一、课程介绍



二、函数式编程
- Python中函数式编程简介





- Python中高阶函数



-
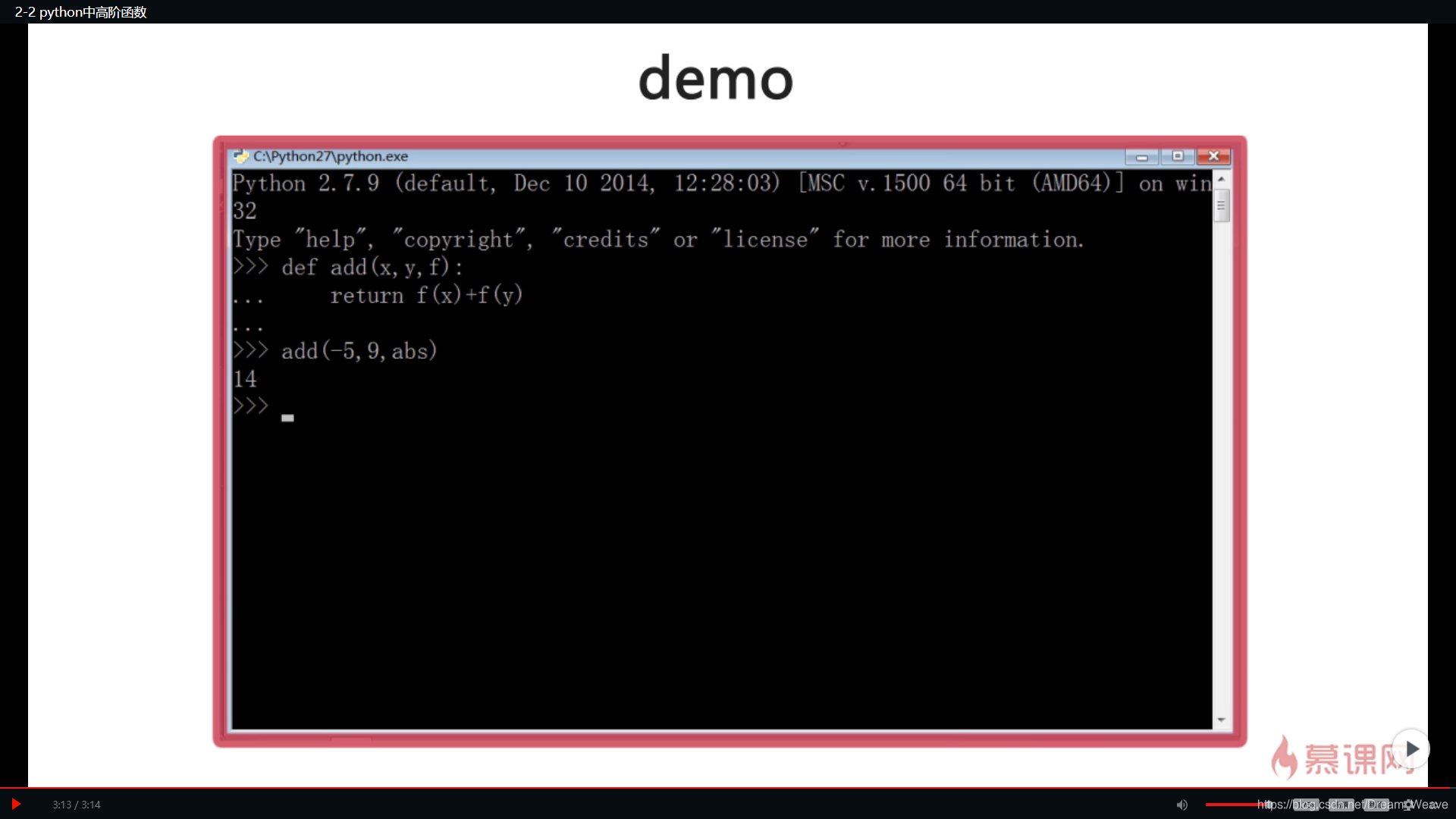
Python中map()函数
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。
例如,对于list [1, 2, 3, 4, 5, 6, 7, 8, 9]
如果希望把list的每个元素都作平方,就可以用map()函数:

因此,我们只需要传入函数f(x)=x*x,就可以利用map()函数完成这个计算:
def f(x): return x*x print map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])输出结果:
[1, 4, 9, 10, 25, 36, 49, 64, 81]注意:map()函数不改变原有的 list,而是返回一个新的 list。
扫描二维码关注公众号,回复: 4061547 查看本文章
利用map()函数,可以把一个 list 转换为另一个 list,只需要传入转换函数。
由于list包含的元素可以是任何类型,因此,map() 不仅仅可以处理只包含数值的 list,事实上它可以处理包含任意类型的 list,只要传入的函数f可以处理这种数据类型。
-
Python中reduce()函数
reduce()函数也是Python内置的一个高阶函数。reduce()函数接收的参数和 map()类似,一个函数 f,一个list,但行为和 map()不同,reduce()传入的函数 f 必须接收两个参数,reduce()对list的每个元素反复调用函数f,并返回最终结果值。
例如,编写一个f函数,接收x和y,返回x和y的和:
def f(x, y): return x + y调用 reduce(f, [1, 3, 5, 7, 9])时,reduce函数将做如下计算:
先计算头两个元素:f(1, 3),结果为4; 再把结果和第3个元素计算:f(4, 5),结果为9; 再把结果和第4个元素计算:f(9, 7),结果为16; 再把结果和第5个元素计算:f(16, 9),结果为25; 由于没有更多的元素了,计算结束,返回结果25。上述计算实际上是对 list 的所有元素求和。虽然Python内置了求和函数sum(),但是,利用reduce()求和也很简单。
reduce()还可以接收第3个可选参数,作为计算的初始值。如果把初始值设为100,计算:
reduce(f, [1, 3, 5, 7, 9], 100)结果将变为125,因为第一轮计算是:
计算初始值和第一个元素:f(100, 1),结果为101。
-
Python中filter()函数
filter()函数是 Python 内置的另一个有用的高阶函数,filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。
例如,要从一个list [1, 4, 6, 7, 9, 12, 17]中删除偶数,保留奇数,首先,要编写一个判断奇数的函数:
def is_odd(x): return x % 2 == 1然后,利用filter()过滤掉偶数:
filter(is_odd, [1, 4, 6, 7, 9, 12, 17])结果:[1, 7, 9, 17]
利用filter(),可以完成很多有用的功能,例如,删除 None 或者空字符串:
def is_not_empty(s): return s and len(s.strip()) > 0 filter(is_not_empty, ['test', None, '', 'str', ' ', 'END'])结果:['test', 'str', 'END']
注意: s.strip(rm) 删除 s 字符串中开头、结尾处的 rm 序列的字符。
当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' '),如下:
a = ' 123' a.strip()结果: '123'
a='\t\t123\r\n' a.strip()结果:'123'
任务
请利用filter()过滤出1~100中平方根是整数的数,即结果应该是:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
import math def is_sqr(x): return math.sqrt(x)%1==0 print filter(is_sqr, range(1, 101)) -
Python中自定义排序函数
Python内置的 sorted()函数可对list进行排序:
>>>sorted([36, 5, 12, 9, 21]) [5, 9, 12, 21, 36]但 sorted()也是一个高阶函数,它可以接收一个比较函数来实现自定义排序,比较函数的定义是,传入两个待比较的元素 x, y,如果 x 应该排在 y 的前面,返回 -1,如果 x 应该排在 y 的后面,返回 1。如果 x 和 y 相等,返回 0。
因此,如果我们要实现倒序排序,只需要编写一个reversed_cmp函数:
def reversed_cmp(x, y): if x > y: return -1 if x < y: return 1 return 0这样,调用 sorted() 并传入 reversed_cmp 就可以实现倒序排序:
>>> sorted([36, 5, 12, 9, 21], reversed_cmp) [36, 21, 12, 9, 5]sorted()也可以对字符串进行排序,字符串默认按照ASCII大小来比较:
>>> sorted(['bob', 'about', 'Zoo', 'Credit']) ['Credit', 'Zoo', 'about', 'bob']'Zoo'排在'about'之前是因为'Z'的ASCII码比'a'小。
-
Python中返回函数
Python的函数不但可以返回int、str、list、dict等数据类型,还可以返回函数!
例如,定义一个函数 f(),我们让它返回一个函数 g,可以这样写:
def f(): print 'call f()...' # 定义函数g: def g(): print 'call g()...' # 返回函数g: return g仔细观察上面的函数定义,我们在函数 f 内部又定义了一个函数 g。由于函数 g 也是一个对象,函数名 g 就是指向函数 g 的变量,所以,最外层函数 f 可以返回变量 g,也就是函数 g 本身。
调用函数 f,我们会得到 f 返回的一个函数:
>>> x = f() # 调用f() call f()... >>> x # 变量x是f()返回的函数: <function g at 0x1037bf320> >>> x() # x指向函数,因此可以调用 call g()... # 调用x()就是执行g()函数定义的代码请注意区分返回函数和返回值:
def myabs(): return abs # 返回函数 def myabs2(x): return abs(x) # 返回函数调用的结果,返回值是一个数值返回函数可以把一些计算延迟执行。例如,如果定义一个普通的求和函数:
def calc_sum(lst): return sum(lst)调用calc_sum()函数时,将立刻计算并得到结果:
>>> calc_sum([1, 2, 3, 4]) 10但是,如果返回一个函数,就可以“延迟计算”:
def calc_sum(lst): def lazy_sum(): return sum(lst) return lazy_sum# 调用calc_sum()并没有计算出结果,而是返回函数:
>>> f = calc_sum([1, 2, 3, 4]) >>> f <function lazy_sum at 0x1037bfaa0># 对返回的函数进行调用时,才计算出结果:
>>> f() 10由于可以返回函数,我们在后续代码里就可以决定到底要不要调用该函数。
任务
请编写一个函数calc_prod(lst),它接收一个list,返回一个函数,返回函数可以计算参数的乘积。
def calc_prod(lst): def prod(x,y): return x*y def fun(): return reduce(prod,lst) return fun f = calc_prod([1, 2, 3, 4]) print f() -
Python中闭包
在函数内部定义的函数和外部定义的函数是一样的,只是他们无法被外部访问:
def g(): print 'g()...' def f(): print 'f()...' return g将 g 的定义移入函数 f 内部,防止其他代码调用 g:
def f(): print 'f()...' def g(): print 'g()...' return g但是,考察上一小节定义的 calc_sum 函数:
def calc_sum(lst): def lazy_sum(): return sum(lst) return lazy_sum注意: 发现没法把 lazy_sum 移到 calc_sum 的外部,因为它引用了 calc_sum 的参数 lst。
像这种内层函数引用了外层函数的变量(参数也算变量),然后返回内层函数的情况,称为闭包(Closure)。
闭包的特点是返回的函数还引用了外层函数的局部变量,所以,要正确使用闭包,就要确保引用的局部变量在函数返回后不能变。举例如下:
# 希望一次返回3个函数,分别计算1x1,2x2,3x3: def count(): fs = [] for i in range(1, 4): def f(): return i*i fs.append(f) return fs f1, f2, f3 = count()你可能认为调用f1(),f2()和f3()结果应该是1,4,9,但实际结果全部都是 9(请自己动手验证)。
原因就是当count()函数返回了3个函数时,这3个函数所引用的变量 i 的值已经变成了3。由于f1、f2、f3并没有被调用,所以,此时他们并未计算 i*i,当 f1 被调用时:
>>> f1() 9 # 因为f1现在才计算i*i,但现在i的值已经变为3因此,返回函数不要引用任何循环变量,或者后续会发生变化的变量。
任务
返回闭包不能引用循环变量,请改写count()函数,让它正确返回能计算1x1、2x2、3x3的函数。
def count(): fs = [] for i in range(1, 4): def f(i=i): # default return i*i fs.append(f) return fs f1, f2, f3 = count() print f1(), f2(), f3() # 因为上面属于default,所以可以省略 -
Python中匿名函数
高阶函数可以接收函数做参数,有些时候,我们不需要显式地定义函数,直接传入匿名函数更方便。
在Python中,对匿名函数提供了有限支持。还是以map()函数为例,计算 f(x)=x2 时,除了定义一个f(x)的函数外,还可以直接传入匿名函数:
>>> map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]) [1, 4, 9, 16, 25, 36, 49, 64, 81]通过对比可以看出,匿名函数 lambda x: x * x 实际上就是:
def f(x): return x * x关键字lambda 表示匿名函数,冒号前面的 x 表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不写return,返回值就是该表达式的结果。
使用匿名函数,可以不必定义函数名,直接创建一个函数对象,很多时候可以简化代码:
>>> sorted([1, 3, 9, 5, 0], lambda x,y: -cmp(x,y)) [9, 5, 3, 1, 0]返回函数的时候,也可以返回匿名函数:
>>> myabs = lambda x: -x if x < 0 else x >>> myabs(-1) 1 >>> myabs(1) 1 - 待更新...
三、装饰器
- Python中decorator装饰器




-
Python中编写无参数decorator
Python的 decorator 本质上就是一个高阶函数,它接收一个函数作为参数,然后,返回一个新函数。
使用 decorator 用Python提供的 @ 语法,这样可以避免手动编写f = decorate(f) 这样的代码。
考察一个@log的定义:
def log(f): def fn(x): print 'call ' + f.__name__ + '()...' return f(x) return fn对于阶乘函数,@log工作得很好:
@log def factorial(n): return reduce(lambda x,y: x*y, range(1, n+1)) print factorial(10)结果:
call factorial()... 3628800但是,对于参数不是一个的函数,调用将报错:
@log def add(x, y): return x + y print add(1, 2)结果:
Traceback (most recent call last): File "test.py", line 15, in <module> print add(1,2) TypeError: fn() takes exactly 1 argument (2 given)因为 add() 函数需要传入两个参数,但是 @log 写死了只含一个参数的返回函数。
要让 @log 自适应任何参数定义的函数,可以利用Python的 *args 和 **kw,保证任意个数的参数总是能正常调用:
def log(f): def fn(*args, **kw): print 'call ' + f.__name__ + '()...' return f(*args, **kw) return fn现在,对于任意函数,@log 都能正常工作。
Ps:以*开头开头表示可以传递一个元元组进去,类似于(1,2,3);**开头是表示可以接受一个字典,类似于{'a'=1,'b'=2}。
任务
请编写一个@performance,它可以打印出函数调用的时间。
import time def performance(f): def fun(x): print 'call',f.__name__+'()','in',time.strftime('%Y-%m-%d',time.localtime(time.time())) return f(x) return fun @performance def factorial(n): return reduce(lambda x,y: x*y, range(1, n+1)) print factorial(10) -
Python中编写带参数decorator
考察上一节的 @log 装饰器:
def log(f): def fn(x): print 'call ' + f.__name__ + '()...' return f(x) return fn发现对于被装饰的函数,log打印的语句是不能变的(除了函数名)。
如果有的函数非常重要,希望打印出'[INFO] call xxx()...',有的函数不太重要,希望打印出'[DEBUG] call xxx()...',这时,log函数本身就需要传入'INFO'或'DEBUG'这样的参数,类似这样:
@log('DEBUG') def my_func(): pass把上面的定义翻译成高阶函数的调用,就是:
my_func = log('DEBUG')(my_func)上面的语句看上去还是比较绕,再展开一下:
log_decorator = log('DEBUG') my_func = log_decorator(my_func)上面的语句又相当于:
log_decorator = log('DEBUG') @log_decorator def my_func(): pass所以,带参数的log函数首先返回一个decorator函数,再让这个decorator函数接收my_func并返回新函数:
def log(prefix): def log_decorator(f): def wrapper(*args, **kw): print '[%s] %s()...' % (prefix, f.__name__) return f(*args, **kw) return wrapper return log_decorator @log('DEBUG') def test(): pass print test()执行结果:
[DEBUG] test()... None对于这种3层嵌套的decorator定义,你可以先把它拆开:
# 标准decorator: def log_decorator(f): def wrapper(*args, **kw): print '[%s] %s()...' % (prefix, f.__name__) return f(*args, **kw) return wrapper return log_decorator # 返回decorator: def log(prefix): return log_decorator(f)拆开以后会发现,调用会失败,因为在3层嵌套的decorator定义中,最内层的wrapper引用了最外层的参数prefix,所以,把一个闭包拆成普通的函数调用会比较困难。不支持闭包的编程语言要实现同样的功能就需要更多的代码。
Ps:带参数decorator,也就是在无参decorator的最外层再加上一层def即可。
任务
上一节的@performance只能打印秒,请给 @performace 增加一个参数,允许传入's'或'ms':
@performance('ms') def factorial(n): return reduce(lambda x,y: x*y, range(1, n+1))import time def performance(unit): def perf_decorator(f): def wrapper(*args,**kw): t1=time.time() fun=f(*args,**kw) t2=time.time() ts=(t2-t1)*1000 if unit=='ms' else (t2-t1) print 'call %s() in %d %s' %(f.__name__,ts,unit) return fun return wrapper return perf_decorator @performance('ms') def factorial(n): return reduce(lambda x,y: x*y, range(1, n+1)) print factorial(10) -
Python中完善decorator
@decorator可以动态实现函数功能的增加,但是,经过@decorator“改造”后的函数,和原函数相比,除了功能多一点外,有没有其它不同的地方?
在没有decorator的情况下,打印函数名:
def f1(x): pass print f1.__name__输出: f1
有decorator的情况下,再打印函数名:
def log(f): def wrapper(*args, **kw): print 'call...' return f(*args, **kw) return wrapper @log def f2(x): pass print f2.__name__输出: wrapper
可见,由于decorator返回的新函数函数名已经不是'f2',而是@log内部定义的'wrapper'。这对于那些依赖函数名的代码就会失效。decorator还改变了函数的__doc__等其它属性。如果要让调用者看不出一个函数经过了@decorator的“改造”,就需要把原函数的一些属性复制到新函数中:
def log(f): def wrapper(*args, **kw): print 'call...' return f(*args, **kw) wrapper.__name__ = f.__name__ wrapper.__doc__ = f.__doc__ return wrapper这样写decorator很不方便,因为我们也很难把原函数的所有必要属性都一个一个复制到新函数上,所以Python内置的functools可以用来自动化完成这个“复制”的任务:
import functools def log(f): @functools.wraps(f) def wrapper(*args, **kw): print 'call...' return f(*args, **kw) return wrapper最后需要指出,由于我们把原函数签名改成了(*args, **kw),因此,无法获得原函数的原始参数信息。即便我们采用固定参数来装饰只有一个参数的函数:
def log(f): @functools.wraps(f) def wrapper(x): print 'call...' return f(x) return wrapper也可能改变原函数的参数名,因为新函数的参数名始终是 'x',原函数定义的参数名不一定叫 'x'。
任务
请思考带参数的@decorator,@functools.wraps应该放置在哪:
def performance(unit): def perf_decorator(f): def wrapper(*args, **kw): ??? return wrapper return perf_decorator -
import time, functools def performance(unit): def perf_decorator(f): @functools.wraps(f) def wrapper(*args,**kw): return f(*args,**kw) return wrapper return perf_decorator @performance('ms') def factorial(n): return reduce(lambda x,y: x*y, range(1, n+1)) print factorial.__name__Python中偏函数
当一个函数有很多参数时,调用者就需要提供多个参数。如果减少参数个数,就可以简化调用者的负担。
比如,int()函数可以把字符串转换为整数,当仅传入字符串时,int()函数默认按十进制转换:
>>> int('12345') 12345但int()函数还提供额外的base参数,默认值为10。如果传入base参数,就可以做 N 进制的转换:
>>> int('12345', base=8) 5349 >>> int('12345', 16) 74565假设要转换大量的二进制字符串,每次都传入int(x, base=2)非常麻烦,于是,我们想到,可以定义一个int2()的函数,默认把base=2传进去:
def int2(x, base=2): return int(x, base)这样,我们转换二进制就非常方便了:
>>> int2('1000000') 64 >>> int2('1010101') 85functools.partial就是帮助我们创建一个偏函数的,不需要我们自己定义int2(),可以直接使用下面的代码创建一个新的函数int2:
>>> import functools >>> int2 = functools.partial(int, base=2) >>> int2('1000000') 64 >>> int2('1010101') 85所以,functools.partial可以把一个参数多的函数变成一个参数少的新函数,少的参数需要在创建时指定默认值,这样,新函数调用的难度就降低了。
任务
在第7节中,我们在sorted这个高阶函数中传入自定义排序函数就可以实现忽略大小写排序。请用functools.partial把这个复杂调用变成一个简单的函数:
sorted_ignore_case(iterable)import functools sorted_ignore_case = functools.partial(sorted, key=str.lower) print sorted_ignore_case(['bob', 'about', 'Zoo', 'Credit']) -
待更新...
四、模块
- 简介







-
Python之导入模块
要使用一个模块,我们必须首先导入该模块。Python使用import语句导入一个模块。例如,导入系统自带的模块 math:
import math你可以认为math就是一个指向已导入模块的变量,通过该变量,我们可以访问math模块中所定义的所有公开的函数、变量和类:
>>> math.pow(2, 0.5) # pow是函数 1.4142135623730951 >>> math.pi # pi是变量 3.141592653589793如果我们只希望导入用到的math模块的某几个函数,而不是所有函数,可以用下面的语句:
from math import pow, sin, log这样,可以直接引用 pow, sin, log 这3个函数,但math的其他函数没有导入进来:
>>> pow(2, 10) 1024.0 >>> sin(3.14) 0.0015926529164868282如果遇到名字冲突怎么办?比如math模块有一个log函数,logging模块也有一个log函数,如果同时使用,如何解决名字冲突?
如果使用import导入模块名,由于必须通过模块名引用函数名,因此不存在冲突:
import math, logging print math.log(10) # 调用的是math的log函数 logging.log(10, 'something') # 调用的是logging的log函数如果使用 from...import 导入 log 函数,势必引起冲突。这时,可以给函数起个“别名”来避免冲突:
from math import log from logging import log as logger # logging的log现在变成了logger print log(10) # 调用的是math的log logger(10, 'import from logging') # 调用的是logging的log -
Python中动态导入模块
如果导入的模块不存在,Python解释器会报 ImportError 错误:
>>> import something Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: No module named something有的时候,两个不同的模块提供了相同的功能,比如 StringIO 和 cStringIO 都提供了StringIO这个功能。
这是因为Python是动态语言,解释执行,因此Python代码运行速度慢。
如果要提高Python代码的运行速度,最简单的方法是把某些关键函数用 C 语言重写,这样就能大大提高执行速度。
同样的功能,StringIO 是纯Python代码编写的,而 cStringIO 部分函数是 C 写的,因此 cStringIO 运行速度更快。
利用ImportError错误,我们经常在Python中动态导入模块:
try: from cStringIO import StringIO except ImportError: from StringIO import StringIO上述代码先尝试从cStringIO导入,如果失败了(比如cStringIO没有被安装),再尝试从StringIO导入。这样,如果cStringIO模块存在,则我们将获得更快的运行速度,如果cStringIO不存在,则顶多代码运行速度会变慢,但不会影响代码的正常执行。
try 的作用是捕获错误,并在捕获到指定错误时执行 except 语句。
-
Python之使用__future__
Python的新版本会引入新的功能,但是,实际上这些功能在上一个老版本中就已经存在了。要“试用”某一新的特性,就可以通过导入__future__模块的某些功能来实现。
例如,Python 2.7的整数除法运算结果仍是整数:
>>> 10 / 3 3但是,Python 3.x已经改进了整数的除法运算,“/”除将得到浮点数,“//”除才仍是整数:
>>> 10 / 3 3.3333333333333335 >>> 10 // 3 3要在Python 2.7中引入3.x的除法规则,导入__future__的division:
>>> from __future__ import division >>> print 10 / 3 3.3333333333333335当新版本的一个特性与旧版本不兼容时,该特性将会在旧版本中添加到__future__中,以便旧的代码能在旧版本中测试新特性。
- Python之安装第三方模块


- 待更新...
五、面向对象编程基础
- 简介



-
Python之定义类并创建实例
在Python中,类通过 class 关键字定义。以 Person 为例,定义一个Person类如下:
class Person(object): pass按照 Python 的编程习惯,类名以大写字母开头,紧接着是(object),表示该类是从哪个类继承下来的。类的继承将在后面的章节讲解,现在我们只需要简单地从object类继承。
有了Person类的定义,就可以创建出具体的xiaoming、xiaohong等实例。创建实例使用 类名+(),类似函数调用的形式创建:
xiaoming = Person() xiaohong = Person() -
Python中创建实例属性
虽然可以通过Person类创建出xiaoming、xiaohong等实例,但是这些实例看上除了地址不同外,没有什么其他不同。在现实世界中,区分xiaoming、xiaohong要依靠他们各自的名字、性别、生日等属性。
如何让每个实例拥有各自不同的属性?由于Python是动态语言,对每一个实例,都可以直接给他们的属性赋值,例如,给xiaoming这个实例加上name、gender和birth属性:
xiaoming = Person() xiaoming.name = 'Xiao Ming' xiaoming.gender = 'Male' xiaoming.birth = '1990-1-1'给xiaohong加上的属性不一定要和xiaoming相同:
xiaohong = Person() xiaohong.name = 'Xiao Hong' xiaohong.school = 'No. 1 High School' xiaohong.grade = 2实例的属性可以像普通变量一样进行操作:
xiaohong.grade = xiaohong.grade + 1任务
请创建包含两个 Person 类的实例的 list,并给两个实例的 name 赋值,然后按照 name 进行排序。
class Person(object): pass p1 = Person() p1.name = 'Bart' p2 = Person() p2.name = 'Adam' p3 = Person() p3.name = 'Lisa' L1 = [p1, p2, p3] L2 = sorted(L1,key=lambda x: x.name) print L2[0].name print L2[1].name print L2[2].name -
Python中初始化实例属性
虽然我们可以自由地给一个实例绑定各种属性,但是,现实世界中,一种类型的实例应该拥有相同名字的属性。例如,Person类应该在创建的时候就拥有 name、gender 和 birth 属性,怎么办?
在定义 Person 类时,可以为Person类添加一个特殊的__init__()方法,当创建实例时,__init__()方法被自动调用,我们就能在此为每个实例都统一加上以下属性:
class Person(object): def __init__(self, name, gender, birth): self.name = name self.gender = gender self.birth = birth__init__() 方法的第一个参数必须是 self(也可以用别的名字,但建议使用习惯用法),后续参数则可以自由指定,和定义函数没有任何区别。
相应地,创建实例时,就必须要提供除 self 以外的参数:
xiaoming = Person('Xiao Ming', 'Male', '1991-1-1') xiaohong = Person('Xiao Hong', 'Female', '1992-2-2')有了__init__()方法,每个Person实例在创建时,都会有 name、gender 和 birth 这3个属性,并且,被赋予不同的属性值,访问属性使用.操作符:
print xiaoming.name # 输出 'Xiao Ming' print xiaohong.birth # 输出 '1992-2-2'要特别注意的是,初学者定义__init__()方法常常忘记了 self 参数:
>>> class Person(object): ... def __init__(name, gender, birth): ... pass ... >>> xiaoming = Person('Xiao Ming', 'Male', '1990-1-1') Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: __init__() takes exactly 3 arguments (4 given)这会导致创建失败或运行不正常,因为第一个参数name被Python解释器传入了实例的引用,从而导致整个方法的调用参数位置全部没有对上。
-
Python中访问限制
我们可以给一个实例绑定很多属性,如果有些属性不希望被外部访问到怎么办?
Python对属性权限的控制是通过属性名来实现的,如果一个属性由双下划线开头(__),该属性就无法被外部访问。看例子:
class Person(object): def __init__(self, name): self.name = name self._title = 'Mr' self.__job = 'Student' p = Person('Bob') print p.name # => Bob print p._title # => Mr print p.__job # => Error Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Person' object has no attribute '__job'可见,只有以双下划线开头的"__job"不能直接被外部访问。
但是,如果一个属性以"__xxx__"的形式定义,那它又可以被外部访问了,以"__xxx__"定义的属性在Python的类中被称为特殊属性,有很多预定义的特殊属性可以使用,通常我们不要把普通属性用"__xxx__"定义。
以单下划线开头的属性"_xxx"虽然也可以被外部访问,但是,按照习惯,他们不应该被外部访问。
-
Python中创建类属性
类是模板,而实例则是根据类创建的对象。
绑定在一个实例上的属性不会影响其他实例,但是,类本身也是一个对象,如果在类上绑定一个属性,则所有实例都可以访问类的属性,并且,所有实例访问的类属性都是同一个!也就是说,实例属性每个实例各自拥有,互相独立,而类属性有且只有一份。
定义类属性可以直接在 class 中定义:
class Person(object): address = 'Earth' def __init__(self, name): self.name = name因为类属性是直接绑定在类上的,所以,访问类属性不需要创建实例,就可以直接访问:
print Person.address # => Earth对一个实例调用类的属性也是可以访问的,所有实例都可以访问到它所属的类的属性:
p1 = Person('Bob') p2 = Person('Alice') print p1.address # => Earth print p2.address # => Earth由于Python是动态语言,类属性也是可以动态添加和修改的:
Person.address = 'China' print p1.address # => 'China' print p2.address # => 'China'因为类属性只有一份,所以,当Person类的address改变时,所有实例访问到的类属性都改变了。
任务
请给 Person 类添加一个类属性 count,每创建一个实例,count 属性就加 1,这样就可以统计出一共创建了多少个 Person 的实例。
class Person(object): count=0 def __init__(self, name): self.name=name Person.count=1+Person.count p1 = Person('Bob') print Person.count p2 = Person('Alice') print Person.count p3 = Person('Tim') print Person.count -
Python中类属性和实例属性名字冲突怎么办
修改类属性会导致所有实例访问到的类属性全部都受影响,但是,如果在实例变量上修改类属性会发生什么问题呢?
class Person(object): address = 'Earth' def __init__(self, name): self.name = name p1 = Person('Bob') p2 = Person('Alice') print 'Person.address = ' + Person.address p1.address = 'China' print 'p1.address = ' + p1.address print 'Person.address = ' + Person.address print 'p2.address = ' + p2.address结果如下:
Person.address = Earth p1.address = China Person.address = Earth p2.address = Earth我们发现,在设置了 p1.address = 'China' 后,p1访问 address 确实变成了 'China',但是,Person.address和p2.address仍然是'Earch',怎么回事?
原因是 p1.address = 'China'并没有改变 Person 的 address,而是给 p1这个实例绑定了实例属性address ,对p1来说,它有一个实例属性address(值是'China'),而它所属的类Person也有一个类属性address,所以:
访问 p1.address 时,优先查找实例属性,返回'China'。
访问 p2.address 时,p2没有实例属性address,但是有类属性address,因此返回'Earth'。
可见,当实例属性和类属性重名时,实例属性优先级高,它将屏蔽掉对类属性的访问。
当我们把 p1 的 address 实例属性删除后,访问 p1.address 就又返回类属性的值 'Earth'了:
del p1.address print p1.address # => Earth可见,千万不要在实例上修改类属性,它实际上并没有修改类属性,而是给实例绑定了一个实例属性。
-
Python中定义实例方法
一个实例的私有属性就是以__开头的属性,无法被外部访问,那这些属性定义有什么用?
虽然私有属性无法从外部访问,但是,从类的内部是可以访问的。除了可以定义实例的属性外,还可以定义实例的方法。
实例的方法就是在类中定义的函数,它的第一个参数永远是 self,指向调用该方法的实例本身,其他参数和一个普通函数是完全一样的:
class Person(object): def __init__(self, name): self.__name = name def get_name(self): return self.__nameget_name(self) 就是一个实例方法,它的第一个参数是self。__init__(self, name)其实也可看做是一个特殊的实例方法。
调用实例方法必须在实例上调用:
p1 = Person('Bob') print p1.get_name() # self不需要显式传入 # => Bob在实例方法内部,可以访问所有实例属性,这样,如果外部需要访问私有属性,可以通过方法调用获得,这种数据封装的形式除了能保护内部数据一致性外,还可以简化外部调用的难度。
-
Python中方法也是属性
我们在 class 中定义的实例方法其实也是属性,它实际上是一个函数对象:
class Person(object): def __init__(self, name, score): self.name = name self.score = score def get_grade(self): return 'A' p1 = Person('Bob', 90) print p1.get_grade # => <bound method Person.get_grade of <__main__.Person object at 0x109e58510>> print p1.get_grade() # => A也就是说,p1.get_grade 返回的是一个函数对象,但这个函数是一个绑定到实例的函数,p1.get_grade() 才是方法调用。
因为方法也是一个属性,所以,它也可以动态地添加到实例上,只是需要用 types.MethodType() 把一个函数变为一个方法:
import types def fn_get_grade(self): if self.score >= 80: return 'A' if self.score >= 60: return 'B' return 'C' class Person(object): def __init__(self, name, score): self.name = name self.score = score p1 = Person('Bob', 90) p1.get_grade = types.MethodType(fn_get_grade, p1, Person) print p1.get_grade() # => A p2 = Person('Alice', 65) print p2.get_grade() # ERROR: AttributeError: 'Person' object has no attribute 'get_grade' # 因为p2实例并没有绑定get_grade给一个实例动态添加方法并不常见,直接在class中定义要更直观。
-
Python中定义类方法
和属性类似,方法也分实例方法和类方法。
在class中定义的全部是实例方法,实例方法第一个参数 self 是实例本身。
要在class中定义类方法,需要这么写:
class Person(object): count = 0 @classmethod def how_many(cls): return cls.count def __init__(self, name): self.name = name Person.count = Person.count + 1 print Person.how_many() p1 = Person('Bob') print Person.how_many()通过标记一个 @classmethod,该方法将绑定到 Person 类上,而非类的实例。类方法的第一个参数将传入类本身,通常将参数名命名为 cls,上面的 cls.count 实际上相当于 Person.count。
因为是在类上调用,而非实例上调用,因此类方法无法获得任何实例变量,只能获得类的引用。
- 待更新...
六、类的继承
- 简介






-
Python中继承一个类
如果已经定义了Person类,需要定义新的Student和Teacher类时,可以直接从Person类继承:
class Person(object): def __init__(self, name, gender): self.name = name self.gender = gender定义Student类时,只需要把额外的属性加上,例如score:
class Student(Person): def __init__(self, name, gender, score): super(Student, self).__init__(name, gender) self.score = score一定要用 super(Student, self).__init__(name, gender) 去初始化父类,否则,继承自 Person 的 Student 将没有 name 和 gender。
函数super(Student, self)将返回当前类继承的父类,即 Person ,然后调用__init__()方法,注意self参数已在super()中传入,在__init__()中将隐式传递,不需要写出(也不能写)。
-
Python中判断类型
函数isinstance()可以判断一个变量的类型,既可以用在Python内置的数据类型如str、list、dict,也可以用在我们自定义的类,它们本质上都是数据类型。
假设有如下的 Person、Student 和 Teacher 的定义及继承关系如下:
class Person(object): def __init__(self, name, gender): self.name = name self.gender = gender class Student(Person): def __init__(self, name, gender, score): super(Student, self).__init__(name, gender) self.score = score class Teacher(Person): def __init__(self, name, gender, course): super(Teacher, self).__init__(name, gender) self.course = course p = Person('Tim', 'Male') s = Student('Bob', 'Male', 88) t = Teacher('Alice', 'Female', 'English')当我们拿到变量 p、s、t 时,可以使用 isinstance 判断类型:
>>> isinstance(p, Person) True # p是Person类型 >>> isinstance(p, Student) False # p不是Student类型 >>> isinstance(p, Teacher) False # p不是Teacher类型这说明在继承链上,一个父类的实例不能是子类类型,因为子类比父类多了一些属性和方法。
我们再考察 s :
>>> isinstance(s, Person) True # s是Person类型 >>> isinstance(s, Student) True # s是Student类型 >>> isinstance(s, Teacher) False # s不是Teacher类型s 是Student类型,不是Teacher类型,这很容易理解。但是,s 也是Person类型,因为Student继承自Person,虽然它比Person多了一些属性和方法,但是,把 s 看成Person的实例也是可以的。
这说明在一条继承链上,一个实例可以看成它本身的类型,也可以看成它父类的类型。
-
Python中多态
类具有继承关系,并且子类类型可以向上转型看做父类类型,如果我们从 Person 派生出 Student和Teacher ,并都写了一个 whoAmI() 方法:
class Person(object): def __init__(self, name, gender): self.name = name self.gender = gender def whoAmI(self): return 'I am a Person, my name is %s' % self.name class Student(Person): def __init__(self, name, gender, score): super(Student, self).__init__(name, gender) self.score = score def whoAmI(self): return 'I am a Student, my name is %s' % self.name class Teacher(Person): def __init__(self, name, gender, course): super(Teacher, self).__init__(name, gender) self.course = course def whoAmI(self): return 'I am a Teacher, my name is %s' % self.name在一个函数中,如果我们接收一个变量 x,则无论该 x 是 Person、Student还是 Teacher,都可以正确打印出结果:
def who_am_i(x): print x.whoAmI() p = Person('Tim', 'Male') s = Student('Bob', 'Male', 88) t = Teacher('Alice', 'Female', 'English') who_am_i(p) who_am_i(s) who_am_i(t)运行结果:
I am a Person, my name is Tim I am a Student, my name is Bob I am a Teacher, my name is Alice这种行为称为多态。也就是说,方法调用将作用在 x 的实际类型上。s 是Student类型,它实际上拥有自己的 whoAmI()方法以及从 Person继承的 whoAmI方法,但调用 s.whoAmI()总是先查找它自身的定义,如果没有定义,则顺着继承链向上查找,直到在某个父类中找到为止。
由于Python是动态语言,所以,传递给函数 who_am_i(x)的参数 x 不一定是 Person 或 Person 的子类型。任何数据类型的实例都可以,只要它有一个whoAmI()的方法即可:
class Book(object): def whoAmI(self): return 'I am a book'这是动态语言和静态语言(例如Java)最大的差别之一。动态语言调用实例方法,不检查类型,只要方法存在,参数正确,就可以调用。
-
Python中多重继承
除了从一个父类继承外,Python允许从多个父类继承,称为多重继承。
多重继承的继承链就不是一棵树了,它像这样:
class A(object): def __init__(self, a): print 'init A...' self.a = a class B(A): def __init__(self, a): super(B, self).__init__(a) print 'init B...' class C(A): def __init__(self, a): super(C, self).__init__(a) print 'init C...' class D(B, C): def __init__(self, a): super(D, self).__init__(a) print 'init D...'看下图:

像这样,D 同时继承自 B 和 C,也就是 D 拥有了 A、B、C 的全部功能。多重继承通过 super()调用__init__()方法时,A 虽然被继承了两次,但__init__()只调用一次:
>>> d = D('d') init A... init C... init B... init D...多重继承的目的是从两种继承树中分别选择并继承出子类,以便组合功能使用。
举个例子,Python的网络服务器有TCPServer、UDPServer、UnixStreamServer、UnixDatagramServer,而服务器运行模式有 多进程ForkingMixin 和 多线程ThreadingMixin两种。
要创建多进程模式的 TCPServer:
class MyTCPServer(TCPServer, ForkingMixin) pass要创建多线程模式的 UDPServer:
class MyUDPServer(UDPServer, ThreadingMixin): pass如果没有多重继承,要实现上述所有可能的组合需要 4x2=8 个子类。
-
Python中获取对象信息
拿到一个变量,除了用 isinstance() 判断它是否是某种类型的实例外,还有没有别的方法获取到更多的信息呢?
例如,已有定义:
class Person(object): def __init__(self, name, gender): self.name = name self.gender = gender class Student(Person): def __init__(self, name, gender, score): super(Student, self).__init__(name, gender) self.score = score def whoAmI(self): return 'I am a Student, my name is %s' % self.name首先可以用 type() 函数获取变量的类型,它返回一个 Type 对象:
>>> type(123) <type 'int'> >>> s = Student('Bob', 'Male', 88) >>> type(s) <class '__main__.Student'>其次,可以用 dir() 函数获取变量的所有属性:
>>> dir(123) # 整数也有很多属性... ['__abs__', '__add__', '__and__', '__class__', '__cmp__', ...] >>> dir(s) ['__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'gender', 'name', 'score', 'whoAmI']对于实例变量,dir()返回所有实例属性,包括`__class__`这类有特殊意义的属性。注意到方法`whoAmI`也是 s 的一个属性。
如何去掉`__xxx__`这类的特殊属性,只保留我们自己定义的属性?回顾一下filter()函数的用法。
dir()返回的属性是字符串列表,如果已知一个属性名称,要获取或者设置对象的属性,就需要用 getattr() 和 setattr( )函数了:
>>> getattr(s, 'name') # 获取name属性 'Bob' >>> setattr(s, 'name', 'Adam') # 设置新的name属性 >>> s.name 'Adam' >>> getattr(s, 'age') # 获取age属性,但是属性不存在,报错: Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Student' object has no attribute 'age' >>> getattr(s, 'age', 20) # 获取age属性,如果属性不存在,就返回默认值20: 20 - 待更新...
七、定制类
- 简介




-
Python中 __str__和__repr__
如果要把一个类的实例变成 str,就需要实现特殊方法__str__():
class Person(object): def __init__(self, name, gender): self.name = name self.gender = gender def __str__(self): return '(Person: %s, %s)' % (self.name, self.gender)现在,在交互式命令行下用 print 试试:
>>> p = Person('Bob', 'male') >>> print p (Person: Bob, male)但是,如果直接敲变量 p:
>>> p <main.Person object at 0x10c941890>似乎__str__() 不会被调用。
因为 Python 定义了__str__()和__repr__()两种方法,__str__()用于显示给用户,而__repr__()用于显示给开发人员。
有一个偷懒的定义__repr__的方法:
class Person(object): def __init__(self, name, gender): self.name = name self.gender = gender def __str__(self): return '(Person: %s, %s)' % (self.name, self.gender) __repr__ = __str__ -
Python中 __cmp__
对 int、str 等内置数据类型排序时,Python的 sorted() 按照默认的比较函数 cmp 排序,但是,如果对一组 Student 类的实例排序时,就必须提供我们自己的特殊方法 __cmp__():
class Student(object): def __init__(self, name, score): self.name = name self.score = score def __str__(self): return '(%s: %s)' % (self.name, self.score) __repr__ = __str__ def __cmp__(self, s): if self.name < s.name: return -1 elif self.name > s.name: return 1 else: return 0上述 Student 类实现了__cmp__()方法,__cmp__用实例自身self和传入的实例 s 进行比较,如果 self 应该排在前面,就返回 -1,如果 s 应该排在前面,就返回1,如果两者相当,返回 0。
Student类实现了按name进行排序:
>>> L = [Student('Tim', 99), Student('Bob', 88), Student('Alice', 77)] >>> print sorted(L) [(Alice: 77), (Bob: 88), (Tim: 99)]注意: 如果list不仅仅包含 Student 类,则 __cmp__ 可能会报错。
任务
请修改 Student 的 __cmp__ 方法,让它按照分数从高到底排序,分数相同的按名字排序。(如果list中数据类型不一样如何解决?)
class Student(object): def __init__(self, name, score): self.name = name self.score = score def __str__(self): return '(%s: %s)' % (self.name, self.score) __repr__ = __str__ def __cmp__(self, s): if False == isinstance(s, Student): return -1 return -cmp(self.score,s.score) or cmp(self.name,s.name) L = [Student('Tim', 99), Student('Bob', 88), Student('Alice', 99)] print sorted(L) -
Python中 __len__
如果一个类表现得像一个list,要获取有多少个元素,就得用 len() 函数。
要让 len() 函数工作正常,类必须提供一个特殊方法__len__(),它返回元素的个数。
例如,我们写一个 Students 类,把名字传进去:
class Students(object): def __init__(self, *args): self.names = args def __len__(self): return len(self.names)只要正确实现了__len__()方法,就可以用len()函数返回Students实例的“长度”:
>>> ss = Students('Bob', 'Alice', 'Tim') >>> print len(ss) 3 -
Python中数学运算
Python 提供的基本数据类型 int、float 可以做整数和浮点的四则运算以及乘方等运算。
但是,四则运算不局限于int和float,还可以是有理数、矩阵等。
要表示有理数,可以用一个Rational类来表示:
class Rational(object): def __init__(self, p, q): self.p = p self.q = qp、q 都是整数,表示有理数 p/q。
如果要让Rational进行+运算,需要正确实现__add__:
class Rational(object): def __init__(self, p, q): self.p = p self.q = q def __add__(self, r): return Rational(self.p * r.q + self.q * r.p, self.q * r.q) def __str__(self): return '%s/%s' % (self.p, self.q) __repr__ = __str__现在可以试试有理数加法:
>>> r1 = Rational(1, 3) >>> r2 = Rational(1, 2) >>> print r1 + r2 5/6 -
Python中类型转换
Rational类实现了有理数运算,但是,如果要把结果转为 int 或 float 怎么办?
考察整数和浮点数的转换:
>>> int(12.34) 12 >>> float(12) 12.0如果要把 Rational 转为 int,应该使用:
r = Rational(12, 5) n = int(r)要让int()函数正常工作,只需要实现特殊方法__int__():
class Rational(object): def __init__(self, p, q): self.p = p self.q = q def __int__(self): return self.p // self.q结果如下:
>>> print int(Rational(7, 2)) 3 >>> print int(Rational(1, 3)) 0同理,要让float()函数正常工作,只需要实现特殊方法__float__()。
-
Python中 @property
考察 Student 类:
class Student(object): def __init__(self, name, score): self.name = name self.score = score当我们想要修改一个 Student 的 scroe 属性时,可以这么写:
s = Student('Bob', 59) s.score = 60但是也可以这么写:
s.score = 1000显然,直接给属性赋值无法检查分数的有效性。
如果利用两个方法:
class Student(object): def __init__(self, name, score): self.name = name self.__score = score def get_score(self): return self.__score def set_score(self, score): if score < 0 or score > 100: raise ValueError('invalid score') self.__score = score这样一来,s.set_score(1000) 就会报错。
这种使用 get/set 方法来封装对一个属性的访问在许多面向对象编程的语言中都很常见。
但是写 s.get_score() 和 s.set_score() 没有直接写 s.score 来得直接。
有没有两全其美的方法?----有。
因为Python支持高阶函数,在函数式编程中我们介绍了装饰器函数,可以用装饰器函数把 get/set 方法“装饰”成属性调用:
class Student(object): def __init__(self, name, score): self.name = name self.__score = score @property def score(self): return self.__score @score.setter def score(self, score): if score < 0 or score > 100: raise ValueError('invalid score') self.__score = score注意: 第一个score(self)是get方法,用@property装饰,第二个score(self, score)是set方法,用@score.setter装饰,@score.setter是前一个@property装饰后的副产品。
现在,就可以像使用属性一样设置score了:
>>> s = Student('Bob', 59) >>> s.score = 60 >>> print s.score 60 >>> s.score = 1000 Traceback (most recent call last): ... ValueError: invalid score说明对 score 赋值实际调用的是 set方法。
-
Python中 __slots__
由于Python是动态语言,任何实例在运行期都可以动态地添加属性。
如果要限制添加的属性,例如,Student类只允许添加 name、gender和score 这3个属性,就可以利用Python的一个特殊的__slots__来实现。
顾名思义,__slots__是指一个类允许的属性列表:
class Student(object): __slots__ = ('name', 'gender', 'score') def __init__(self, name, gender, score): self.name = name self.gender = gender self.score = score现在,对实例进行操作:
>>> s = Student('Bob', 'male', 59) >>> s.name = 'Tim' # OK >>> s.score = 99 # OK >>> s.grade = 'A' Traceback (most recent call last): ... AttributeError: 'Student' object has no attribute 'grade'__slots__的目的是限制当前类所能拥有的属性,如果不需要添加任意动态的属性,使用__slots__也能节省内存。
-
python中 __call__
在Python中,函数其实是一个对象:
>>> f = abs >>> f.__name__ 'abs' >>> f(-123) 123由于 f 可以被调用,所以,f 被称为可调用对象。
所有的函数都是可调用对象。
一个类实例也可以变成一个可调用对象,只需要实现一个特殊方法__call__()。
我们把 Person 类变成一个可调用对象:
class Person(object): def __init__(self, name, gender): self.name = name self.gender = gender def __call__(self, friend): print 'My name is %s...' % self.name print 'My friend is %s...' % friend现在可以对 Person 实例直接调用:
>>> p = Person('Bob', 'male') >>> p('Tim') My name is Bob... My friend is Tim...单看 p('Tim') 你无法确定 p 是一个函数还是一个类实例,所以,在Python中,函数也是对象,对象和函数的区别并不显著。
- 待更新...