分片标记为已启动。 因为它是主分片,现在可以索引它。
正如您所见,所有这些通信都是通过修改的集群状态完成的。 完成此循环后,主节点将执行重新路由并重新评估分片分配,从而可能决定上一次迭代中的节流限制的分片重新分配。
4.1 分配主分片
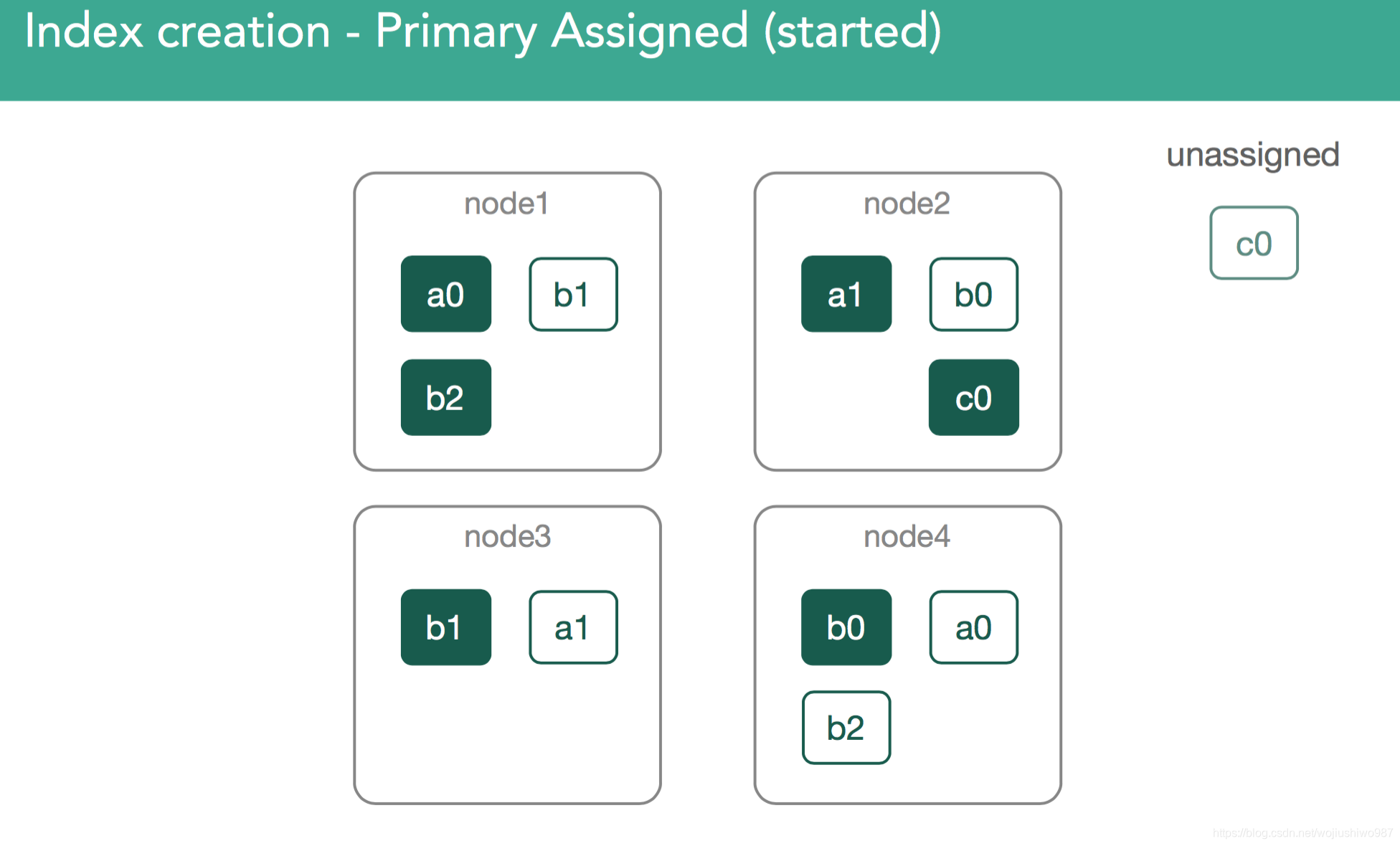
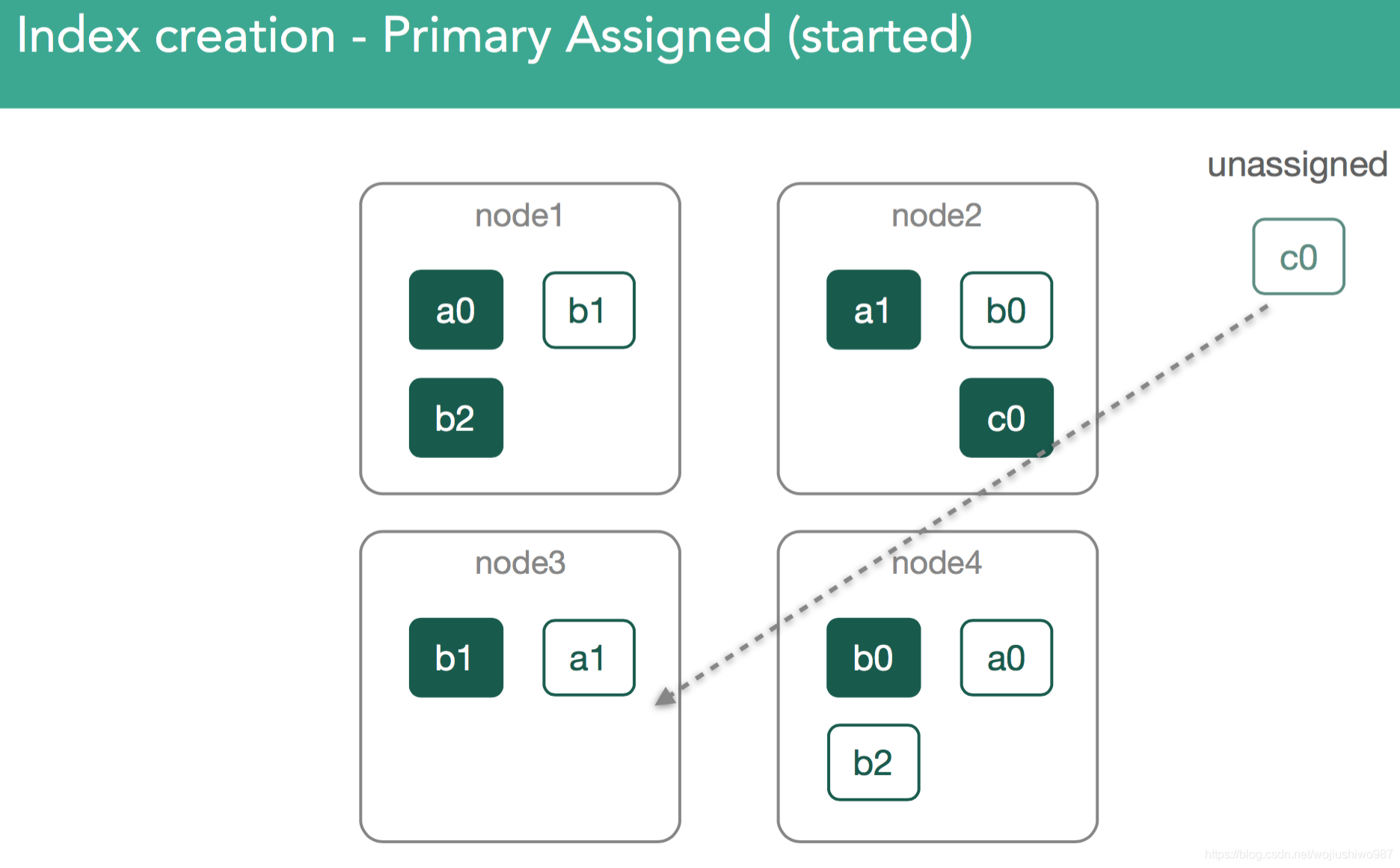
在我们的例子中,master现在必须尝试分配剩余的副本c0。 这也是分配决策者的决定,它阻止分配副本,直到主节点在包含它的节点上标记为已启动。
4.2 分配副本分片
此时,使用与上述相同的过程进行重新平衡,目标是确保整个群集中的数据平衡,并且在此示例的情况下,我们将按顺序将c0副本分片分配给群集中的node3 保持平衡。 这应该在群集中的每个节点上留下3个分片。
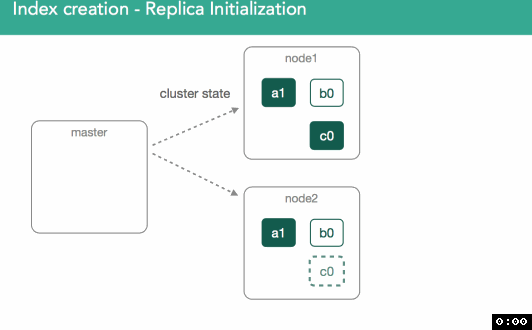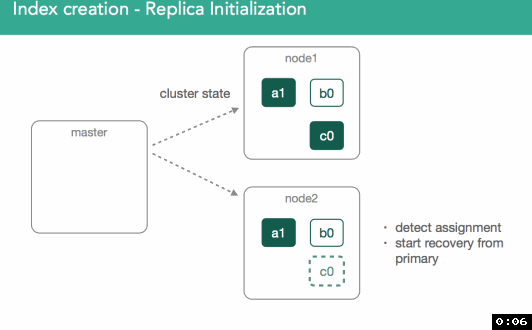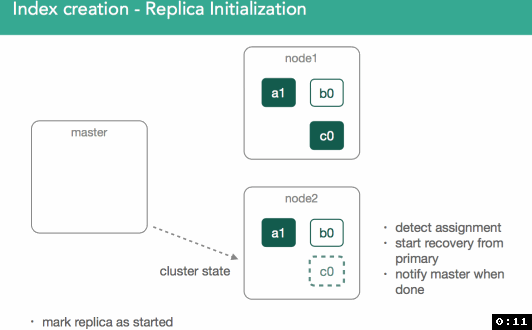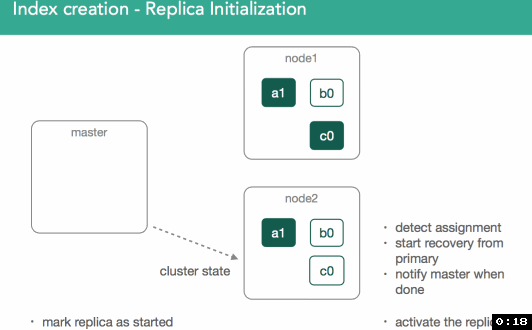
我们需要确保副本分片数据和主分片数据一致。
分配副本时,重要的是要了解我们要将任何丢失的数据从主分片复制到副本。
在此之后,主服务器将再次将副本标记为已启动并广播新的集群状态。
篇幅原因,后续的几个小章节:
集群重启、集群删除节点、移动分片引起的分片底层操作将后续跟进。
5、 小结
文章原标题"every-shard-deserves-a-home“ 直译为每个分片都值得拥有一个家。
实际的含义想通过图解的方式将不同场景下主分片、副本分片的来龙去脉讲明白。
本来准备写一篇segment底层的文章,但看到了这一片忍不住要翻译一下,
水平有限,欢迎拍砖。
参考:https://www.elastic.co/blog/every-shard-deserves-a-home

Elasticsearch基础、进阶、实战第一公众号