学习聚合函数的准备工作
新建一个项目,在新建一个app,名字随意,然后在app中的models中定义几个模型:
from django.db import models
# Create your models here.
class Author(models.Model):
"""作者模型"""
name = models.CharField(max_length=100)
age = models.IntegerField()
email = models.EmailField()
class Meta:
db_table = 'author'
class Publisher(models.Model):
"""出版社模型"""
name = models.CharField(max_length=300)
class Meta:
db_table = 'publisher'
class Book(models.Model):
"""图书模型"""
name = models.CharField(max_length=300)
pages = models.IntegerField()
price = models.FloatField() #书的定价
rating = models.FloatField()
author = models.ForeignKey(Author, on_delete=models.CASCADE)
publisher = models.ForeignKey(Publisher, on_delete=models.CASCADE)
class Meta:
db_table = 'book'
class BookOrder(models.Model):
"""图书订单模型"""
book = models.ForeignKey("Book", on_delete=models.CASCADE)
price = models.FloatField() #书卖出去的真正价格
class Meta:
db_table = 'book_order'
然后将模型映射至数据库中,即先makegrations后在migrate。然后手动向表中添加信息。
我添加的信息为
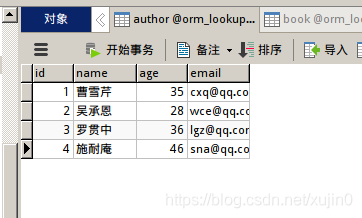
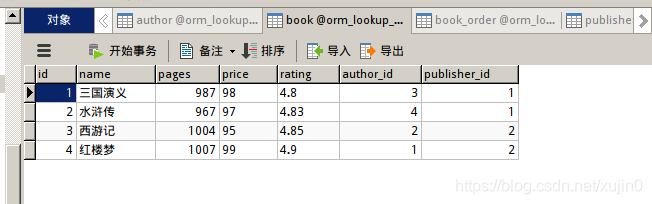
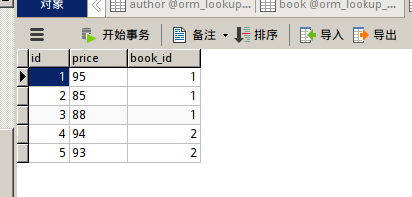
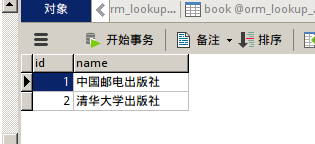
然后配置urls,直至项目运行不报错。
1.Avg:
求平均值。比如想要获取所有图书的价格平均值。那么可以使用以下代码实现。在app中的views中的index中写入代码
from django.shortcuts import render
from django.http import HttpResponse
from . import models
from django.db.models import Avg
# Create your views here.
def index(request):
# 获取所有图书的定价的平均价格
result = models.Book.objects.aggregate(Avg('price'))
# 打印返回的结果
print(result)
# 打印原生的sql语句
print(result.query)
return HttpResponse('success')
注意:
- 在使用Avg方法时需要导入。
- aggregate方法返回的是一个字典。
- Avg()里面填写需要获取平均值的属性。
然后与运行项目,访问网址,我们发现报错了
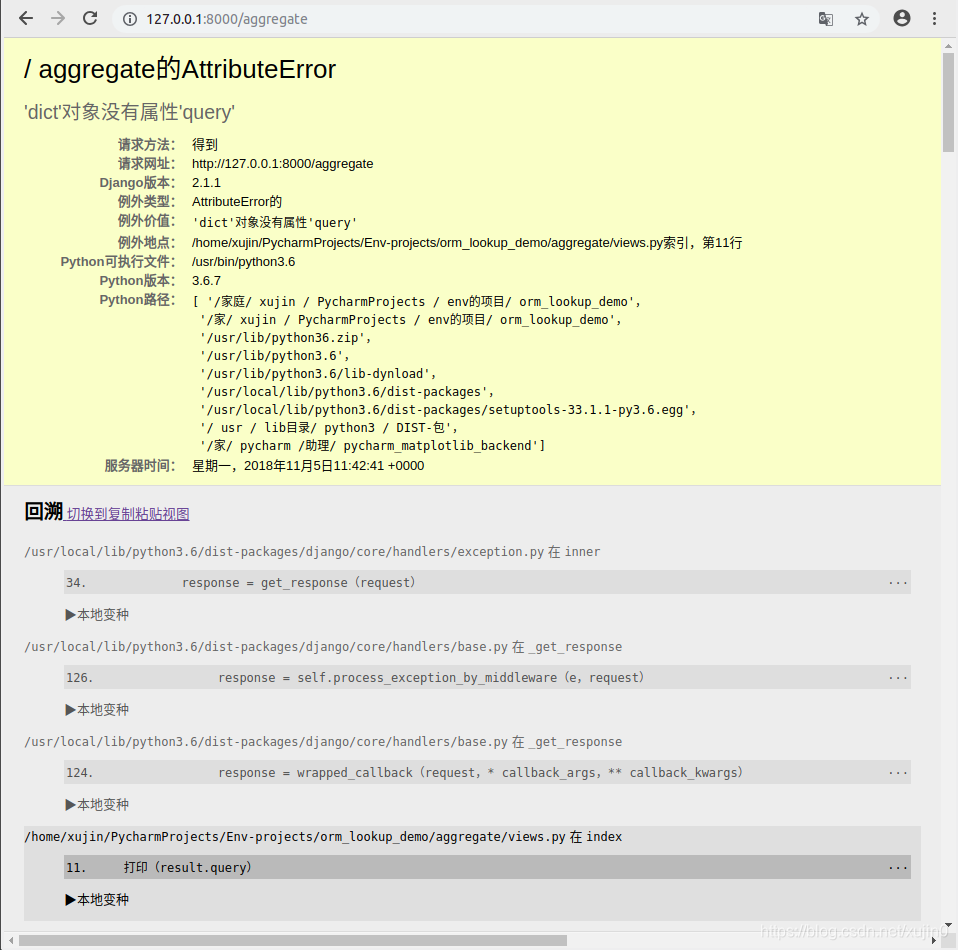
只是因为字典没有query这个属性,只有QuerySet这个对象才拥有这个属性,才能使用这个属性来查看sql原生语句。
这里我们就得换一种方法来查看sql的原生语句了,
修改views中的代码
from django.shortcuts import render
from django.http import HttpResponse
from . import models
from django.db.models import Avg
from django.db import connection
# Create your views here.
def index(request):
# 获取所有图书的定价的平均价格
result = models.Book.objects.aggregate(Avg('price'))
# 打印返回的结果
print(result)
# 打印原生的sql语句,会报错,只有QuerySet对象才有query这个属性
# print(result.query)
# 换一种方法打印sql原生语句
print(connection.queries)
return HttpResponse('success')
然后我们就能够看到返回的平均值和sql原生语句了,返回的sql语句是一个列表。列表里面存放着一个一个的字典,字典里面存放着sql代码和运行时间,这个列表里面最后一个字典中的sql语句就是models.Book.objects.aggregate(Avg('price'))django中对这句代码的翻译。
在这个sql语句里面我们可以看到一个price__avg这个变量。

这个变量就是聚合函数执行完成之后个这个聚合函数的返回值取的一个名字,如果我们不想要这个名字,我们也可以自己取一个名字。
只需要在查询的时候添加一个参数。修改result = models.Book.objects.aggregate(Avg('price'))这句代码为
result = models.Book.objects.aggregate(avg = Avg('price'))
这样我们就自己取了一个avg的名字。
注意:
- 所有的聚合函数都是放在
django.db.models下面。 - 聚合函数不能够单独的执行,需要放在一些可以执行聚合函数的方法下面中去执行。比如
aggregate下面。 - 聚合函数执行完成后,给这个聚合函数的值取个名字。取名字的规则,默认是
filed+__+聚合函数名字形成的。比如上面的price__avg。如果不想使用默认的名字,那么可以在使用聚合函数的时候传递关键字参数进去,参数的名字就是聚合函数执行完成的名字。 aggregate:这个方法不会返回一个QuerySet对象,而是返回一个字典。这个字典中的key就是聚合函数的名字,值就是聚合函数执行后的结果。
在继续讲解聚合函数之前我们先了解一下aggregate和annotate的区别:
首先讲一个需求,现在我需要获取到每一本卖出去书的实际价格的平均值,而我们实际卖出去的书的价格在book_order这个表中,存储了最终卖书出去的价格和对应的书名。
在views中新定义一个函数index1,添加代码
def index1(request):
result = models.Book.objects.aggregate(avg=Avg('bookorder__price'))
print(result)
print(connection.queries)
return HttpResponse('success')
运行项目,我们可以发现返回的结果只有一个数据,这并不是我们想要的结果,因为在orderbook这张表中拥有两本书的价格,我们需要的是有基本书返回几个数据,而这里只给我们返回了一个数据,显然不能满足我们的需求。
这个时候就需要使用到annotate这个方法来代替aggregate了,修改index1中的代码:
def index1(request):
# 从book中访问bookorder中的price
# result = models.Book.objects.aggregate(avg=Avg('bookorder__price'))
# print(result)
# print(connection.queries)
books = models.Book.objects.annotate(avg = Avg('bookorder__price'))
print(books)
for book in books:
print('%s/%s'%(book.name,book.avg))
print(connection.queries)
return HttpResponse('success')
运行项目查看效果。

这样我们就得到我们想要的效果了,将每本书的平均价格都得到了。
注意: 在Book这个模型中,我们没有avg这个属性,那么我们使用的avg这个属性时从什么地方来的呢。这个属性就是在使用聚合函数之后Django自动给我们添加的,我们可以通过这个属性在获取聚合函数返回的值。

aggregate和annotate的相同和不同:
- 相同:这两个方法都可以执行聚合函数。
- 不同:
1.aggregate返回的是一个字典,在这个字典中存储的是这个聚合函数执行的结果。而annotate返回的是一个QuerySet对象,并且会在查找的模型上添加一个聚合函数的属性。
2.aggregate不会做分组,而annotate会使用group by子句进行分组,只有调用了group by子句,就是对id为同一个的进行分组。才能对每一条数据求聚合函数的值。
count:
用来求某个数据的个数。比如要求所有图书的数量,那么可以使用以下代码:新增加一个index2的函数,写入代码:
def index2(request):
# book表中总共有多少本书(book中有多少id)
result = models.Book.objects.aggregate(book_nums = Count('id'))
print(result)
print(connection.queries)
return HttpResponse('success')
这样,我们就获取了book中总共有多少本书。
接下来我们还有一个需求,那就是获取卖出去的书的种类的个数。因为卖出去的竖肯定是由重复的,即一本书卖出去了多本。而我们重要卖出去的不相同的书的个数。修改index2的代码
def index2(request):
# book表中总共有多少本书(book中有多少id)
# result = models.Book.objects.aggregate(book_nums = Count('id'))
# print(result)
# print(connection.queries)
# 获取卖出去的不同的书的书名个数。
result = models.BookOrder.objects.aggregate(book_nums = Count('book_id',distinct=True))
print(result)
print(connection.queries)
return HttpResponse('success')
可以看到我们只是在Count中添加了distinct=True,就实现了我们的需求。distinct=True用来剔除那些重复的值,只保留一个。可以把distinct=True去掉之后来查看一下效果,看一下结果会一样吗。
接下来我焖需要获取每本书的销量:修改index2的代码
def index2(request):
# book表中总共有多少本书(book中有多少id)
# result = models.Book.objects.aggregate(book_nums = Count('id'))
# print(result)
# print(connection.queries)
# 获取卖出去的不同的书的书名个数。
# result = models.BookOrder.objects.aggregate(book_nums = Count('book_id',distinct=True))
# print(result)
# print(connection.queries)
# # 统计每本书的销量
books = models.Book.objects.annotate(book_nums = Count('bookorder__id'))
for book in books:
print("%s/%s"%(book.name,book.book_nums))
print(books)
print(connection.queries)
return HttpResponse('success')
这样, 我们就能获取每本书的销量了。
Max 和 Min:
求指定字段的最大值和最小值。
需求:获取author中年龄最大的和最小的
新建一个函数index3,写入代码:
def index3(request):
# 获取author中年龄最大的和最小的
result = models.Author.objects.aggregate(max=Max('age'),min=Min('age'))
print(result)
print(connection.queries)
return HttpResponse('success')
这样就实现了我们的需求,接下来我们继续实现另外的需求
获取每一本图书售卖的时候的最大价格和最小价格
修改index3的代码:
def index3(request):
# 获取author中年龄最大的和最小的
# result = models.Author.objects.aggregate(max=Max('age'),min=Min('age'))
# print(result)
# print(connection.queries)
books = models.Book.objects.annotate(max=Max('bookorder__price'),min=Min('bookorder__price'))
print(books)
for book in books:
print('%s的最高价格:%s 最低价格:%s'%(book.name,book.max,book.min))
return HttpResponse('success')
怎样就实现了我们的需求
Sum:
求某个字段值的总和。
需求一:求所有图书的销售总额
新添加一个函数index4:添加代码
def index4(request):
# 求所有图书的销售总额
result = models.BookOrder.objects.aggregate(total=Sum('price'))
print(result)
return HttpResponse('success')
需求二:求每种图书的销售总额
修改index4 的代码:
def index4(request):
# 求所有图书的销售总额
# result = models.BookOrder.objects.aggregate(total=Sum('price'))
# print(result)
# 求每种图书的销售总额
results = models.Book.objects.annotate(total=Sum('bookorder__price'))
print(results)
for result in results:
print('%s的销售总额为:%s'%(result.name,result.total))
return HttpResponse('success')
注意: aggregate和annotate方法可以在任何的QuerySet对象上调用。因此只要是返回了QuerySet对象,那么就可以进行链式调用。例如在使用filter后在面再使用aggregate和annotate。
更多的聚合函数请参考官方文档:https://docs.djangoproject.com/en/2.1/ref/models/querysets/#aggregation-functions
F表达式:
F表达式是用来优化ORM操作数据库的。比如我们要将所有图书的定价都增加100元,如果按照正常的流程,应该是先从数据库中提取所有的图书定价到Python内存中,然后使用Python代码在图书定价的基础之上增加100元,最后再保存到数据库中。这里面涉及的流程就是,首先从数据库中提取数据到Python内存中,然后在Python内存中做完运算,之后再保存到数据库中。
示例:
新建一个index5:编写代码
def index5(request):
# 给每一本图书定价增加100元
models.Book.objects.update(price=F('price')+100)
print(connection.queries)
return HttpResponse('success')
这样,我们使用一行代码就实现 了这个需求,而不用先取到python内存中在进行操作了。
需求2:
获取author中name和email相同的一条数据:
为了展示效果,首先我们先去数据库中修改一个name使其值和对应的email的值相同。
然后修改index5中的代码:
from django.db.models import Avg,Count,Max,Min,Sum,F
def index5(request):
# 给每一本图书定价增加100元
# models.Book.objects.update(price=F('price')+100)
# print(connection.queries)
# 获取author的name和email值一样的一条数据
authors = models.Author.objects.filter(name=F('email'))
for author in authors:
print('%s的email和name值一样,'%author.name)
print(connection.queries)
return HttpResponse('success')
Q表达式:
使用Q表达式包裹查询条件,可以在条件之间进行多种操作。与/或非等,从而实现一些复杂的查询操作。
需求一:获取书籍中pages大于1000的,并且评分大于等于4.9的书籍。
新建一个index6的函数:编写代码:
不使用Q表达式:
def index6(request):
# 获取书籍中pages大于1000的,并且评分大于等于4.9的书籍。
# 不使用Q表达式
books = models.Book.objects.filter(pages__gte=1000,rating__gte=4.9)
for book in books:
print('%s-%s-%s'%(book.name,book.pages,book.rating))
print(connection.queries)
return HttpResponse('success')
使用Q表达式
def index6(request):
# 获取书籍中pages大于1000的,并且评分大于等于4.9的书籍。
# 不使用Q表达式
# books = models.Book.objects.filter(pages__gte=1000,rating__gte=4.9)
# for book in books:
# print('%s-%s-%s'%(book.name,book.pages,book.rating))
# print(connection.queries)
# 使用Q表达式
books = models.Book.objects.filter(Q(pages__gte=1000)&Q(rating__gte=4.9))
for book in books:
print('%s-%s-%s'%(book.name,book.pages,book.rating))
print(connection.queries)
return HttpResponse('success')
我们可以看到使不使用Q表达式差别并不大,只是因为filter默认就是传递的多个条件就是与(&)操作,如果我们想实现或或非等操作,那么不使用Q表达式操作将很繁琐。
需求二:获取书籍中pages小于900的,或者评分大于等于4.85的书籍。
修改index6中的代码:
def index6(request):
# 获取书籍中pages大于1000的,并且评分大于等于4.9的书籍。
# 不使用Q表达式
# books = models.Book.objects.filter(pages__gte=1000,rating__gte=4.9)
# for book in books:
# print('%s-%s-%s'%(book.name,book.pages,book.rating))
# print(connection.queries)
# 使用Q表达式
# books = models.Book.objects.filter(Q(pages__gte=1000)&Q(rating__gte=4.9))
# for book in books:
# print('%s-%s-%s'%(book.name,book.pages,book.rating))
# print(connection.queries)
# 获取书籍中pages小于900的,或者评分大于等于4.85的书籍。
books = models.Book.objects.filter(Q(pages__lt=900) | Q(rating__gte=4.85))
for book in books:
print('%s-%s-%s'%(book.name,book.pages,book.rating))
print(connection.queries)
return HttpResponse('success')
需求三:获取书籍中pages大于1000的,并且书名中不能包含有记的图书
修改index6中的代码;
def index6(request):
# 获取书籍中pages大于1000的,并且评分大于等于4.9的书籍。
# 不使用Q表达式
# books = models.Book.objects.filter(pages__gte=1000,rating__gte=4.9)
# for book in books:
# print('%s-%s-%s'%(book.name,book.pages,book.rating))
# print(connection.queries)
# 使用Q表达式
# books = models.Book.objects.filter(Q(pages__gte=1000)&Q(rating__gte=4.9))
# for book in books:
# print('%s-%s-%s'%(book.name,book.pages,book.rating))
# print(connection.queries)
# 获取书籍中pages小于900的,或者评分大于等于4.85的书籍。
# books = models.Book.objects.filter(Q(pages__lt=900) | Q(rating__gte=4.85))
# for book in books:
# print('%s-%s-%s'%(book.name,book.pages,book.rating))
# print(connection.queries)
# 获取书籍中pages大于1000的,并且书名中不能包含有`记`的图书
books = models.Book.objects.filter(Q(pages__gte=1000) & ~Q(name__icontains='记'))
for book in books:
print('%s-%s-%s'%(book.name,book.pages,book.rating))
print(connection.queries)
return HttpResponse('success')