一、用户自定义函数分类
1.UDF 用户自定义格式转化函数(一条数据输入,一条数据输出)
2.udaf 用户自定义聚合函数(多条数据输入,一条数据输出)
3.udtf 用户自定义**函数(一条数据输入,多条数据输出)
二、开发Java代码
1.添加pom依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
<!-- Hive Client -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>2.java代码
package com.ibeifeng.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
/**
* 自定义函数
*/
public class TestHiveUDF_22 extends UDF {
public Text evaluate(Text str,IntWritable flag){
String value=str.toString();
if(flag.get()==0){
return new Text(value.toLowerCase());
}else if(flag.get()==1) {
return new Text(value.toUpperCase());
}else {
return new Text("flag参数异常");
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
System.out.println(new TestHiveUDF_22().evaluate(new Text("HAasd1OP"),new IntWritable(0)));
}
}3.Myeclipse打jar包
(1)选择制定类文件,右键-》Export

(2)然后配置如下

(3)然后其他默认,finish结束
E:\Tools\WorkspaceforMyeclipse\JarPackage下面找到Hive_udf_2.jar4.将自定义jar包与hive进行关联
(1)添加打的jar包
add jar /opt/datas/Hive_udf_2.jar;
结果:
Added [/opt/datas/Hive_udf_2.jar] to class path
Added resources: [/opt/datas/Hive_udf_2.jar](2)创建函数方法
//在java文件中,右键自己的class名称,选择copy qualified Name获得路径'com.ibeifeng.hive.udf.TestHiveUDF_22',如下图
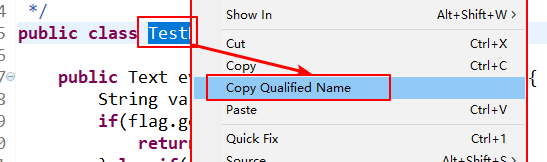
然后,创建函数
扫描二维码关注公众号,回复:
4031537 查看本文章

create temporary function my_udf as 'com.ibeifeng.hive.udf.TestHiveUDF_22';(3)使用
select ename, my_udf(ename,0) low_ename from emp;
结果:
ename low_ename
SMITH smith
ALLEN allen
WARD ward
JONES jones
MARTIN martin
BLAKE blake
CLARK clark
SCOTT scott
KING king
TURNER turner
ADAMS adams
JAMES james
FORD ford
MILLER miller
(4)创建永久udf
需要把jar包上传到hdfs上,然后就可以
-》上传
dfs -put /opt/datas/Hive_udf_2.jar /;-》加载
create function my_udf_hdfs as 'com.ibeifeng.hive.udf.TestHiveUDF_22' using jar 'hdfs://bigdata.ibeifeng.com:8020/Hive_udf_2.jar';-》关闭hive客户端
-》重新打开hive
bin/hive-》运行
select ename, my_udf_hdfs(ename,0) low_ename from emp;
成功:
ename low_ename
SMITH smith
ALLEN allen
WARD ward
JONES jones
MARTIN martin
BLAKE blake
CLARK clark
SCOTT scott
KING king
TURNER turner
ADAMS adams
JAMES james
FORD ford
MILLER miller