本文针对mnist手写数字集,搭建了四层简单的神经网络进行图片的分类,详细心得记录下来分享
我是采用的TensorFlow框架进行的训练
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data首先要加载数据集
#加载数据集
mnist = input_data.read_data_sets('MNIST_data',one_hot=True)
#设定批次大小
batch_size = 200
#计算批次数量
n_batch = mnist.train.num_examples // batch_size 加载数据集可以直接调用input_data下的read_data_sets方法,括号里的路径我是放在了当前目录下可以直接引用,当然也可以引用文件的绝对路径
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
keep_prob = tf.placeholder(tf.float32)接着创建三个placeholder占位符,None表示可以是任意维度的张量,784是由每一个手写数字为28*28的像素伸展成一维向量的原因,10表示待分为的0-910个类别,keep_prop表示神经网络训练时设置神经元的存活率,如果为1,表示所有神经元参与工作,相当于不设置这个值,如果为0.6表示有60%的神经元参与工作。
然后搭建四层神经网络
#第一层隐藏层,2000个神经元
W1 = tf.Variable(tf.truncated_normal([784,2000],stddev=0.1))
b1 = tf.Variable(tf.zeros([2000])+0.1)
L1 = tf.nn.tanh(tf.matmul(x,W1)+b1)
L1_drop = tf.nn.dropout(L1,keep_prob)
#第二层隐藏层
W2 = tf.Variable(tf.truncated_normal([2000,2000],stddev=0.1))
b2 = tf.Variable(tf.zeros([2000])+0.1)
L2 = tf.nn.tanh(tf.matmul(L1,W2)+b2)
L2_drop = tf.nn.dropout(L2,keep_prob)
#第三层神经网络
W3 = tf.Variable(tf.truncated_normal([2000,1000],stddev=0.1))
b3 = tf.Variable(tf.zeros([1000])+0.1)
L3 = tf.nn.tanh(tf.matmul(L2,W3)+b3)
L3_drop = tf.nn.dropout(L3,keep_prob)
#第四层神经网络
W4 = tf.Variable(tf.truncated_normal([1000,10],stddev=0.1))
b4 = tf.Variable(tf.zeros([10])+0.1)
prediction = tf.nn.tanh(tf.matmul(L3,W4)+b4)tf.truncated.normal为正态分布函数,stddev表示标准差为0.1
W为权值矩阵,b为偏置值,在第一层中有784个输入节点,2000个隐藏神经元。激活函数使用的是双曲正切函数tanh。值得注意的一点是,在每次计算Li的值时,需要使用Li-1的值和当前层数的权值矩阵加上当前层数的偏置值,在神经网络中表示由上一层的结果作用于本层神经网络,然后本层神经网络训练的值接着作用于下一层,依次循环。
#loss = tf.reduce_mean(tf.square(y-prediction))
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
optimizer = tf.train.GradientDescentOptimizer(0.4)
train = optimizer.minimize(loss)
注释掉的loss是用的二次代价损失函数,第二行loss是用的交叉熵损失函数然后求平均值,如果不求平均值的话效果会比使用二次代价损失函数查,还不清楚原因(欢迎留言讨论)。采用的梯度下降法来优化的,当然也可以采用其他的优化器,效果可以自己对比一下。
#初始化变量
init = tf.global_variables_initializer()accuracy_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
#计算准确率
accuracy = tf.reduce_mean(tf.cast(accuracy_prediction,tf.float32)) argmax表示返回一维张量最大值的位置,tf.equal(tf.argmax(y,1),tf.argmax(prediction,1)) 如果前面的位置和后面返回的位置一致,则输出1,否则为0。比如tf.argmax(y,1)实际最大值位置为4,tf.argmax(prediction,1)预测最大值位置为4,则返回1。所以accuracy_prediction里面存的全是布尔型值。tf.cast(accuracy_prediction,tf.float32)是将前者变量转换为后者数据类型
with tf.Session() as sess:
sess.run(init)
for epoch in range(20):
for batch in range(n_batch):
batch_xs,batch_ys = mnist.train.next_batch(batch_size) #batch_xs每次获得batch_size大小图片,batch_ys获得标签
sess.run(train,feed_dict={x:batch_xs,y:batch_ys,keep_prob:1.0}) #keep_prob值0.6表示6成神经元参与工作
#每一轮输出准确率
test_acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:0.6})
train_acc = sess.run(accuracy, feed_dict={x: mnist.train.images, y: mnist.train.labels, keep_prob: 0.6})
print('Iter:'+str(epoch)+' test_accuracy:'+str(test_acc)+' train_acc:'+str(train_acc))根据keep_prob的值不同做了一个特意的对比实验,当keep_prob的值设置为1时,训练结果部分如下:

从结果可以看出,训练的准确率比测试的准确率要高大约0.2个百分点,这样看起来可能比较小,但是一旦当数据集扩大,这种差距会非常大,造成过拟合的现象。
再把keep_prob的值设置为0.6时,得到实验结果如下
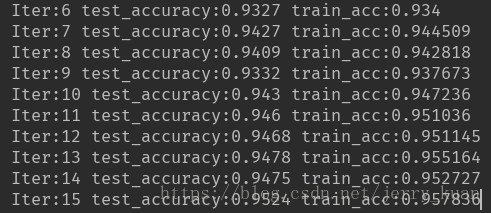
这样两者的差距在0.005左右,很大程度上缓解了过拟合现象。
原因因为当keep_prob的值设为1时所有的神经元全部参与,其实是相当于暴力的记忆住了当前的训练集,因此在训练集上有很好的效果,但是一旦离开这个训练集,就会没办法拟合新的数据点而导致准确率下降。而当值适当减小时,其实就是模拟了人脑的记忆曲线,总会有些东西是会遗忘的,因而在训练时虽然收敛的比较慢,但是泛化能力确增强了。