经过两天的吐血折腾终于在hadoop的界面上看见我同步的日志文件了,记录一下。先来张定妆照:
dashboard里查看:
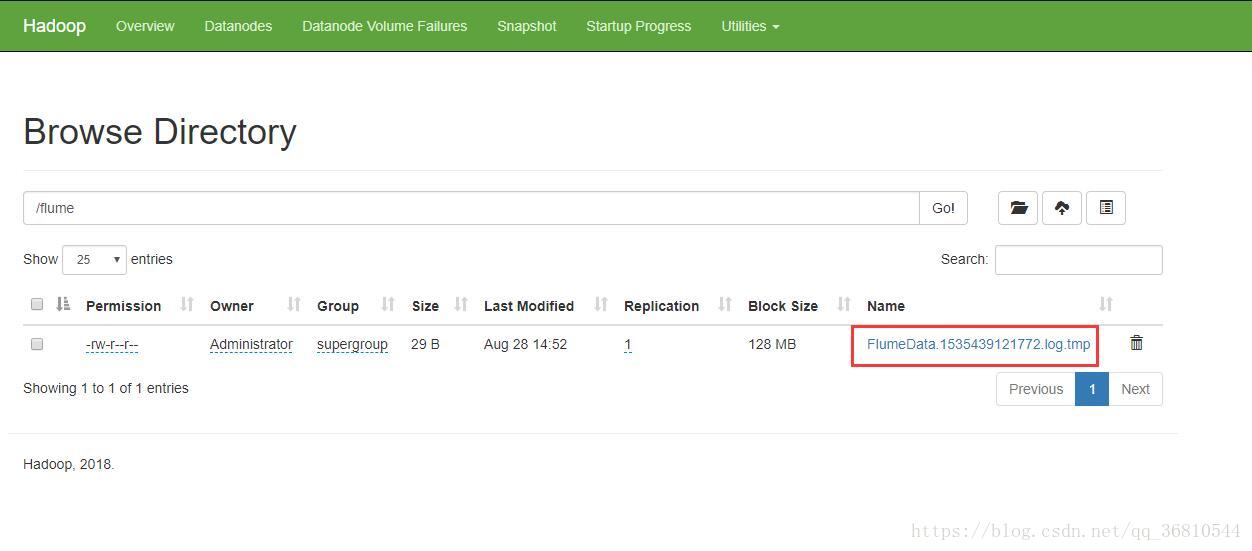
ubuntu下查看:
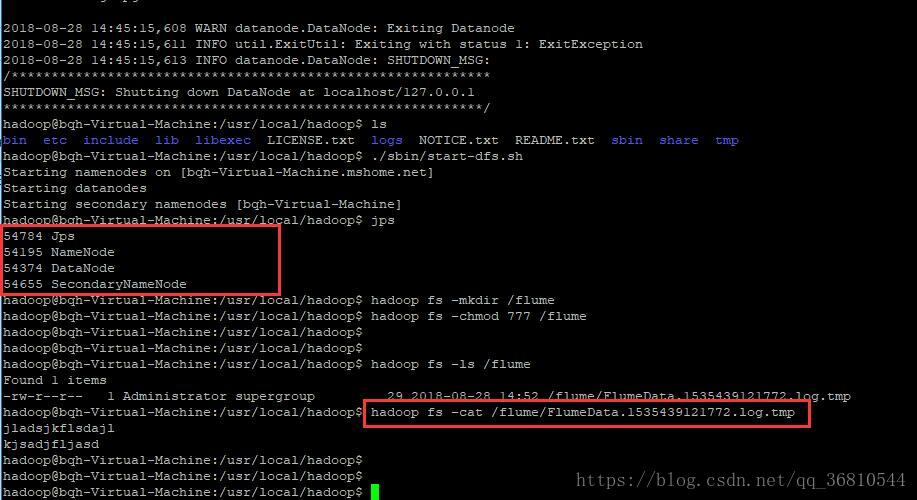
从Windows里上传的日志文件:
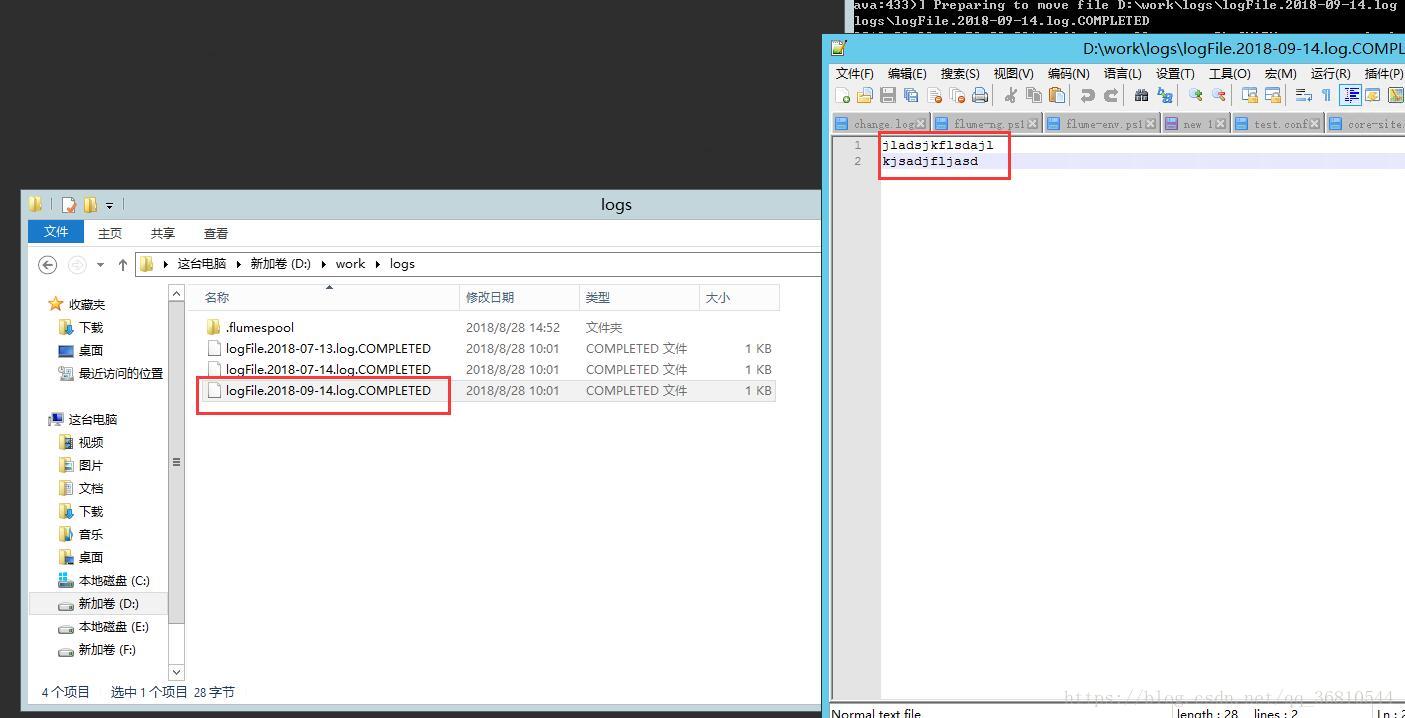
==================================从0开始折腾===================================
环境:windows server 2012 IP:172.17.154.228 产生日志通过flume同步到hadoop服务器上
Ubuntu 18.04 IP:172.17.154.226 部署Hadoop,做日志服务器
安装java环境,这个就不写了,配置好Java home
1. 首先在windows下安装Flume,下载apache-flume-1.7.0-bin,解压到本地目录例如:F:\Software\apache-flume-1.7.0-bin,进入/conf文件夹,创建一个test.conf文件,内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = D:/work/logs #监听的本地目录
a1.sources.r1.deserializer = org.apache.flume.sink.solr.morphline.BlobDeserializer$Builder
a1.sources.r1.batchsize = 1
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://172.17.154.226:9000/flume #改成你自己的hadoop路径
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollcount = 1
a1.sinks.k1.hdfs.rollsize = 0
#a1.sinks.k1.hdfs.filePrefix = logFile.%Y-%m-%d #监听的日志名称格式,前缀
a1.sinks.k1.hdfs.fileSuffix = .log ##监听的日志名称格式,后缀
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.idleTimeout = 60000
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1具体含义可以参考flume配置文章,我也是一知半解就不多解释了。有一点需要注意,将”flume-env.ps1.template”改名成”flume-env.ps1”,然后确保系统有执行powershell脚本的权限(我的win10不能执行.ps1文件,不知道为什么)
2. 去github上下载winutils,里面有若干hadoop的版本,我用的是3.0.0,下载后解压到本地目录,比如:“F:\Software\hadoop-3.0.0\bin”,这便是本地的hadoop home目录,一会儿启动flume的时候要用
3. 下载hadoop,这里没有3.0.0,我下的是3.0.2,这个是要安装在ubuntu上的,先解压出来,需要拷贝里面的*.jar包到flume的lib目录下。假定解压后的目录:D:\software\hadoop-3.0.2
4. 先将share\hadoop\common文件夹下的*.jar和share\hadoop\common\lib下的所有jar文件统统拷贝到flume的lib目录下,可能会提示有重复的,不管它覆盖掉(简单 暴力 有效),否则可能后面会出现什么java.io.之类的错误;继续拷贝,将D:\software\hadoop-3.0.2\share\hadoop\hdfs下的所有jar包扔进flume的lib目录下(对,就是 扔)
5. 暂时不管flume了,转战hadoop。将刚才下的hadoopxxxx.tar上传到ubuntu下
6. 创建一个名字为hadoop的普通用户并赋管理员权限
$ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell
$ sudo passwd hadoop #为hadoop用户设置密码,之后需要连续输入两次密码
$ sudo adduser hadoop sudo #为hadoop用户增加管理员权限
$ su - hadoop #切换当前用户为用户hadoop
$ sudo apt-get update #更新hadoop用户的apt,方便后面的安装- 设置ssh免密登录
$ sudo apt-get install openssh-server #安装SSH server
$ ssh localhost #登陆SSH,第一次登陆输入yes
$ exit #退出登录的ssh localhost
$ cd ~/.ssh/ #如果没法进入该目录,执行一次ssh localhost
$ ssh-keygen -t rsa- 然后再输入:
$ cat ./id_rsa.pub >> ./authorized_keys #加入授权
$ ssh localhost # 成功的话,此时不需要密码即可登录 - 安装hadoop
$ sudo tar -zxvf hadoop-3.0.2.tar.gz -C /usr/local #解压到/usr/local目录下
$ cd /usr/local
$ sudo mv hadoop-3.0.2 hadoop #重命名为hadoop
$ sudo chown -R hadoop ./hadoop #修改文件权限- 打开/home/hadoop/.bashrc,拉到最后添加:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64 #本机java路径
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
执行
source ~./bashrc使配置生效
====================配置hadoop伪分布式====================
定位到 /usr/local/hadoop/etc/hadoop/
修改core-site.xml文件:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.17.154.226:9000</value>
</property>
</configuration>修改配置文件 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>然后将改好的这两个文件扔到windows机器上的flume的conf文件夹下
执行 NameNode 的格式化
./bin/hdfs namenode -format启动namenode和datanode进程,并查看启动结果
./sbin/start-dfs.sh
jps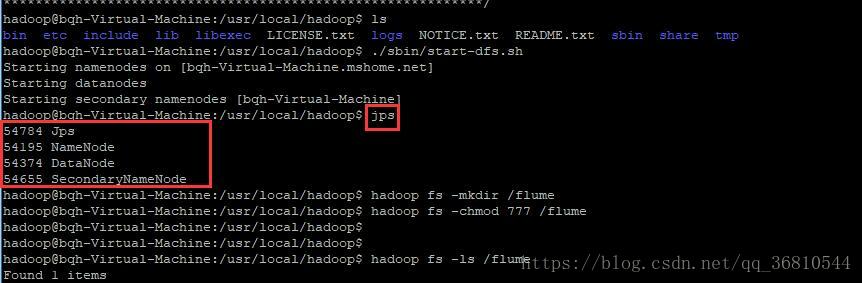
如果没有,可以执行”start-all.sh”试试
依上图命令,再创建一个flume目录用于接收windows上次的日志
hadoop fs -mkdir /flume
hadoop fs -chmod 777 /flume查看的话可以使用hadoop fs -ls /flume列出文件,使用hadoop fs -cat /flume/xxxxx查看文件内容
如果一切正常的话,在浏览器中输入:http://172.17.154.226:9870
注意:hadoop3.0以上版本的端口改成9870了,网上的好多教程用的都是50070,这个是2.x版本的
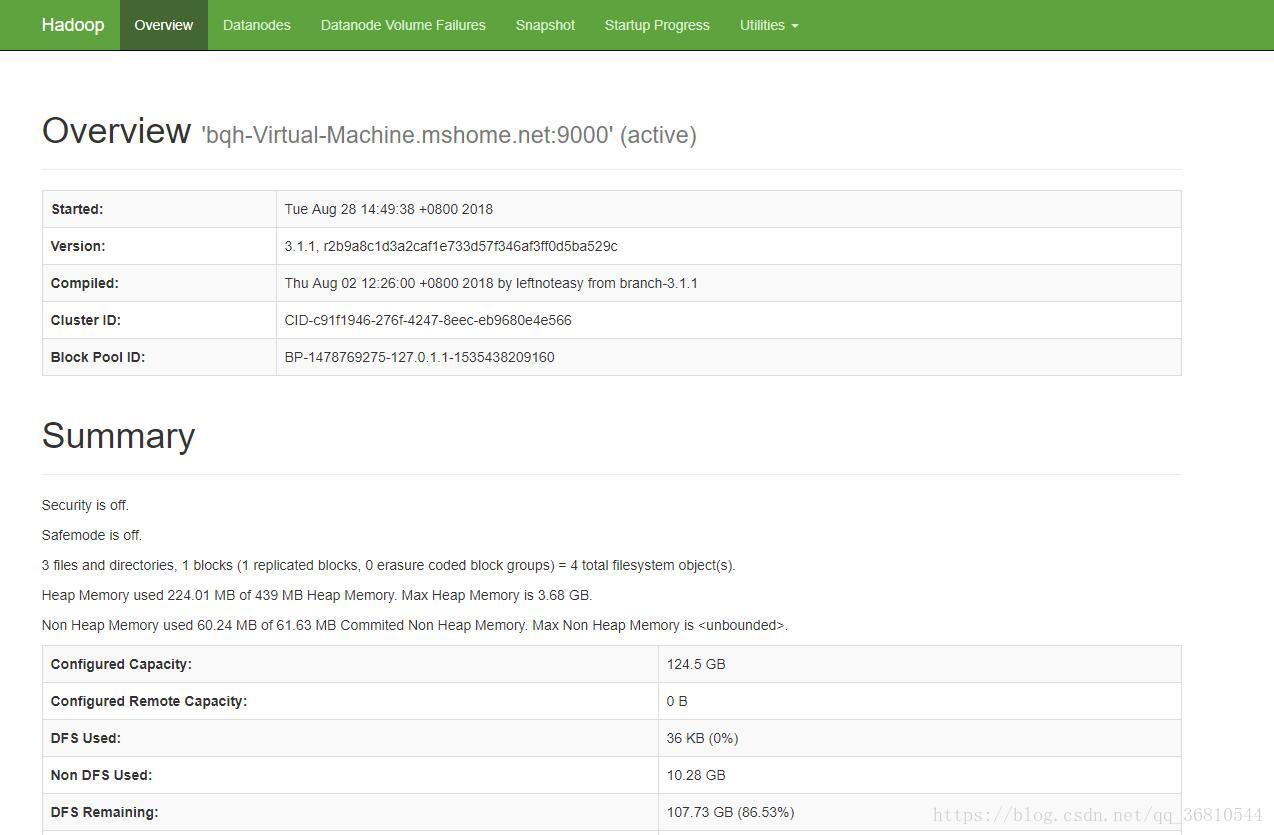
在8088端口可以看到 http://172.17.154.226:8088
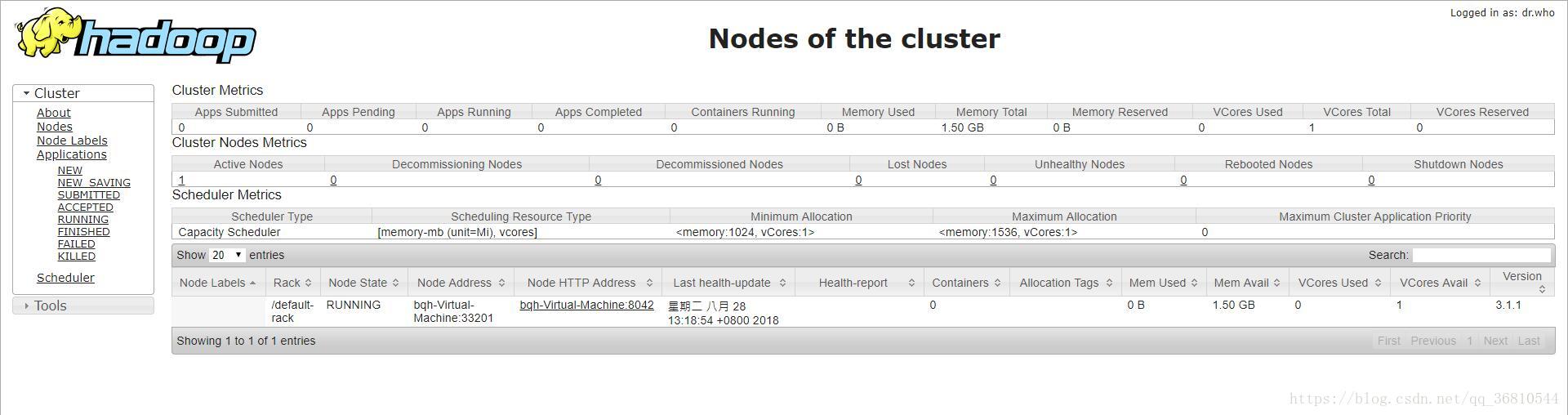
至此,hadoop搞定了。再次回到windows下
打开cmd并定位到flume的bin目录下,执行以下命令
flume-ng.cmd agent --conf ..\conf --conf-file ..\conf\test.conf --name a1 -property "flume.root.logger=INFO,LOGFILE,console;flume.log.file=MyLog.log;hadoop.home.dir=F:\Software\hadoop-3.0.0\bin"特别是最后的hadoop.home.dir就是之前解压的winunits路径下的bin目录,可能还是会出现警告,什么hadoop_home没有设置,找不到hadoopclasspath之类的,不管它。(其实我是不知道怎么解决)
随便建立一个文件名格式为”logFile.2018-09-14.log”的文本文件,内容随便,然后扔到D:\work\logs目录下,一切顺利的话,flume会自动同步文件到hdfs里了。打开hadoop的dashboard,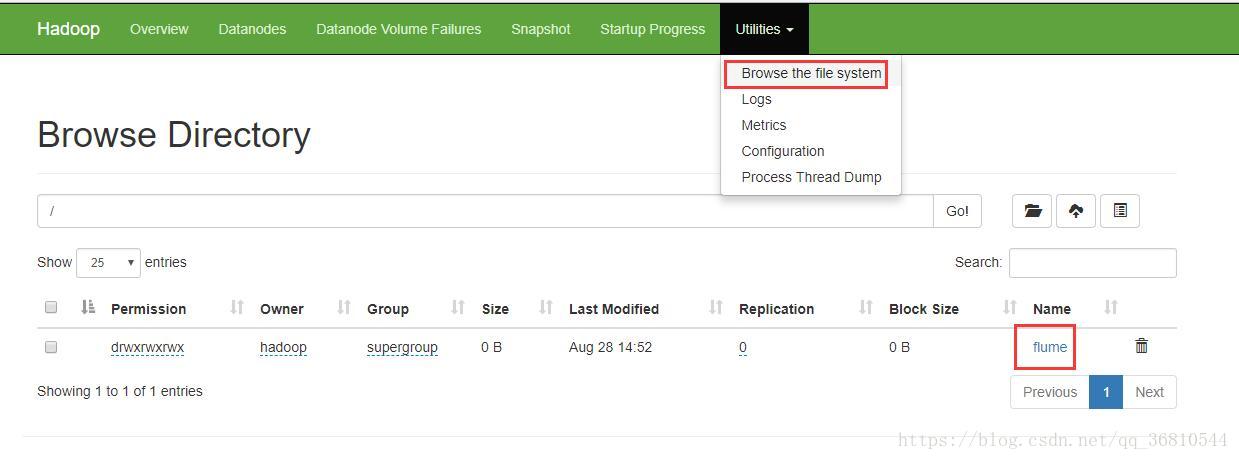
里面就是我们上传的日志了,只是命名格式有问题,这个后续解决。这只是演示,后续,最后是直接在代码级别将日志写进hdfs,log4j貌似可以的,但我需要的是c#。
==========================我填的坑=====================
首先,必须下载winunits,并在flume启动的时候指定本地的hadoop路径,不然根本就没有后面的java错误,刚开始还以为自己幸运一切顺利呢
然后就是各种java错误,实在不行就把hadoop\share\文件夹下所有jar都拷贝过来
最后,在hdfs namenode -format的时候,如果次数多了,可能会出现datanode启动失败的情况,删除/usr/local/hadoop/tmp/dfs目录下的data目录,然后重新建立一个,再次start-dfs.sh,然后用jps检查,确保各节点都运行起来。