Spark Streaming实时流处理项目实战笔记一
视频资源下载:https://download.csdn.net/download/mys_mys/10778011
第一章:课程介绍
Hadoop环境:虚拟机Centos6.4
Window:VMware
本地登录到远程服务器:ssh hadoop@ip 密码:hadoop
修改配置文件,是需要root权限的,怎么办?
sudo command
只有一个地方需要修改:ip地址
/etc/hosts
192.168.199.128 hadoop000
192.168.199.128 localhost
在Linux的Hadoop用户的根目录下需要创建如下目录:
app 存放我们所需要的所有软件的安装目录
data 存放我们的测试数据
lib 存放我们开发的jar包
software 存放软件安装包的目录
source 存放我们的框架源码
版本介绍:
Hadoop生态系统:cdh5.7.0
jdk:1.8
spark:2.2
scala:2.11.8
初识实时流处理
需求:统计主站每个(指定)课程访问的客户端、地域信息分布、
地域:ip转换 (Spark SQL项目实战)
客户端:useragent获取 (Hadoop基础课程)
==> 如上两个操作:采用离线(Spark/MapReduce)的方式进行统计
实现步骤:
课程编号、ip信息、useragent
进行相应的统计分析操作:MapReduce/Spark
项目架构
日志收集:Flume
离线分析:MapReduce/Spark
统计结果图形化展示
问题
小时级别
10分钟
5分钟
1分钟
秒级别
如何解决??? ==》 实时流处理框架
离线计算与实时计算的对比
1) 数据来源
离线: HDFS 历史数据 数据量比较大
实时: 消息队列(Kafka),实时新增/修改记录过来的某一笔数据
2)处理过程
离线: MapReduce: map + reduce
实时: Spark(DStream/SS)
3) 处理速度
离线: 慢
实时: 快速
4)进程
离线: 启动+销毁
实时: 7*24
实时流处理框架的产生背景
时效性高 数据量大
实时流处理与离线处理的对比
1.数据来源
2.处理过程
3.处理速度
4.进程(MapReduce进程启动与销毁,需要消耗大量资源,而且实时性跟不上)
实时流框架对比
1.Storm(真正的来一个处理一个)
2.Spark Streaming(时间间隔小批次处理)
3.IBM Stream
4.Yahoo!S4
5.LinkedIn kafka、Flink(可离线可实时)
实时流处理架构与技术选型
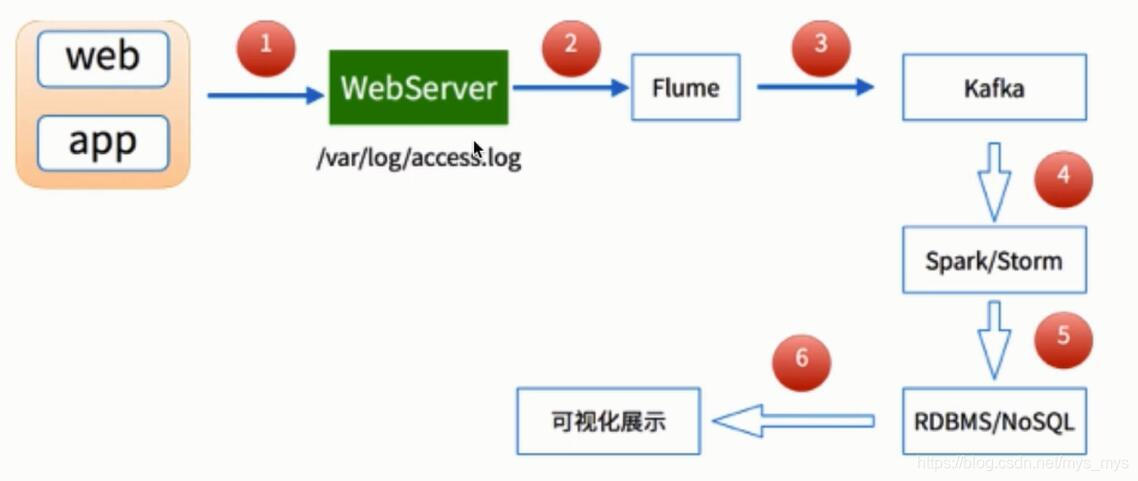
当查看课程或者搜索信息都会产生一个请求,有一条日志信息记录到web Server上,如Njxs/tomcat服务器,再通过flume收集,再通过消息队列Kafka,spark/storm实时流处理从Kafka获取,能够起到很好的缓冲作用,再将处理结果写道RDBMS/NoSQL中,再通过可视化展示出来。
实时流处理在企业中的应用
1)电信行业
当流量快使用完时,实时发送短信提醒
2)电商行业
购物时,买A产品,会推荐与A相似的B产品