版权声明:Powered by Hibiki Copyright None https://blog.csdn.net/xHibiki/article/details/84076123
PEXELS:Best free stock photos in one place.
Pexels是一个提供免费高品质图片,并且可商用的图片网站.但是因为网站时外国的,所以连接和下载速度都略慢…
这里只是为了讲解图片爬取和下载保存的流程.
三种方式是指:分别指使用Lxml,BeautifulSoup,正则表达式进行爬取
注意:网站的页面是异步加载实现分页,需要实现逆向工程获得对应地址,这里暂时不实现.
观察
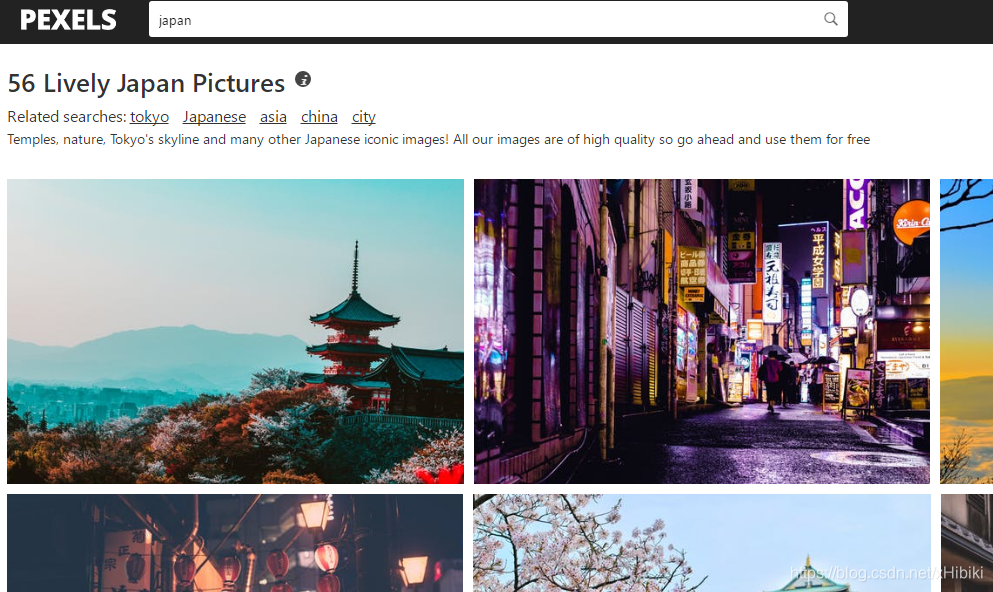
通过搜索关键字japan,得到
网址 https://www.pexels.com/search/japan/ ,爬取该页面上的所有图片
观察图片对应元素
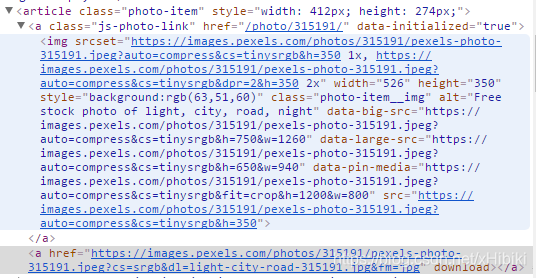
得到图片的下载地址都是包含在
<article class="photo-item ">```
<a><img src='下载地址'></a>
<a>href='下载地址'</a>
</atricle>
所以可以从第一个a中的img中取出下载地址,也能从第二个a的href中取出.
img中还有类似于data-xxx-src后面的链接用于存放更大尺寸的下载地址.
因为构造比较简单,这里使用第二个方式,将a中所有的下载链接存放到links即可
1.Lxml
xml_links = selector.xpath('//article/a[2]/@href')
2.BeautifulSoup
bs4_links = []
soup = BeautifulSoup(res.text, "html.parser")
links = soup.select('article > a')
for link in links:
bs4_links.append(link.get('href'))
3.正则表达式
re_links=re.findall('<a href=\"(.*)\" download>',res.text)
三者对比
1.数据完整性
>>> len(xml_links)
>>> len(bs4_links)
>>> len(re_links)
15
15
15
没问题,都获取了15张图片的下载地址
2.选取元素
Lxml通过xpath语法进入article内的第二个a,获取href
正则表达式通过搜索第二个a中的href直接获取
BeatifulSoup通过selector进入article的a,然后选取href
爬虫代码
import requests
from lxml import etree
import re
import time
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36'
}
url = 'https://www.pexels.com/search/japan/'
if __name__ == '__main__':
res = requests.get(url, headers)
selector = etree.HTML(res.text)
xml_links = selector.xpath('//article/a[2]/@href') # lxml
bs4_links = []
soup = BeautifulSoup(res.text, "html.parser")
links = soup.select('article > a ')
for link in links:
bs4_links.append(link.get('href')) # bs4
re_links = re.findall('<a href=\"(.*)\" download>', res.text) # re
for link in links:
pic = requests.get(link, headers)
pic_name = re.search('(?<=&dl=).*\.jpg', link).group()
with open('d:/1/' + pic_name, 'wb') as pf:
pf.write(pic.content) #以二进制流方式写入文件
print("完成图片下载:" + pic_name)
time.sleep(1) # 缓冲
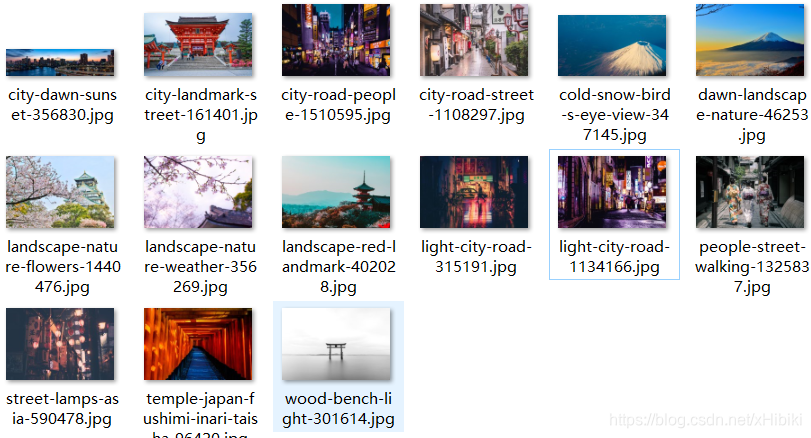
输出结果