最近在看Re-ID相关的东西,现在把这篇paper记录一下。代码地址
一、概述
首先二元体掩码可以在两个方面为Re-ID做出贡献。1、掩模可以帮助消除像素级的背景杂波,这可以极大地提高ReID模型在各种背景条件下的鲁棒性。2、面具包含可被视为重要步态特征的体形信息。
如果直接掩盖掉图像中的背景,会使得性能变差,具体的实验结果可以在作者文章4.3节见到,如下:

二、网络结构:
为了解决这个问题,作者利用二元掩码来减少特征级别中的背景中的噪声,并提出了一种对比注意模型(MGCAM)来从身体和背景区域对比学习特征。如下图:
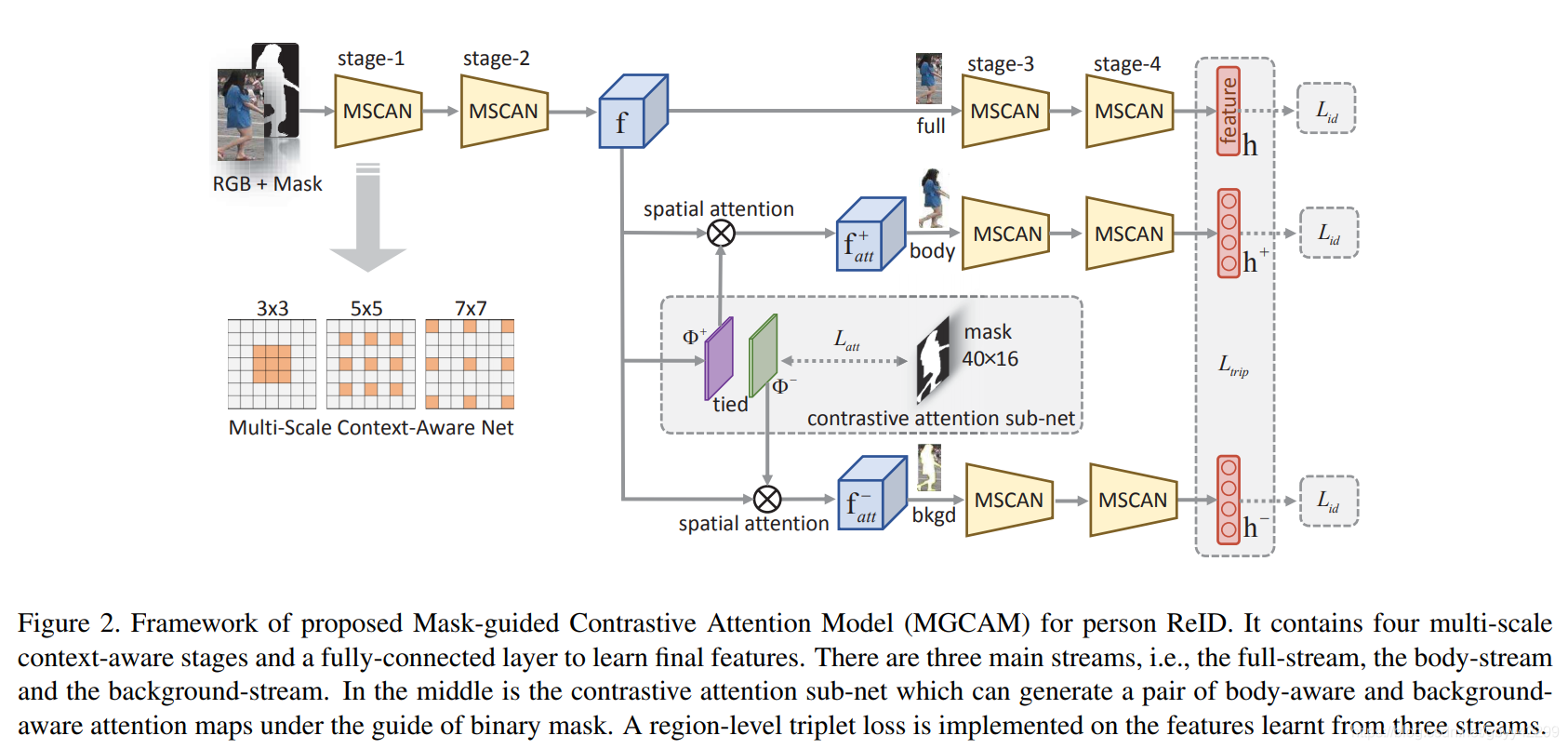
在特征空间中,从body区域和完整图像学习的特征应该是相似的,而从背景和完整图像学习的特征应该是不同的。为此,提出的MGCAM首先在二元体掩模的指导下产生一对对比注意力图。然后将对比注意力图添加到CNN特征中以分别生成身体感知和背景感知特征。
There are two main components, the contrastive attention
sub-net and the region-level triplet loss for contrastive
feature learning. The first part can generate a pair of inverse
attention masks which are used to the body-aware
and background-aware feature learning. Whereas the second
part restrains the distances between features from the
full-stream, the body-stream and the background-stream.
对于三个stream,full stream学习整个image的feature;body stream学习body-attention map;background stream学习background-attention map。虽然这三个stream都是学习的同一张图,但是他们是有些差别的,对于background-stream从background 学习到的特征对于Re-ID这个任务来说是完全没有用的,并且应该提出背景对于前景的影响,所以作者使用triplet loss,正样本是body feature而负样本是bkgd loss。作者希望通过这个函数,使得body feature提供大部分信息,并且同时希望减少背景对于最终结果的影响。
三、Loss
3.1 Mask-guided Contrastive Attention Sub-net

已知这前景和背景的attention map两个操作是互补的,所以肯定会存在这样一个条件:对于feature map上每一个点(i,j):
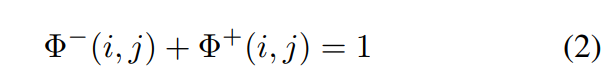
之后的body feature以及bkgd feature的获得则是利用
与这两个值进行内积操作:
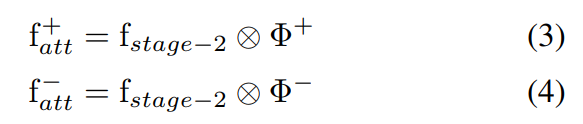
3.2 Region-Level Triplet Loss for Contrastive Feature
Learning
作者通过一个损失函数来生成独立的body feature以及background feature。损失函数如下所示:
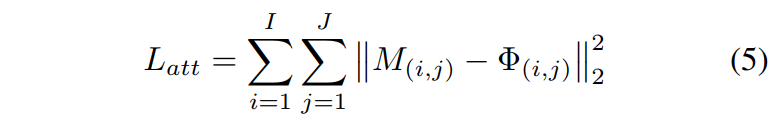
作者使用了triplet loss。这个目标样本自然就是full feature,正样本是body feature而负样本是bkgd loss。这个很容易理解,希望通过这个函数,使得body feature提供大部分信息,并且同时希望减少背景对于最终结果的影响。
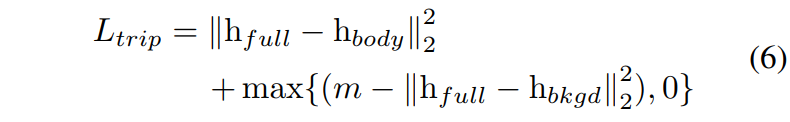
Note:其中m为超参数,根据经验设置为10
3.3 Objective Function
前面提到了这么多都是为了Re-ID这个目标服务,总体的框架为:
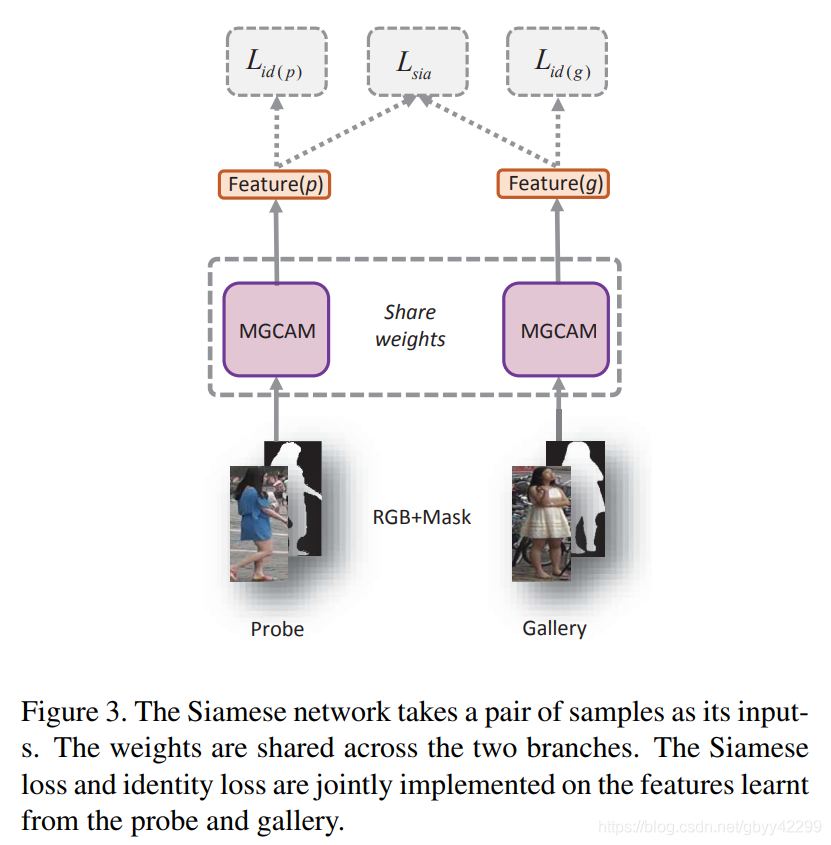
这个网络框架类似于孪生网络,对于两个待对比的人,我们经过MGCAM网络提取到最后的特征分别为h§和h(g),最后通过如下函数对比其相似度:
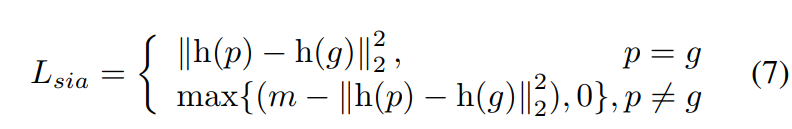
Note:m同上,为经验值10
整个函数训练过程中使用的目标函数式表达为:
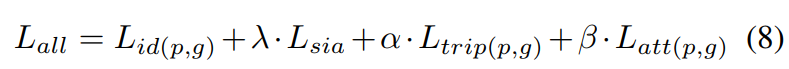
Note:where λ, α and β are the hypermeters, which are respectively
set to 0.01, 0.01 and 0.1 in our experiments
四、总结
本文作者提出的思路可以总结如下:
1、为了减少带有蒙版的人物图像背景杂乱,设计了一个由二元蒙版引导的对比注意模型。它可以生成一对身体感知和背景感知的注意力图,可用于生成身体和背景的特征。
1、作者进一步提出从完整图像,身体和背景的特征区域级三联体损失。它可以强制模型学习的特征对背景杂乱不变。
3、作者探索将身体蒙版作为附加输入并伴随RGB图像来增强ReID特征学习。二元掩模有两个主要优点:1)它可以帮助减少背景杂乱,2)它包含身份相关的功能,如身体形状信息。