分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
汉字的编码是很多初学者不容易搞不明白的事情。最早的汉字字符集是GB2312-80,收入汉字6763个,符号715个,总计7478个字符,大陆普遍使用的简体字字符集。本文借助于一个能输出这些字符的简单的C++程序,体验汉字字符的编码。
先简介一下GB2312-80的概况。
1、区位码
每个汉字及符号都有一个区位码,即每个汉字有一个区号(两位十进制)和一个位号(两位十进制)。一共分了94个区,每个区中有94个汉字。
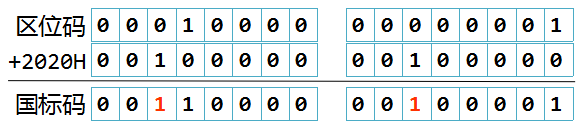
如下图了其中第1区和17区中的汉字:
2、国标码
汉字的国标码可以在区位码基础上换算得到:国标码=(区位码的十六进制表示)+2020H,国标码的取值范围:2121H~7E7EH。
例如:“啊”的区码是16,位码为01,其区位码的十六进制表示为1001H,得到“啊”的国标码为:3021H。如下图:
3、机内码
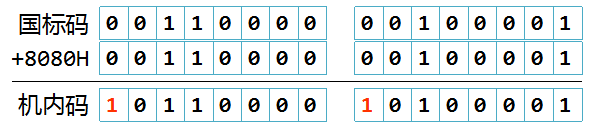
中文或西文信息在计算机系统中的代码表示称为机内码。ASCII码是一种西文机内码,用一个字节表示,其最高位均为0。汉字机内码用连续两个字节表示,为能和ACSII符号区分,每个字节的最高位是1。机内码和国标码的转换规则是:机内码 = 国标码+8080H =(区位码的十六进制表示)+A0A0H。显然,就是将国标码的两个字节的最高位均置为1即可。
例如,“啊”的国标码为:3021H,加上8080H后,其机内码为B0A1H,如下图所示:
下面的程序,将GB2312-80中所有的汉字输出到一个文件中,对照上面的原理,读程序并运行,你将理解汉字在机器内部的表示。

(1)C++程序
#include <iostream>#include <cstdio>using namespace std; int main(){ int i,j; char a[3]; //用两字节表示一个汉字,a[0]为第1个字节,a[1]为第2个字节 a[2]='\0'; //a[2]固定为'\0',作为保存一个汉字的字符串的结束 freopen("chineseChar.txt","w",stdout); //将输出重定向到文件,便于查看结果 for(i=1;i<=94;i++) //区号从1到94 { cout<<"=====第 "<<i<<" 区======"<<endl; a[0] = i + 0xA0; //将第1个字节变为机内码 for(j=1;j<=94;j++) //位号从1到94 { a[1] = j + 0xA0; //将第2个字节变为机内码 cout<<a<<'\t'; //输出a,里面有两字节,是i区j位汉字的机内码 if(j%10==0) cout<<endl; //每10个换一行 } cout<<endl; } return 0;}(2)C程序
#include<stdio.h>int main(){ int i,j; char a[3]; //用两字节表示一个汉字,a[0]为第1个字节,a[1]为第2个字节 a[2]='\0'; //a[2]固定为'\0',作为保存一个汉字的字符串的结束 freopen("chineseChar.txt","w",stdout); //将输出重定向到文件,便于查看结果 for(i=1;i<=94;i++) //区号从1到94 { printf("=====第 %d 区======\n",i); a[0] = i + 0xA0; //将第1个字节变为机内码 for(j=1;j<=94;j++) //位号从1到94 { a[1] = j + 0xA0; //将第2个字节变为机内码 printf("%s\r",a); //输出a,里面有两字节,是i区j位汉字的机内码 if(j%10==0) printf("\n"); //每10个换一行 } printf("\n"); } return 0;}程序输出的所有汉字,见本文后附件。
#include <iostream>using namespace std;int main(){ char a[]="汉字处理挺好玩"; cout<<a<<endl; a[1]='a'; cout<<a<<endl; a[2]='b'; cout<<a<<endl; char b[10]; b[8]='\0'; cout<<b<<endl; return 0;}==================== 迂者 贺利坚 CSDN博客专栏=================|== IT学子成长指导专栏 专栏文章的分类目录(不定期更新) ==||== C++ 课堂在线专栏 贺利坚课程教学链接(分课程年级) ==||== 我写的书——《逆袭大学——传给IT学子的正能量》 ==|===== 为IT菜鸟起飞铺跑道,和学生一起享受快乐和激情的大学 ===== |
、 。 · ˉ ˇ ¨ 〃 々 —
~ ‖ … ‘ ’ “ ” 〔 〕 〈
〉 《 》 「 」 『 』 〖 〗 【
】 ± × ÷ ∶ ∧ ∨ ∑ ∏ ∪
∩ ∈ ∷ √ ⊥ ∥ ∠ ⌒ ⊙ ∫
∮ ≡ ≌ ≈ ∽ ∝ ≠ ≮ ≯ ≤
≥ ∞ ∵ ∴ ♂ ♀ ° ′ ″ ℃
$ ¤ ¢ £ ‰ § № ☆ ★ ○
● ◎ ◇ ◆ □ ■ △ ▲ ※ →
← ↑ ↓ 〓
=====第 2 区======
ⅰ ⅱ ⅲ ⅳ ⅴ ⅵ ⅶ ⅷ ⅸ ⅹ
⒈ ⒉ ⒊ ⒋
⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕
⒖ ⒗ ⒘ ⒙ ⒚ ⒛ ⑴ ⑵ ⑶ ⑷
⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ ⑿ ⒀ ⒁
⒂ ⒃ ⒄ ⒅ ⒆ ⒇ ① ② ③ ④
⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ㈠ ㈡
㈢ ㈣ ㈤ ㈥ ㈦ ㈧ ㈨ ㈩
Ⅰ Ⅱ Ⅲ Ⅳ Ⅴ Ⅵ Ⅶ Ⅷ Ⅸ Ⅹ
Ⅺ Ⅻ
=====第 3 区======
! " # ¥ % & ' ( ) *
+ , - . / 0 1 2 3 4
5 6 7 8 9 : ; < = >
? @ A B C D E F G H
I J K L M N O P Q R
S T U V W X Y Z [ \
] ^ _ ` a b c d e f
g h i j k l m n o p
q r s t u v w x y z
{ | }  ̄
=====第 4 区======
ぁ あ ぃ い ぅ う ぇ え ぉ お
か が き ぎ く ぐ け げ こ ご
さ ざ し じ す ず せ ぜ そ ぞ
た だ ち ぢ っ つ づ て で と
ど な に ぬ ね の は ば ぱ ひ
び ぴ ふ ぶ ぷ へ べ ぺ ほ ぼ
ぽ ま み む め も ゃ や ゅ ゆ
ょ よ ら り る れ ろ ゎ わ ゐ
ゑ を ん
=====第 5 区======
ァ ア ィ イ ゥ ウ ェ エ ォ オ
カ ガ キ ギ ク グ ケ ゲ コ ゴ
サ ザ シ ジ ス ズ セ ゼ ソ ゾ
タ ダ チ ヂ ッ ツ ヅ テ デ ト
ド ナ ニ ヌ ネ ノ ハ バ パ ヒ
ビ ピ フ ブ プ ヘ ベ ペ ホ ボ
ポ マ ミ ム メ モ ャ ヤ ュ ユ
ョ ヨ ラ リ ル レ ロ ヮ ワ ヰ
ヱ ヲ ン ヴ ヵ ヶ
=====第 6 区======
Α Β Γ Δ Ε Ζ Η Θ Ι Κ
Λ Μ Ν Ξ Ο Π Ρ Σ Τ Υ
Φ Χ Ψ Ω
α β γ δ ε ζ η θ
ι κ λ μ ν ξ ο π ρ σ
τ υ φ χ ψ ω
︵ ︶ ︹ ︺ ︿ ﹀ ︽
︾ ﹁ ﹂ ﹃ ﹄ ︻ ︼ ︷
︸ ︱ ︳ ︴
=====第 7 区======
А Б В Г Д Е Ё Ж З И
Й К Л М Н О П Р С Т
У Ф Х Ц Ч Ш Щ Ъ Ы Ь
Э Ю Я
а б
в г д е ё ж з и й к
л м н о п р с т у ф
х ц ч ш щ ъ ы ь э ю
я
=====第 8 区======
ā á ǎ à ē é ě è ī í
ǐ ì ō ó ǒ ò ū ú ǔ ù
ǖ ǘ ǚ ǜ ü ê ɑ ń ň
ɡ ㄅ ㄆ ㄇ ㄈ
ㄉ ㄊ ㄋ ㄌ ㄍ ㄎ ㄏ ㄐ ㄑ ㄒ
ㄓ ㄔ ㄕ ㄖ ㄗ ㄘ ㄙ ㄚ ㄛ ㄜ
ㄝ ㄞ ㄟ ㄠ ㄡ ㄢ ㄣ ㄤ ㄥ ㄦ
ㄧ ㄨ ㄩ
=====第 9 区======
─ ━ │ ┃ ┄ ┅ ┆
┇ ┈ ┉ ┊ ┋ ┌ ┍ ┎ ┏ ┐
┑ ┒ ┓ └ ┕ ┖ ┗ ┘ ┙ ┚
┛ ├ ┝ ┞ ┟ ┠ ┡ ┢ ┣ ┤
┥ ┦ ┧ ┨ ┩ ┪ ┫ ┬ ┭ ┮
┯ ┰ ┱ ┲ ┳ ┴ ┵ ┶ ┷ ┸
┹ ┺ ┻ ┼ ┽ ┾ ┿ ╀ ╁ ╂
╃ ╄ ╅ ╆ ╇ ╈ ╉ ╊ ╋
=====第 10 区======
=====第 11 区======
=====第 12 区======
=====第 13 区======
=====第 14 区======
=====第 15 区======
=====第 16 区======
啊 阿 埃 挨 哎 唉 哀 皑 癌 蔼
矮 艾 碍 爱 隘 鞍 氨 安 俺 按
暗 岸 胺 案 肮 昂 盎 凹 敖 熬
翱 袄 傲 奥 懊 澳 芭 捌 扒 叭
吧 笆 八 疤 巴 拔 跋 靶 把 耙
坝 霸 罢 爸 白 柏 百 摆 佰 败
拜 稗 斑 班 搬 扳 般 颁 板 版
扮 拌 伴 瓣 半 办 绊 邦 帮 梆
榜 膀 绑 棒 磅 蚌 镑 傍 谤 苞
胞 包 褒 剥
=====第 17 区======
薄 雹 保 堡 饱 宝 抱 报 暴 豹
鲍 爆 杯 碑 悲 卑 北 辈 背 贝
钡 倍 狈 备 惫 焙 被 奔 苯 本
笨 崩 绷 甭 泵 蹦 迸 逼 鼻 比
鄙 笔 彼 碧 蓖 蔽 毕 毙 毖 币
庇 痹 闭 敝 弊 必 辟 壁 臂 避
陛 鞭 边 编 贬 扁 便 变 卞 辨
辩 辫 遍 标 彪 膘 表 鳖 憋 别
瘪 彬 斌 濒 滨 宾 摈 兵 冰 柄
丙 秉 饼 炳
=====第 18 区======
病 并 玻 菠 播 拨 钵 波 博 勃
搏 铂 箔 伯 帛 舶 脖 膊 渤 泊
驳 捕 卜 哺 补 埠 不 布 步 簿
部 怖 擦 猜 裁 材 才 财 睬 踩
采 彩 菜 蔡 餐 参 蚕 残 惭 惨
灿 苍 舱 仓 沧 藏 操 糙 槽 曹
草 厕 策 侧 册 测 层 蹭 插 叉
茬 茶 查 碴 搽 察 岔 差 诧 拆
柴 豺 搀 掺 蝉 馋 谗 缠 铲 产
阐 颤 昌 猖
=====第 19 区======
场 尝 常 长 偿 肠 厂 敞 畅 唱
倡 超 抄 钞 朝 嘲 潮 巢 吵 炒
车 扯 撤 掣 彻 澈 郴 臣 辰 尘
晨 忱 沉 陈 趁 衬 撑 称 城 橙
成 呈 乘 程 惩 澄 诚 承 逞 骋
秤 吃 痴 持 匙 池 迟 弛 驰 耻
齿 侈 尺 赤 翅 斥 炽 充 冲 虫
崇 宠 抽 酬 畴 踌 稠 愁 筹 仇
绸 瞅 丑 臭 初 出 橱 厨 躇 锄
雏 滁 除 楚
=====第 20 区======
础 储 矗 搐 触 处 揣 川 穿 椽
传 船 喘 串 疮 窗 幢 床 闯 创
吹 炊 捶 锤 垂 春 椿 醇 唇 淳
纯 蠢 戳 绰 疵 茨 磁 雌 辞 慈
瓷 词 此 刺 赐 次 聪 葱 囱 匆
从 丛 凑 粗 醋 簇 促 蹿 篡 窜
摧 崔 催 脆 瘁 粹 淬 翠 村 存
寸 磋 撮 搓 措 挫 错 搭 达 答
瘩 打 大 呆 歹 傣 戴 带 殆 代
贷 袋 待 逮
=====第 21 区======
怠 耽 担 丹 单 郸 掸 胆 旦 氮
但 惮 淡 诞 弹 蛋 当 挡 党 荡
档 刀 捣 蹈 倒 岛 祷 导 到 稻
悼 道 盗 德 得 的 蹬 灯 登 等
瞪 凳 邓 堤 低 滴 迪 敌 笛 狄
涤 翟 嫡 抵 底 地 蒂 第 帝 弟
递 缔 颠 掂 滇 碘 点 典 靛 垫
电 佃 甸 店 惦 奠 淀 殿 碉 叼
雕 凋 刁 掉 吊 钓 调 跌 爹 碟
蝶 迭 谍 叠
=====第 22 区======
丁 盯 叮 钉 顶 鼎 锭 定 订 丢
东 冬 董 懂 动 栋 侗 恫 冻 洞
兜 抖 斗 陡 豆 逗 痘 都 督 毒
犊 独 读 堵 睹 赌 杜 镀 肚 度
渡 妒 端 短 锻 段 断 缎 堆 兑
队 对 墩 吨 蹲 敦 顿 囤 钝 盾
遁 掇 哆 多 夺 垛 躲 朵 跺 舵
剁 惰 堕 蛾 峨 鹅 俄 额 讹 娥
恶 厄 扼 遏 鄂 饿 恩 而 儿 耳
尔 饵 洱 二
=====第 23 区======
贰 发 罚 筏 伐 乏 阀 法 珐 藩
帆 番 翻 樊 矾 钒 繁 凡 烦 反
返 范 贩 犯 饭 泛 坊 芳 方 肪
房 防 妨 仿 访 纺 放 菲 非 啡
飞 肥 匪 诽 吠 肺 废 沸 费 芬
酚 吩 氛 分 纷 坟 焚 汾 粉 奋
份 忿 愤 粪 丰 封 枫 蜂 峰 锋
风 疯 烽 逢 冯 缝 讽 奉 凤 佛
否 夫 敷 肤 孵 扶 拂 辐 幅 氟
符 伏 俘 服
=====第 24 区======
浮 涪 福 袱 弗 甫 抚 辅 俯 釜
斧 脯 腑 府 腐 赴 副 覆 赋 复