一、引言
停滞了很久,最近又开始细细品味起《Data Structure And Algorithm Analysis In C++》这本书了。这本书的第一章即为非常好的 C++11 统领介绍的教材范文,可能对于 C++11 新手来说,作者这样短篇幅的介绍或许有些苍白晦涩,但是对于我这种有一定 C++ 开发经验并且有研读过 《C++ Primer 5th》的人来说,作者这几页简直就是让我对 C++11 的整体脉络有了更加宏观的认识。
话不多说,在之前,我看了这本书的第 1.5.3 节后,总结了一篇博客:
细谈 C++ 传参的四种方式:按值传参、按左值引用传参、按常量引用传参以及按右值引用传参
可以说,我这篇博客里面那种画出来的图(什么时候选择使用哪种传参方式)就是非常精炼的总结。
C++ 除了四种传参方式,其实还有三种返回传值的方式。C++ 的代码为什么这么难以理解,从入参到出参,这都是有一些门门道道的。
同样的,这里,我拿出这本书的第 37 页的一块函数模板的代码,你能解释出来为什么这个 findMax 函数要使用按常量引用的方式返回传值吗:
/**
* Return the maximum item in array a.
* Assumes a.size() > 0.
* Comparable objects must provide operator< and operator=
*/
template <typename Comparable>
const Comparable & findMax(const vector<Comparable> & a)
{
int maxIndex = 0;
for(int i = 0; i < a.size(); ++i)
if (a[maxIndex] < a[i])
maxIndex = i;
return a[maxIndex];
}
这里以这段代码开篇引言,后面会仔细介绍 C++ 的三种返回传值的方式,以及总结一下什么时候,我们该选择使用哪种返回传值的方式。
ps: 本篇博客大量参考了《Data Structure And Algorithm Analysis In C++》书中的解释和代码。
二、一点碎碎念的讨论
让我们忘掉那么多复杂的概念,我们一起来仔细思考一下,C++ 返回传值的表现:被传递的值是否持续存在、传递过程中是否发生了拷贝、传递过程中是否会自动转化成移动语义(C++11 新增)等等。这些表现到底与哪些因素有关呢?
通过仔细研读《Data Structure And Algorithm Analysis In C++》书中的阐述,我认为 C++ 返回传值的表现的不同,主要与两方面有关系:
1. 被返回的值
函数体内,被返回的值,它是左值还是右值,是临时变量(函数体内定义的)还是非临时变量(函数体外定义的),都会影响到返回传值的表现。
这里,我简单举个例子:
LargeType randomItem1 (const vector<LargeType> & arr)
{
return arr[randomInt(0, arr.size() - 1)];
}
vector<LargeType> vec;
// copy
LargeType item1 = randomItem1(vec);
这里,vec 以按常量引用的方式传入 randomItem1 函数,它是一个非临时变量,并且是一个左值返回。那么这次返回传值的表现是什么呢,那就是在返回后,arr 数组实际上持续存在,并且因为 arr 实际上是一个函数外定义的变量,因此在函数内部传值返回的时候,不可以使用 C++11 新增的自动右值转化变成移动语义以避免复制拷贝开销。
这是什么意思呢,我们再来看一段代码就好了:
vector<int> partialSum(const vector<int> & arr)
{
vector<int> result(arr.size());
result[0] = arr[0];
for (int i = 1; i < arr.size(); ++i)
result[i] = result[i - 1] + arr[i];
return result;
}
vector<int> vec;
// copy in old C++, move in C++11
vector<int> sums = parialSum(vec);
这段代码乍一看,仿佛并没有什么不同,也是普通返回类型,也是按常量引用传值。可是这个调用的返回传值的表现就大大不同了,传统 C++ 确实还是会按值返回,发生拷贝,但是 C++11 中就会自动转化为移动语义,使用移动替换拷贝节省开销。
为什么呢?这就是因为返回的 result 实际上是一个临时变量,同右值在这里有异曲同工之妙的地方在于,他们在离开了函数之后都会自动的消失,也就是说,我们将其值移动到返回接受这个值的地方完全没有问题,并且还能节省资源开销,何乐而不为呢?而 C++11 确实也是这么做的。
总而言之,返回传值的表现,与被返回的值有关系。其是临时变量或者右值,就有拷贝转移动的可能(返回类型要是普通类型),其是非临时变量,则有返回后持续存在的特性。
2. 返回类型
函数定义的返回类型会影响返回传值的表现,这个也不难理解。
一般来说,返回类型如果定义为:
-
按值返回,则要产生拷贝;
-
按常量引用返回,则如果调用方使用常量引用接受返回值则不产生拷贝;
-
按引用返回,则既不产生拷贝,并且还能对其值进行修改(这种情况虽然少见,但是也有存在)。
这里,我在介绍 C++ 的三种返回传值之前先进行了一些讨论,希望能够对这三种返回传值类型有一些初步的了解。
接下来,我们来结合着例子来详细的探讨下这三种返回传值的方式。
三、这个标题才是正餐
有了前面的一些准备知识,我们来细细的探讨下 C++ 返回传值的三种方式。
1. 按值返回
按值返回,可能是初学者最熟悉的返回方式了。
LargeType randomItem1 (const vector<LargeType> & arr)
{
return arr[randomInt(0, arr.size() - 1)];
}
vector<LargeType> vec;
LargeType item1 = randomItem1 (vec);
我拿出来了同样的例子,我们声明了 randomItem1 的返回类型为 largeType,并未加上 & 或者 const 这就是简单的按值返回。我们将 vec 这个 vector 数组按常量引用传入 randomItem1 函数中去,目的是让 vec 在函数内不至于被改变,并且还能避免传参拷贝带来的资源消耗。
在带出参数的时候,我们发现,带出来的 arr[randomInt(), arr.size() - 1] 其实上是一个非临时变量的左值,在返回传值的时候,需要拷贝给接受该值的 item1 变量。
说的很复杂,其实很简单,那就是这里发生了拷贝开销。
前面也有提到过,在 C++11 一些情况下,拷贝可能会被自动转化为移动。那么这里可以吗?
答案是不行的。
能被转化为移动语义的,一般都带有临时的语义,要么是被返回的值是临时变量,要么就是一个临时的右值,否则不能转化为移动语义。
总的来说,那就是按值返回一般带有拷贝的意味,只是 C++11 会进行一些优化,会将临时的值的返回自动转化为移动来节省拷贝开销。
2. 按常量引用返回
既然按值返回会出现拷贝的开销,那么为了解决这个问题,加上一个引用不就好了吗。因此,按(常量)引用返回的方式就应运而生。
顾名思义,常量,意味着不能对返回值进行修改,引用,则意味着避免拷贝开销。
const LargeType & randomItem2(const vector<LargeType> & arr)
{
return arr[randomInt(0, arr.size() - 1)];
}
vector<LargeType> vec;
// copy
LargeType item1 = randomItem2(vec);
// no copy
const LargeType & item2 = randomItem2(vec);
这里值得注意的是,按常量引用返回的调用,需要同样以常量引用去接受它,否则常量引用向引用类型的转换(const 转非 const)是需要拷贝转换的。
另外,可能你已经注意到了,那么按引用返回传值呢?不就可以对返回值进行修改了吗?
确实是这样,但是这种返回传值的方式比较少见,多见的还是常量引用传值。
3. 按引用返回
按引用返回的使用场景确实比较少,多见于调用者需要对于返回对象的内部的数据进行修改。
template <typename Object>
class martix
{
public:
matrix(vector<vector<Object>> v) : array{v}
{}
const vector<Object> & operator[](int row) const
{ return array[row]; }
vector<Object> & operator[](int row)
{ return array[row]; }
private:
vector<vector<Object>> array;
};
上述代码中,定义了一个二维数组 matrix 类,其元素类型为 Object。同时定义了按常量引用返回的 operator= 操作符和按常量引用返回的 operator= 操作符。这样是为了方便取值的只读语义和修改值的修改语义(accessor or mutator)。
正因为我们这么定义了,所以我们就可以写出下列的代码:
void copy(const matrix<int> & from, matrix<int> & to)
{
for (int i = 0, i < to.numrows(); ++i)
to[i] = from[i];
}
乍一看这个函数的定义非常好,from 是被拷贝的值以按常量引用传入,to 是需要修改的值以引用传入。为了使得这个 to[i] = from[i] 等式编译通过,我们必须定义两个版本的 operator= 操作符。
左侧的 to[i] 就是按引用返回的 operator 操作符,右侧的 from[i] 则是按照常量引用返回的 operator 操作符。
这样达到了语义上的统一。
四、实际开发中如何选择
那么详细探讨了这三种返回传值的方式,我们在开发中该如何选择呢?
这里我还是画了一个图来阐述:
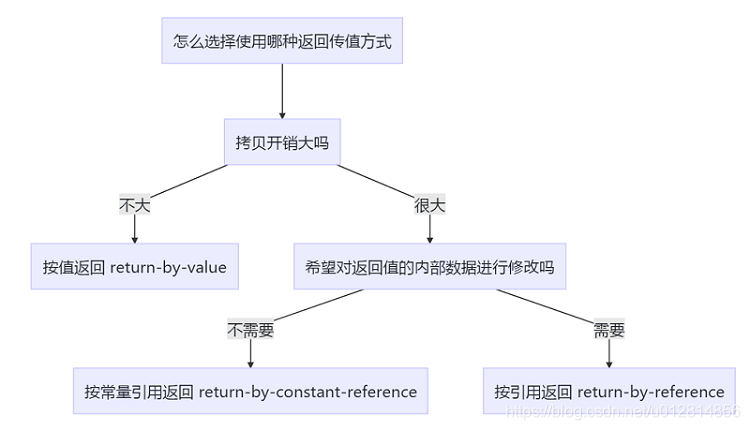
注:或许会有人问,按值返回有没有常量的概念,答案是当然没有。因为按值返回返回的是值的拷贝,你加个常量概念也无法达到对原值的 const 约束。也就是说,按值返回绝对是没有 const 修饰的,因为毫无意义:)
五、总结
C++ 的代码很难看懂,也许就在这些方面,一方面入参的四种方式,一方面出值的三种方式。相互组合,就会让人觉得晦涩难懂。
其实好好深入到里面弄清楚其里面的含义,也就比较好理解了。
这篇和上一篇写传参四种方式的博客写的非常认真,也希望能够对 C++ 初学者能有一些帮助 _
To be Stronger:)