在进行多表查询之前,我们先查询一下部门表和员工表有多少数据。这个可以用count完成。
select count(*) from emp;
select count(*) from dept;
在这里注意,当我们在日常工作中接手一个新的库的时候,都会要一开始去看看这个库里的内容是什么,最后不要进行select *操作,如果数据量异常庞大会出现巨卡的情况...
我们应该做的是先执行:select count(*),看一下到底有多少数据,如果数据少的话,再进行select *操作。得到的结果是emp中有10条数据,dept中有3条数据。
现在来执行select * from emp,dept;

返回了三十条数据,也就是3*10条。这类似于是emp表中的每一个元素都跟dept表中的每一个元素组合了一下。这也被称为笛卡尔积,但是这种情况肯定使我们不希望出现的,
那就要消除笛卡尔积,消除的办法是找到两个表中存在的关联字段。这两个表都有公共字段deptno
select * from emp e,dept d where e.deptno=d.deptno
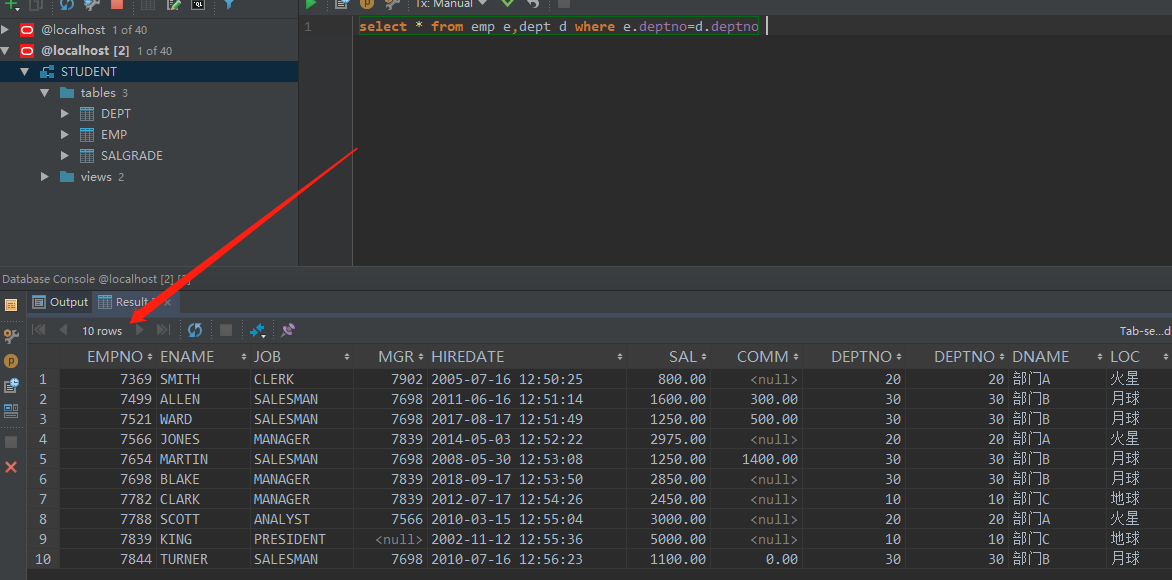
虽然显示出来的是已经消除了笛卡尔积的结果,但是oracle在执行的时候是吧之前那30条数据都查出来,然后又执行了“e.deptno=d.deptno”这个操作,所以多表查询的效率是很慢的(前提是数据量巨大)。
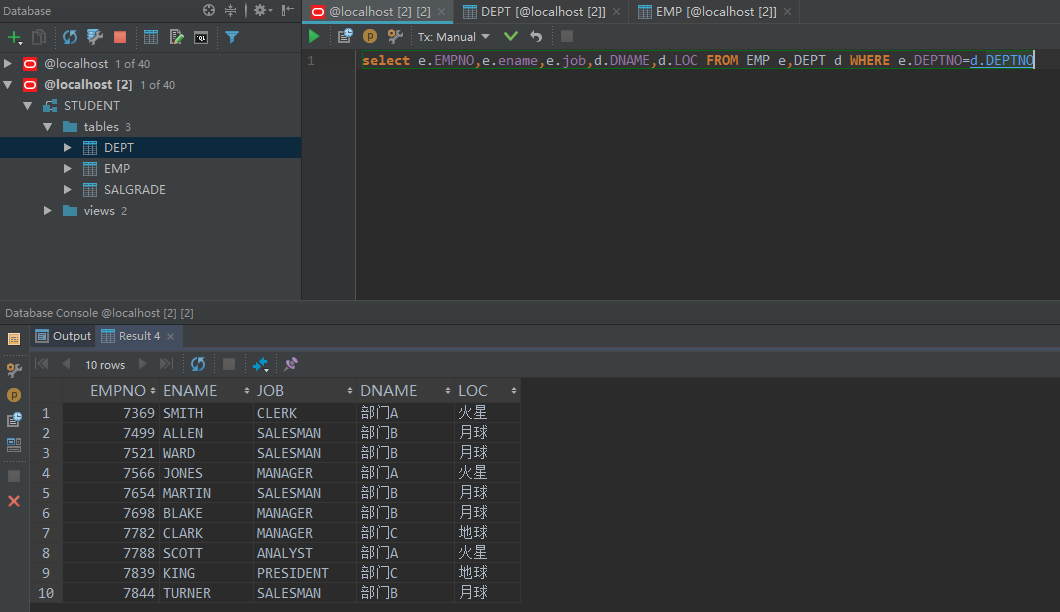
范例:查询出每一位雇员的编号、姓名、职位、部门名称、位置
select e.EMPNO,e.ename,e.job,d.DNAME,d.LOC FROM EMP e,DEPT d WHERE e.DEPTNO=d.DEPTNO
范例:要求查询出每一位雇员的姓名、职位、领导的姓名。
这次查的内容都是在emp这个表里的,可以说是查雇员的信息用一次emp,查领导的信息用一次emp,所以我们这么来做
SELECT e1.ename 员工姓名,e1.JOB 职位,e2.ENAME 领导姓名 FROM EMP e1, EMP e2 where e1.MGR=e2.EMPNO
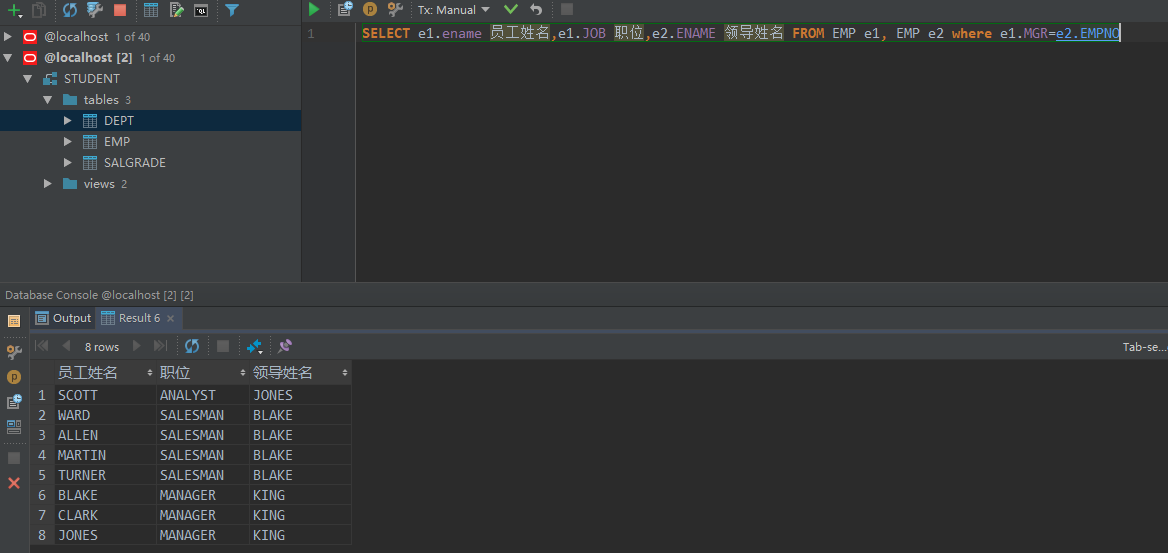
本查询的关键是 员工的上级编号=上级的员工编号