人工神经网络 — —百度百科
人工神经网络(Artificial Neural Network,即ANN ),是20世纪80 年代以来人工智能领域兴起的研究热点。它从信息处理角度对人脑神经元网络进行抽象, 建立某种简单模型,按不同的连接方式组成不同的网络。在工程与学术界也常直接简称为神经网络或类神经网络。神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
最近十多年来,人工神经网络的研究工作不断深入,已经取得了很大的进展,其在模式识别、智能机器人、自动控制、预测估计、生物、医学、经济等领域已成功地解决了许多现代计算机难以解决的实际问题,表现出了良好的智能特性。
分类有:

认识神经网络 (参考:http://www.cnblogs.com/subconscious/p/5058741.html)
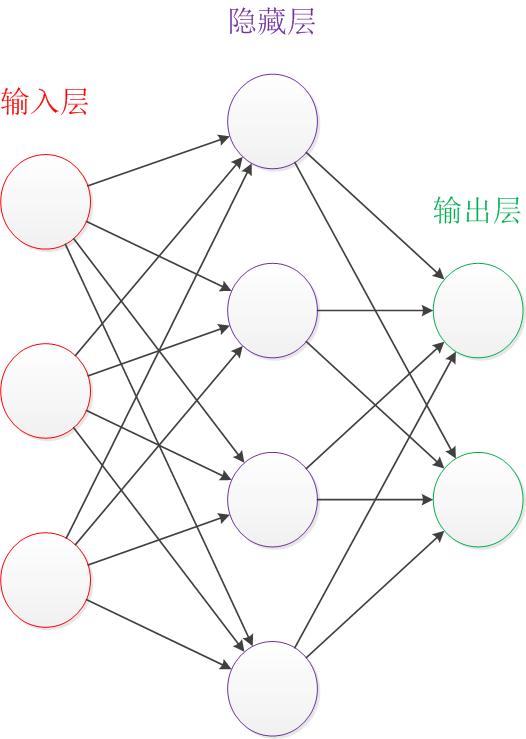
首先,找到一个三个层次的神经网络,分为输入层、隐藏层和输出层。其中,输入层和输出层的节点是固定的,隐藏层是变动的。网络中的拓补和箭头往往代表着预测过程时的数据流向,与训练时有区别。训练得到的东西是边的权值,这是最想得到的数据。
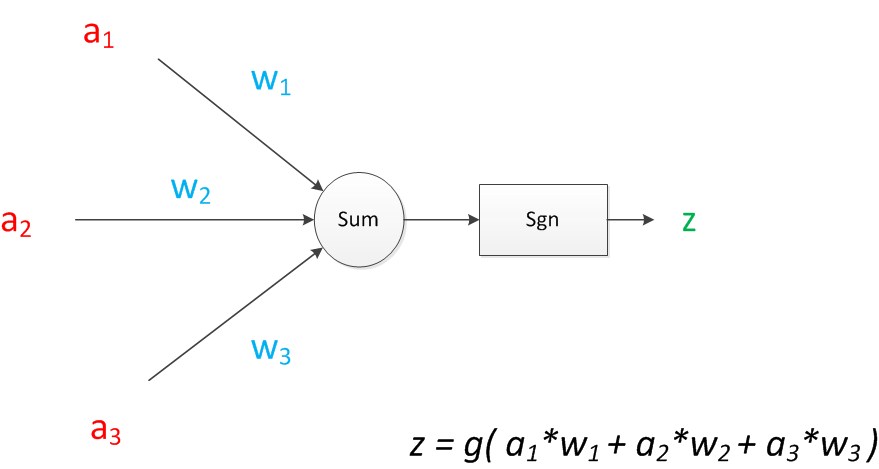
神经元模型:有3个输入,各有一个权值,求和后运行非线性函数,最后进行输出。训练即为将三个权值调整到最佳以使得网络的预测效果最好。当输入后,设为input1,input2,input3,权值为w1、w2、w3,经过边的传递后(边的传递本身就代表值的加权传递)进行加权分别为input1*w1,input2*w2,input3*w3。
神经元扩展模型

单层神经网络(感知器)
单层神经网络就是拥有一个计算层(需要计算的层次)的网络
模型为:
如果是一个向量输出模型,可为:
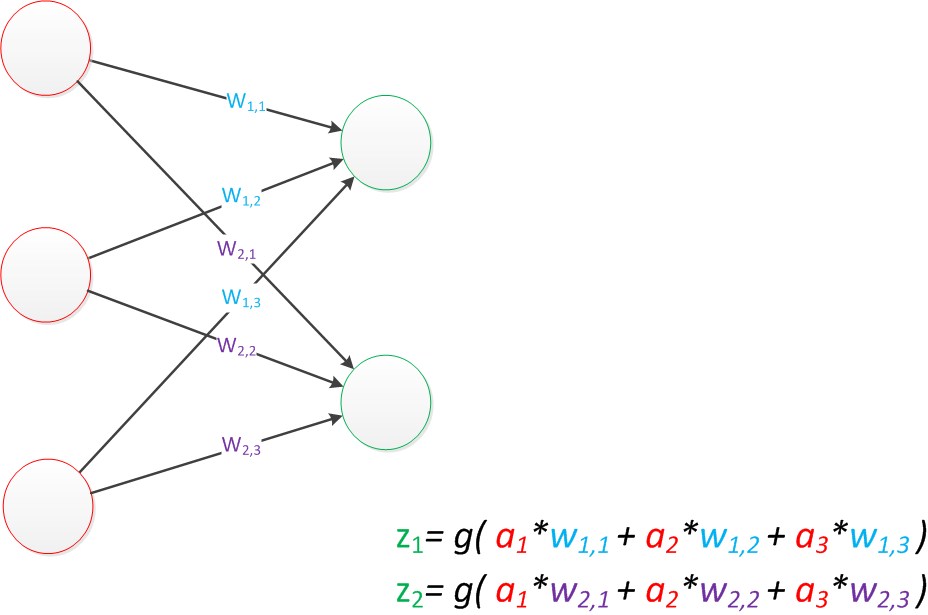
由此可得输出矩阵改写:g(W*a)=z,即为神经网络从前一层到后一层计算的结果。
单层神经网络只能做简单的线性分类任务。
两层神经网络(多层感知器)
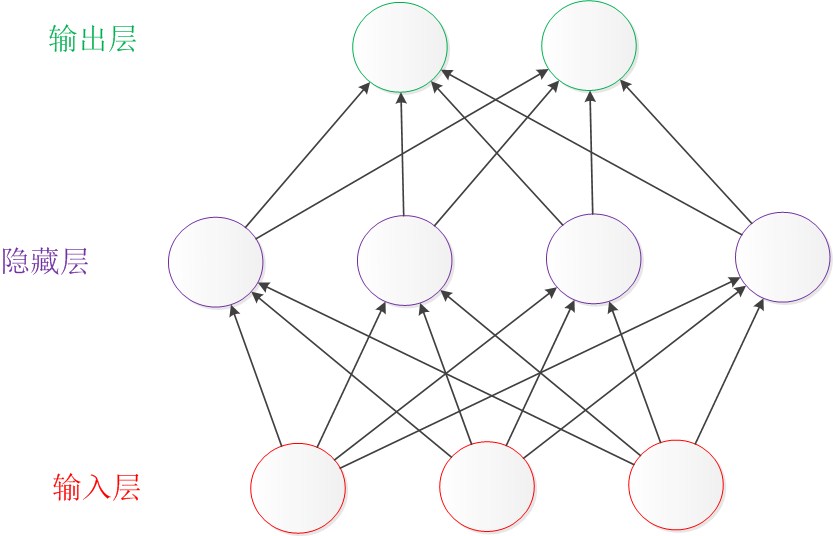
两层神经网络:输入层和输出层之间,增加了中间层,且中间层和输出层都是计算层。如下:

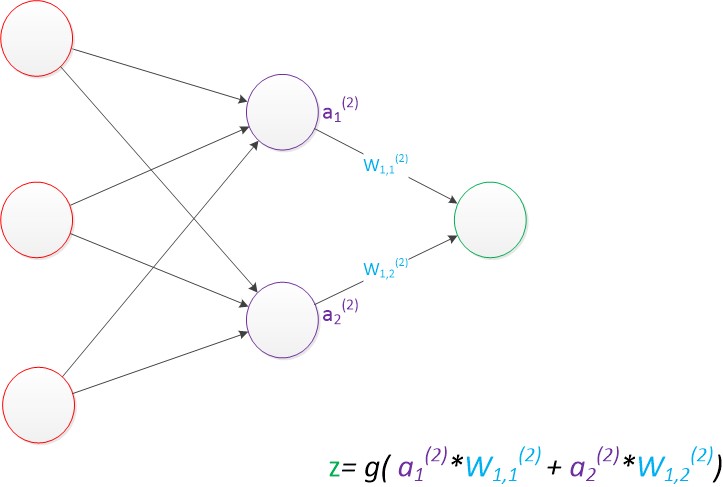
拓展:

使用矩阵表示:
g(W(1) * a(1)) = a(2);
g(W(2) * a(2)) = z;
偏置节点:只含有存储功能,且存储值永远为1的单元,与后一层的所有节点都有连接,叫做偏置。
运算变为:
g(W(1) * a(1) + b(1)) = a(2);
g(W(2) * a(2) + b(2)) = z;
多层神经网络(深度学习)之普通多层神经网络

g(W(1) * a(1)) = a(2);
g(W(2) * a(2)) = a(3);
g(W(3) * a(3)) = z;
增加层次可以实现更深入的表示特征和更强的函数模拟能力。更深入的表示特征可以这样理解,随着网络的层数增加,每一层对于前一层次的抽象表示更深入。在神经网络中,每一层神经元学习到的是前一层神经元值的更抽象的表示。例如第一个隐藏层学习到的是“边缘”的特征,第二个隐藏层学习到的是由“边缘”组成的“形状”的特征,第三个隐藏层学习到的是由“形状”组成的“图案”的特征,最后的隐藏层学习到的是由“图案”组成的“目标”的特征。通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。
在单层神经网络时,我们使用的激活函数是sgn函数。到了两层神经网络时,我们使用的最多的是sigmoid函数。而到了多层神经网络时,通过一系列的研究发现,ReLU函数在训练多层神经网络时,更容易收敛,并且预测性能更好。因此,目前在深度学习中,最流行的非线性函数是ReLU函数。ReLU函数不是传统的非线性函数,而是分段线性函数。其表达式非常简单,就是y=max(x,0)。简而言之,在x大于0,输出就是输入,而在x小于0时,输出就保持为0。这种函数的设计启发来自于生物神经元对于激励的线性响应,以及当低于某个阈值后就不再响应的模拟。
在多层神经网络中,训练的主题仍然是优化和泛化。当使用足够强的计算芯片(例如GPU图形加速卡)时,梯度下降算法以及反向传播算法在多层神经网络中的训练中仍然工作的很好。目前学术界主要的研究既在于开发新的算法,也在于对这两个算法进行不断的优化,例如,增加了一种带动量因子(momentum)的梯度下降算法。
在深度学习中,泛化技术变的比以往更加的重要。这主要是因为神经网络的层数增加了,参数也增加了,表示能力大幅度增强,很容易出现过拟合现象。因此正则化技术就显得十分重要。目前,Dropout技术,以及数据扩容(Data-Augmentation)技术是目前使用的最多的正则化技术。