这篇文章的一个启发点是使用Siamese网络和注意力模型将不同类别的特征集成,从而解决数据缺失的问题,然而文章中没有具体讲出注意力模型的参数是如何训练的,即模型上层如何得知下层不同子模型的数据是否缺失,是通过逻辑判断?还是直接用0值训练?或者用各模型的数据单独训练注意力参数?
原文地址 https://arxiv.org/abs/1809.02130
本文地址:https://www.cnblogs.com/kyxfx/p/9934211.html

1 简介
二手市场是用户买卖各种商品的平台。这些物品可以是低价值的,比如书籍和衣服,也可以是高价值的,比如汽车和房地产。卖家还可以发布一些虚拟的东西,比如招聘信息和服务。许多市场卖家是非专业的个人销售二手商品,因此二手市场可以被看作是一种特殊的电子商务类型,它包含一个非常大且分散的卖家群体并且跨多个类别的独特商品。
推荐系统在二手市场上广泛使用,以匹配与买家的兴趣和需求相关的物品。它比标准的电子商务产品推荐更具挑战性,原因有以下几点:(1)市场商品往往是二手的,因此在某种意义上是独特的。这就导致了特定物品的生存期很短。因此,冷启动问题非常突出。(2)非结构化数据往往描述不佳,使得传统的冷启动算法难以应用。(3)买家和卖家之间的互动往往难以追踪,因为它可能发生在平台之外。交易不总能被确认,所以推荐系统必须能够快速地将焦点从当前商品转移到相关的商品。
目前已经有大量的研究在离线指标上验证推荐系统。在本文中,我们描述了三种新的市场推荐产品,并通过在线实验对它们进行了基准测试,以测试它们在生产环境中的性能,在这种环境中,短寿命和低质量的内容是推荐产品的共同特征。我们在这里描述的三个模型是:(1)一个混合的项目-项目推荐器,它利用行为数据、图像和文本来构建一个健壮的项目表示,以应对冷启动问题。(2)基于序列的用户项目推荐器,具有时间性,可以利用上面的混合项表示快速构建用户的喜好。(3)一种更高级的多臂bandit算法,它将多个子模型建议的优先级划分为个性化的项目feed。它允许feed涵盖长期和短期的用户兴趣。
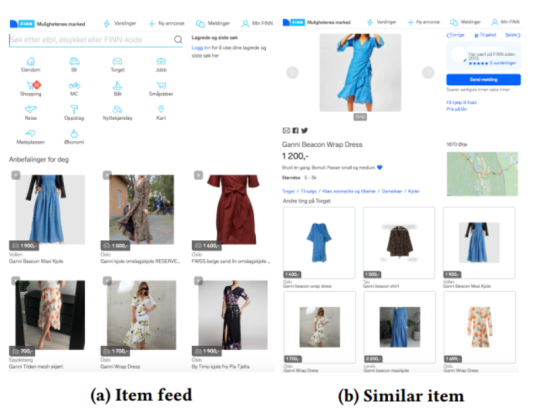
用于测试的生产环境是挪威二手市场的领头羊。它有超过100万的活跃项目在10+类和200+子类出售,每天服务超过100万的访问者。finn.no有两个推荐功能。在首页上有一个项目feed,在项目详情页上有一个相似条目推荐的小部件。每个功能的一个示例如图1所示。混合模型用于相似项目推荐,其余两个用于项目feed。
2 近期工作
搜索和发现是用户在内容平台上寻找相关条目的两种主要方式。近年来,利用推荐来改善发现体验一直是一个热门话题。协同过滤[1][18]和基于内容的方法[3][9]都是电子商务中经常使用的物品相似度排名方法。最近像LightFM[14]这样的工作将两者结合起来,以解决建议中的冷启动问题。像[21]和[15]这样的最先进的推荐系统经常使用学习-等级模型从一组复杂的特性中建模,包括文本、图像、用户属性、行为等。这种策略在市场推荐系统和[8]中都是有效的。此外,考虑较长的用户行为历史的串联[16]或序列注意力[22]模型显示了特别好的结果。我们的序列推荐系统从[2]中汲取了灵感,并在在线实验中表现出了积极的性能提升。在不同的用例中,多臂bandit被应用于多个来源之间的优先排序。例如,Pinterest[7]使用混合算法生成推荐内容和社交内容的混合feed。我们比较了几种多臂bandit模型,以融合市场场景中的行为和内容。
推荐器通常通过点击率和转化率在线对照实验[12]来进行评估。有一个很好的指标,比如预测评分和排名关联[10],可以用更低的前期成本,来替代在线测试。
3 实验平台
4 混合项目表示模型
与Lightfm[14]类似,我们将基于内容的特性与用户行为相结合,以解决协同过滤的冷启动问题。我们设计了一个混合模型,从用户行为、文本、图像和位置找到相似的项目。如图2a所示,我们首先单独训练项目表示,然后使用模型集成它们。
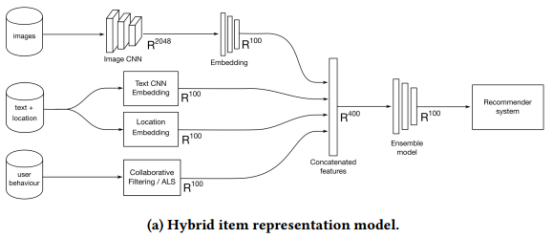


单个特征的生成方式如下:(i)基于行为的项表示来自用交替最小二乘(ALS)[19]实现的矩阵分解。训练数据包括20天的项目点击反馈和与卖家联系等的转换信号。转换信号更强(应该是指与卖家联系等),因此获得更多的权重。所有超参数通过offline和online实验进行调优。(ii)文本特征来自项目标题和描述中的非结构化自由文本。我们首先训练一个项目分类器,将文本映射到卖家指定的类别,然后提取这个分类器的顶层作为文本项表示。分类器是[4]卷积神经网络(CNN)体系结构的一种变体,使用的是在市场语料库上预先训练的word2vec[17]模型。(三)通过训练模型,从图像中预测项目标题,生成图像特征。上面提到的word2vec模型将标题投影到word嵌入中。我们使用标题而不是类别来分类图像。这给了我们一个更丰富的特性空间。例如,它可以让物品表示法区分“婚纱”和“夏装”,尽管它们都属于同一类别的“连衣裙”。该模型使用预训练的Inception-v3模型[20]的倒数第二层,并在顶部堆叠7个线性前馈层,以预测单词嵌入空间中的标题。然后通过最小化预测标题嵌入和实际标题嵌入之间的平均平方误差来训练它。(4)我们不使用简单的地理距离来表示位置,因为它可能具有误导性。还有一些隐藏的因素,比如人口密度和交通便利程度,影响着地理位置的影响。我们根据用户的历史行为训练位置表示,因为用户感兴趣的项目隐含地告诉了我们很多隐藏的因素。与(i)类似,我们分解一个用户邮编矩阵,并使用嵌入的邮编作为位置表示。
使用Siamese网络将不同的项表示合并为混合项表示。所有项表示都连接起来并通过一个注意层传递。如果缺少协同过滤特征,注意层允许模型更多地关注文本和图像特征,反之亦然。然后,由于基础服务的容量限制,一个高耸的前馈网络将这些特性压缩为100维的项目表示。用这个表示的余弦相似度比较两个项。训练数据由转化项对组成,即在同一天从同一用户获得转化的两个项,以及不太可能共同转化的负采样项对。潜在的假设是,共同转化的项目很可能是相似的。
5 基于时序的模型
基于时序的模型查看用户的点击记录,并预测下一步将点击哪些项。与矩阵分解相反,这种模型是时间敏感的,可以在预测中更多地考虑最近的点击。它们将用户点击的n个最新项投射到第4部分中描述的混合项表示所对应的项空间中。项目序列通过递归神经网络反馈。每一步t模型使用点击历史序列{ xt−n,…,xt } 预测未来序列{ xˆt + 1,……,xˆt + k } k步骤。余弦相似度计算预测在t+k处序列{ xˆt + 1,……,xˆt + k } t和实际点击序列{ xt + 1,……, xt+k}的准确性。
在[2]中,双层GRU是最优的体系结构。我们还使用LSTM或GRU测试了不同的变体,添加了额外的层叠重复层,或者增加了对输出的关注。然而,我们没有观察到比使用一个直接的GRU层有任何额外的显著改善。
6 多臂bandit模型
多臂bandit模型可以为一个特定的曝光生成一个实时feed。bandit自己不是推荐器,而是从独立子模型中接收建议作为输入的重排序器,通过用值函数估计其点击概率,将所有建议的项目重新从最相关的排序到最不相关的。子模型可以是任何类型的推荐器,例如基于序列的或矩阵分解,它将返回其最优建议及其相应的分数。通常,bandit连接到6-10个子模型。为了避免训练过程中的局部极小值,我们采用了简单的epson贪婪策略,并在每个推荐列表中随机添加5%的条目。
这种方法不同于[5]等将简单模型作为第一个过滤器(召回)引入更复杂模型的方法。相反,bandit使我们能够直接利用针对不同场景调优的性能良好的模型的结果。利用每个子模型的得分,以及访问时间、设备、登录页面类型(首页或分类首页)等上下文信息,重点评价子模型的可靠性。
第6.1节中描述的行分隔feed只是用于实验目的的简单基线。我们提出了两个不同的值函数来估计点击概率:第6.2节的回归bandit和第6.3节的深度分类bandit。前者的选择主要是由于其良好的解释性,而后者允许我们增加价值函数的复杂性,获得更好的在线性能。
6.1 行分隔feed
这个简单的基线有一个被混合的行数,并为每个子模型提供一行。行顺序也根据每个子模型的单独性能进行混合。我们选择这个设置是因为它通常被许多电子商务推荐插件所使用。
6.2回归bandit
回归bandit(regression bandit)作为它的名字,使用回归来近似基于子模型得分、子模型类型和上下文信息的点击概率。子模型得分分为10个分箱。剩下的特征是标签特征并进行独热编码。推荐表达是根据这些特性进行分组的,目标值是每组的平均点击次数。由于未正则化版本的权重经常会激增,因此岭回归模型适合于编码的特征。
6.3深度分类bandit
深度分类bandit将点击概率估计为一个分类问题。这使我们能够使用比回归bandit更复杂的函数来获得更大的特性集。
模型输入混合了标量(子模型得分、项目位置、日时等)和类型变量(子模型类型、位置、设备、工作日等)。对标量进行批归一化,对类型变量进行一次独热编码。在此基础上,建立了一种高耸的前馈网络,并输出了点击概率。该数据集包含不相等的点击 v.s.展示事件的比率(即只有一小部分推荐项目被点击),这可能会导致严重的训练不稳定性。通过在损失函数中引入类权值并对模型权值进行L2正则化来解决这个问题。
7结果与讨论
我们在类似的项目部件和如图1所示的项目feed上进行了在线实验。相似项目部件显示在项详细信息页面的底部或侧边栏中,假设用户对项详细信息感兴趣,因此对类似的项感兴趣,所以会查看该项详细信息。项目feed通常显示在市场的主要和分类首页,目的是为用户提供新的和相关的商品。我们选择在相似项目部件中测试混合项表示,而在项目feed中测试多臂bandit和基于序列的模型,因为项目-项目类型的模型无法在项目feed场景[11]中创建所需的创意性的体验。
实验结果如表1所示。绝对点击彻底率(CTR)由于季节性变化很大效果,新功能发布,等等。因此我们报告更稳定的CTR增量 ∆CTR =(CTRB−CTRA)/ CTRA当比较实验从不同时期。默认情况下,A/B测试将持续一周,以避免周末的季节性影响,并积累大约100万次相似项目部件的展示和500 - 1000万次项目feed的展示。为了简单起见,我们只在超参数调优后显示每种类型的最佳结果。
在类似的项目场景中,纯基于内容的项目表示模型比矩阵分解基线差7.7%,但是混合模型比基线好23.8%。这表明,与基于内容的功能相比,用户行为提供了更多相关的建议,但仍受到很多冷启动的影响。在整个实验过程中,我们观察到许多例子,其中混合模型使用基于内容的特性来处理点击次数很少的项目,而对于点击次数较多的项目,它给出的结果与矩阵分解方法相似
在在线实验中,基于序列的模型通常优于矩阵分解。当n = 1时,它们退化成一个项目-项目推荐者,仅使用最后看到的项目进行预测。我们要求n > 1,以便模型推广并且得出n = 15的历史行为与k = 5的预测数量范围提供最好的性能——提高了21.2%的CTR。
多臂bandit模型在两个不同基线的组中进行了测试,因为我们在中间引入了一个主要的用户界面(UI)重新设计。当我们用行分隔feed基线测试回归bandit时,我们观察到50.1%的CTR改善。我们将改进主要归因于回归bandit可以跨行混合子模型,而不受融合顺序的约束。一个有趣的观察是,矩阵分解子模型的分数与CTR之间没有单调的递增关系。在我们的实验中,CTR在分数达到0.8左右之前一直在增加,但在那之后迅速下降。调查显示,这些超高分项具有一定的病毒性倾向,不反映个人品味,因此不会转化为点击量。我们在回归中引入一个断点,允许点击概率估计在阈值之后下降,这又获得了5%的CTR改进。bandit还允许我们向feed添加更多的子模型,并开放了UI灵活性,以增加推荐的条目和连接的子模型的数量。在重新设计UI之后,CTR进一步增加。(线性)回归bandit的两个主要缺点是它不能估计观察到的子模型分数和CTR之间的非线性关系,而且它不是个性化的。回归函数不能处理为每个用户单独建模[by introducing per user aggregation. ]导致的维度爆炸问题。
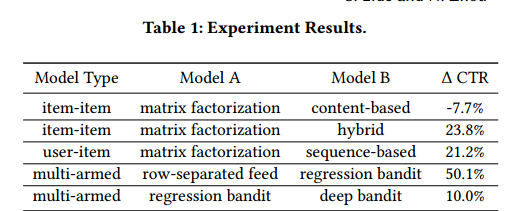
我们观察到深度分类bandit与回归bandit之间的对比测试约有10%的CTR改善。深度模型是个性化的,因为它能够使用包括用户嵌入在内的更多特性。
在实验过程中,我们也尝试了几种有潜力的方法,但都没有成功:(1)我们尝试了因子分解机来解决冷启动问题,但是工程成本很高,没有明显的CTR改善,所以我们最终选择了混合模型。(2)我们尝试只使用强信号如重复访问和发送消息来训练模型,但这些模型在短时间内由于数据量太小而表现更差。(3)虽然之前的工作和用户研究都表明多样性对于项目feed非常重要,但是当我们尝试使用基于类别计数的多样性度量显式地优化时,我们并没有得到显著的改进。(4)回归和深度分类值函数在训练过程中都存在较大的不稳定性,在生产使用中需要进行大量的稳定处理。
8 结论
在本文中,我们提出了三种新的市场推荐方法——混合项目表示、基于序列的模型、多臂bandit,并从生产环境分析了它们在在线实验中的表现。结果表明,在冷启动和基于序列的模型中,将协同过滤和内容特性相结合,可以更好地表示项目。我们还在推荐中展示了一个bandit的成功用例,它是在其他推荐者之上的高级再排序器。这些bandit对于利用上下文信息和组合多个业务领域的推荐器非常有用。
对于未来的工作,在上述模型仍然有很多可探索。一般来说,我们还没有对内容特性进行详细的探索。向项表示中添加更多的内容特性可以更有效地减少用户或项的冷启动问题。bandit模型的探索策略可以进一步改进:新的子模型仍然需要很长时间才能追上。此外,市场上的点击和交易不是瞬间发生的。商品的交易通常发生在用户第一次查看商品的数小时或数天之后,因此推荐的“奖励”可能会延迟到来。在强化学习框架使用模型可能会激励他们更广泛地探索,并提供更好的用户体验。
转发请注明:https://www.cnblogs.com/kyxfx/p/9934211.html