Word2Vec模型
word2vec模型在NNLM模型的基础之上演变而来,我们的最终目的都是用函数拟合出一个句子的概率,这个概率可以拆分成多个概率相乘的形式,每个位置为P(wi|context)。NNLM用四层模型,求解出了这个概率值,而word2vec模型抛弃了其中最耗时的隐层,而且投影层是上下文词语向量直接相加而不是拼接而成,直接以概率值输出。
1 基于Hierarchical Softmax模型
Hierarchical(分层)softMax有两种模型,如下:
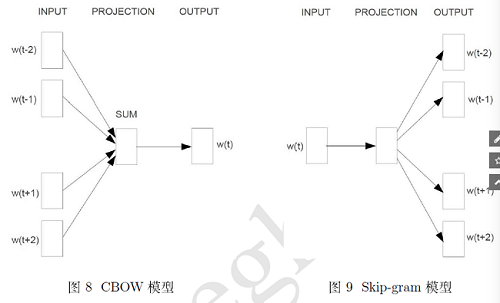
1.1 CBOW模型
直接将上下文的词向量相加,然后输出。我们这里假设某个词和其上下文分别为:
一共有2c个上下文词语,投影层直接将每个词的词向量相加:
输出层为一颗霍夫曼树,根据每个词语出现的频次构成了一颗霍夫曼树。所有的非叶节点存储有一个参数向量,所有的叶节点分别代表了词典中的一个词。参数向量初始值为0。构建完huffman树之后,将对应的huffman码分配给每个单词。此外,还需要随机初始化每个单词的词向量。
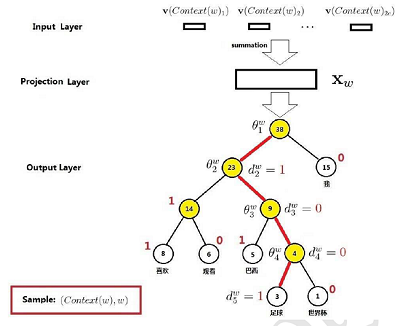
那么CBOW模型是怎么定义条件概率的呢?对于霍夫曼树的每一层都看做是一个二分类,分类的方法是LogisticRegression,为了与作者中的论文一致,假设树的左边表示分类为0,树的右边表示分类为1(与图片中有一些出入)。那么根据逻辑回归可以知道,分类为1的概率为:
对一棵树的每个叶子节点定义一个等长的向量theta,那么对于每个叶子节点,分为右子树的概率为:
那么,分为左子树的概率为
写在一起,可得到每一个节点j,下一个节点被分类的概率为:
所以,对于题目中的足球而言,需要经历四次分类才能走到叶子节点,这里的j一共有四次取值,从1到4,那么它的概率可以定义为:
那么整个语料C的所有概率,利用极大似然函数,可得到优化的代价函数为:
优化的目标参数为:
对于这里的足球而言,要求解的参数为5个。求解的方式采用梯度下降法:
交换位置,不难求出另外一个导数:
所以更新的策略为:
这里的xw是由多个词向量相加得到的,所以这里应该更新词向量v(context(w)),把梯度贡献到每一个词的词向量上,更新的策略也很简单:
所以我们并不会直接更新中心词的词向量,而是更新了跟中心词相关的其他词的词向量。更新的伪代码如下:

1.2 skip-gram模型
与CBOW模型正好相反,skip-gram模型是用当前的中心词去预测上下文的词语出现的概率,极大似然模型为,已知中心词出现了,那么让它的上下文出现的概率最大,他所求得概率为:
按照上一节的推导:
这里可以仔细再理解一下softmax模型,不难发现,所有的概率值加在一起的值为1。对于CBOW模型,我们计算的是已知当前词的上下文,中心词出现的概率。那么按照我们的这种模型,给定上下文,语料中所有词语出现的条件概率加在一起是不是等于1?很明显是成立的,因为这棵树的所有叶子节点的概率加在一起肯定等于1。对于skip-gram模型,同样的,它仍然是一棵树,给定当前中心词,语料中所有词语出现的概率和肯定为1,只不过我们这里的上下文出现的概率和不是1,但是全部词语出现的概率和肯定是1。所以这里为什么称之为Hierarchical softmax。
2 负例采样模型
Negative Sampling模型和层次softmax模型不一样,我们首先要从softmax的思维中跳出来。这里的输出概率加和并不一定为1。负例采样模型主要是为了提高训练速度并改善词语的训练质量,输出层不再采用复杂的哈夫曼树的模型,而是利用随机负采样。我们的任务仍然是求P(wi|contex_w),思想是定义两类词语,一类是这个中心词称为正样本,另外一类是从语料中随机抽取的其他词语,称为负样本。直接定义如下概率:
对于某个词,它的上下文组成的向量X仍然不变,这个向量与上下文词语有关。用不同的方式表达两类概率。直接用下面的公式表示已知上下文,中心词出现的概率:
这么定义之后,我们优化的代价函数不再是整个句子所对应的极大似然概率,而是最大化下面这个函数g,它的思想就是已知出现这么一堆上下文之后,我们要让中心词出现的概率大,正样本出现的概率大而负样本出现的概率小。通过这种模型,求解出相应的参数,我们仍然可以求出来这个概率P(wi|contex_w)。
同样的,取Log处理,得到我们的优化函数:
更新的方法仍然是梯度上升法:
同样的,词向量更新方式仍然一样:
2.1 基于skip-gram模型的负例采样算法
跟分层的softmax类似,对于skip-gram模型是要求出P(context|w),即在出现中心词的条件下每个上下文词语出现的概率。P(u|w)的定义可以按照上面的定义方式,定义u为正样本,随机抽取其他词语作为一个负样本:
相应的,我们的目标g,可以定义为:
对中心词的每一个上下文词语,都进行负采样,然后定义一个函数g,将这些中心词的g乘在一起。就可以得到我们这里的优化函数。
2.2 负例采样方法
采样的原则仍然是频次高的被选中的概率大,频次低的被选中的概率低。看下面两个线段,第一个线段表示假设语料中词语一共有N个词语,根据每个词语出现的频率构成这条线段,每个词出现的频率越高,当然占据的长度越长,从前到后依次往后排。第二条线段表示我们将一条线段等分为M份,每一个M对应着语料中的一个词,比如这里的m1,m2就对应着同一个词语。采样的方法为,每次随机生成一个1到M之间的数,找到这个数对应的词语就可以,如果刚好选到中心词了,那就直接跳过去。举个例子,如果我们随机到1,2,4,M-1这么几个数字,那么选的词就是第一个,第一个,第二个,第二个,和最后一个。
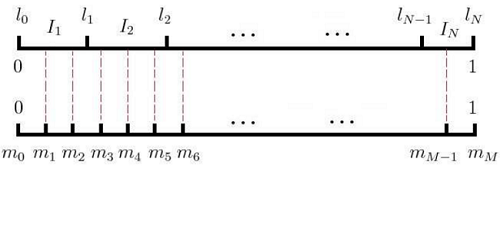
从论文中看出,一般第一条线段构造的时候,每段长度并不是直接用频次/频次的:
3 FastText分析
fasttext是基于word2Vec的CBOW模型改进而来,专门为文本分类而提出的算法,目的是为了提高训练的速度。训练的时候,将每句话的标签作为信息插入到每句话中作为中心词,其他词语作为上下文。输出以所有的标签构成一颗霍夫曼树。所以,这里预测的是已知上下文的条件下,当前标签的概率最大。构建模型的时候也是让这个条件概率值最大。
主要改进的方法有两个:一个是加入了N-gram特征,一句话,我爱你,可能词袋中只有三个词语,但是模型还加入了我爱,爱你等N-gram特征。另外一个是层次化的softmax,使得时间复杂度降低为log(k)。