什么是集合
集合是JAVA存放数据容器,集合类存放于java.util包中。
集合类存放的都是对象的引用,而非对象本身,出于表达上的便利,我们称集合中的对象就是指集合中对象的引用(reference)
集合有哪些
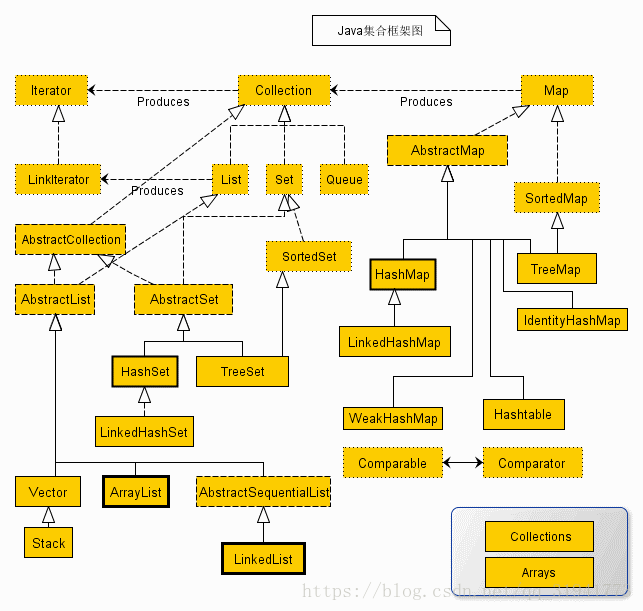
按照存储的方式主要分为两大类Map(存键值对),collection(存单个元素)。
collection:有三个接口list、set、queue
Iterable
集合的根接口(map除外)
public interface Iterable<T> {
Iterator<T> iterator();
}
iterator是集合的迭代器,用于遍历集合的元素。
主要hashNext(),next(),remove()三种方法,ListIterator继承于Iterable新增了add(),previous(),hasPrevious()方法。
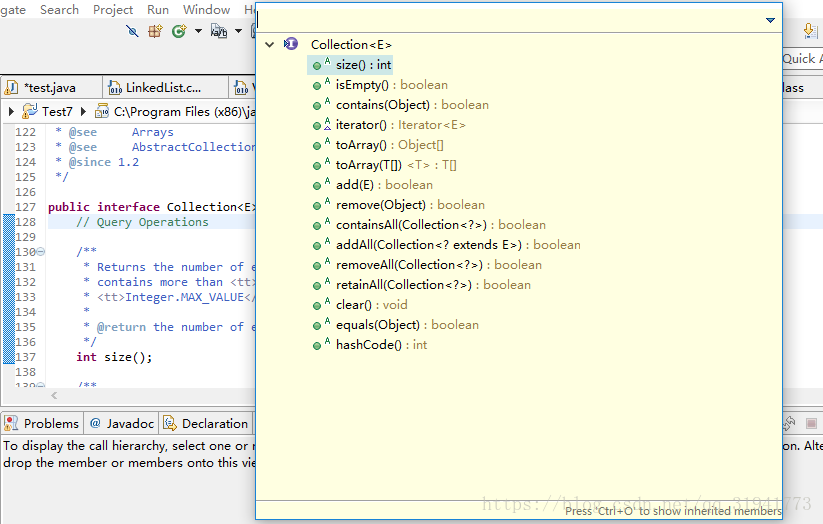
Collection
List 接口和 Set 接口的父接口
public interface Collection<E> extends Iterable<E> {
}
List
有序,可以重复的集合。 继承collection所以他有collection中的方法
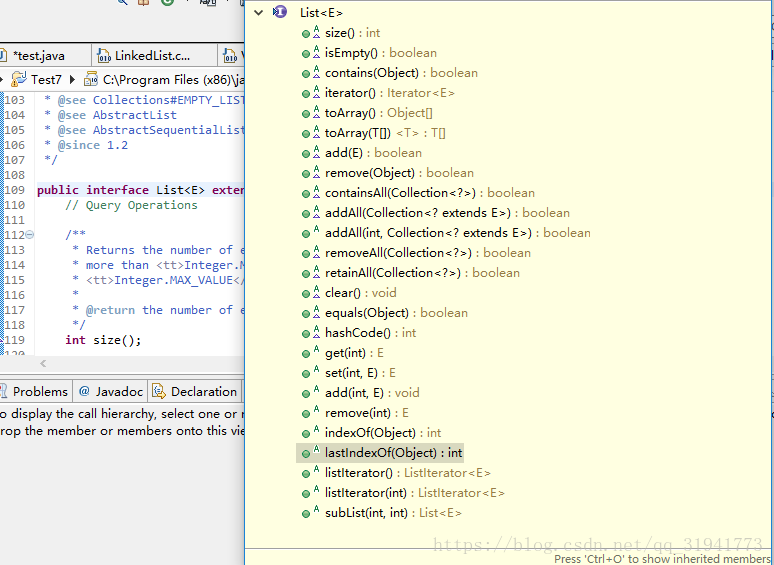
list 的实现类有 ArrayList、LinkedList、Vetor
①、List list1 = new ArrayList();
底层数据结构是数组,查询快,增删慢;线程不安全,效率高
②、List list2 = new Vector();
底层数据结构是数组,查询快,增删慢;线程安全(synchronized),效率低,几乎已经淘汰了这个集合,子类stack
③、List list3 = new LinkedList();
底层数据结构是链表,查询慢,增删快;线程不安全,效率高
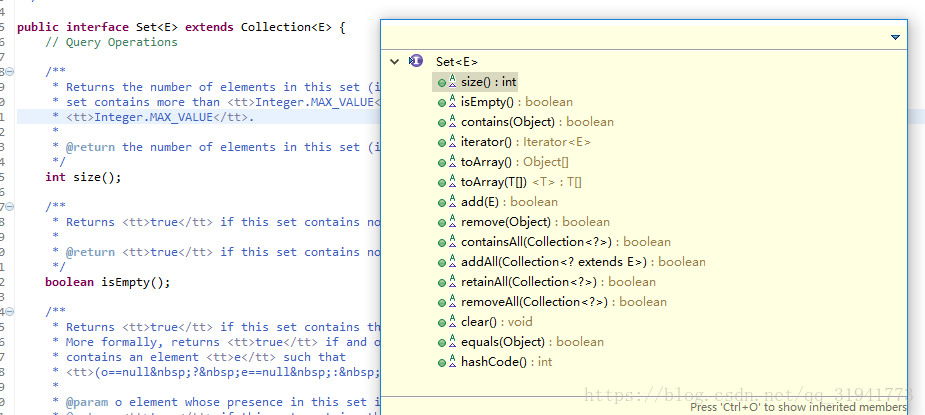
Set
无序、不可重复的集合,具体实现类hashSet(LinkedHashSet)、SortedSet(TreeSet)
①、Set hashSet = new HashSet();
HashSet:不能保证元素的顺序;不可重复;不是线程安全的;集合元素可以为 NULL,底层采用hash表的算法;
②、Set linkedHashSet = new LinkedHashSet();
因为底层采用 链表 和 哈希表的算法。链表保证元素的添加顺序,哈希表保证元素的唯一性
③、Set treeSet = new TreeSet();
TreeSet:有序;不可重复,底层使用 红黑树算法,擅长于范围查询。
Map
key-value 的键值对,key 不允许重复,value 可以重复
因为 Map 集合即没有实现于 Collection 接口,也没有实现 Iterable 接口,所以不能对 Map 集合进行 for-each 遍历。
遍历map
map中 interface Entry<K,V> 属性。
HashMap< String, String> map = new HashMap<String, String>();
//先获取key的Set,再通过key获取value
for (String key : map.keySet()) {
map.get(key);
}
// 将map的entry作为值放入set中,遍历entry
for (Map.Entry<String, String> entry : map.entrySet()) {
entry.getKey();
entry.getValue();
}
}
MAP的子类
HashMap,HashTable,LinkedHashMap,TreeMap
集合的面试问题
-
1 泛型的作用
Java1.5引入了泛型,所有的集合接口和实现都大量地使用它。泛型允许我们为集合提供一个可以容纳的对象类型,因此,如果你添加其它类型的任何元素,它会在编译时报错。这避免了在运行时出现ClassCastException,因为你将会在编译时得到报错信息。泛型也使得代码整洁,我们不需要使用显式转换和instanceOf操作符。它也给运行时带来好处,因为不会产生类型检查的字节码指令。 -
2 集合中那些实现类是线程安全的
Vector 使用synchronized
Stack 继承Vector 所以也是线程安全的
Hashtable
ConcurrentHashMap
Enumeration -
Arraylist 与 LinkedList 、Vector区别
讲清楚arraylist和linkedlist的区别,得先从数组与链表讲起
数组是将元素在内存中连续存放,由于每个元素占用内存相同,所以你可以通过下标迅速访问数组中任何元素。但是如果你要在数组中增加一个元素,你需要移动大量元素,在内存中空出一个元素的空间,然后将要增加的元素放在其中。同样的道理,如果你想删除一个元素,你同样需要移动大量元素去填掉被移动的元素。
链表中的元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起。比如:上一个元素有个指针指到下一个元素,以此类推,直到最后一个元素。如果你要访问链表中一个元素,你需要从第一个元素开始,一直找到你需要的元素位置。但是增加和删除一个元素对于链表数据结构就非常简单了, 只要修改元素中的指针就可以了。
综上可以得出,基于数组实现的arraylist在查询上比较方便,而增删上比较慢。而基于链表实现的linkedlist在查询上比较慢需要从头开始搜索,而在元素增删的操作上比较快。
Vector底层与arraylist相似,但是其方法上有synchronized 以实现线程同步,所以在效率上比arraylist要低,但是线程安全。
- HashMap 和 Hashtable 的区别
点这里
在使用HashMap和Hashtable时要先了解其实现原理,下面会介绍,这里只讲区别
1、 Hashtable在其方法上加上了synchronized 使得其在多线程中是安全的,而HashMap是非synchronized的。
我们能否让HashMap同步?
Map m = Collections.synchronizeMap(hashMap);
2 、 HashMap可以有空键值对,但是Hashtable不可以有空键值对
HashMap< String, String> map = new HashMap<String, String>();
map.put(null, null);
Hashtable<String, String> tHashtable = new Hashtable<String, String>();
try {
tHashtable.put(null, "");
} catch (NullPointerException e) {
System.err.println( "Hashtable 不允许空键值对");
}
结果:

- comparable 和 comparator的区别?
HashMap 的工作原理及代码实现
我们都知道map里元素是以键值对Entry<key,value>存储的,那我们具体怎么将Entry放入到bucket中呢
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
我们先通过key计算出hash值 int hash = hash(key);,然后通过hash和length获取bucket的索引值
Entry<K,V> e = table[i]; e != null; e = e.next,获取索引i的元素entry,如果entry有值就next,直到key与e.key相等位置。然后把value值替换。
我们再来看get方法
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
如果key为null则返回null,
getEntry(key) 如果indexFor(hash, table.length)索引没有找到,则返回null,如果有值则把key相等的value返回。
ConcurrentHashMap 的工作原理及代码实现
我们都知道hashmap是不安全的,而hashtable效率低
concurrenthashmap是线程安全又效率较高的一种选择。
ConcurrentHashMap所使用的是锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。