爬虫并没有固定的形式,必须对具体网页作具体写法。
下面以腾讯新闻(http://news.qq.com/)为例子。
--------------------------------------------------------------------------------------------------------------------
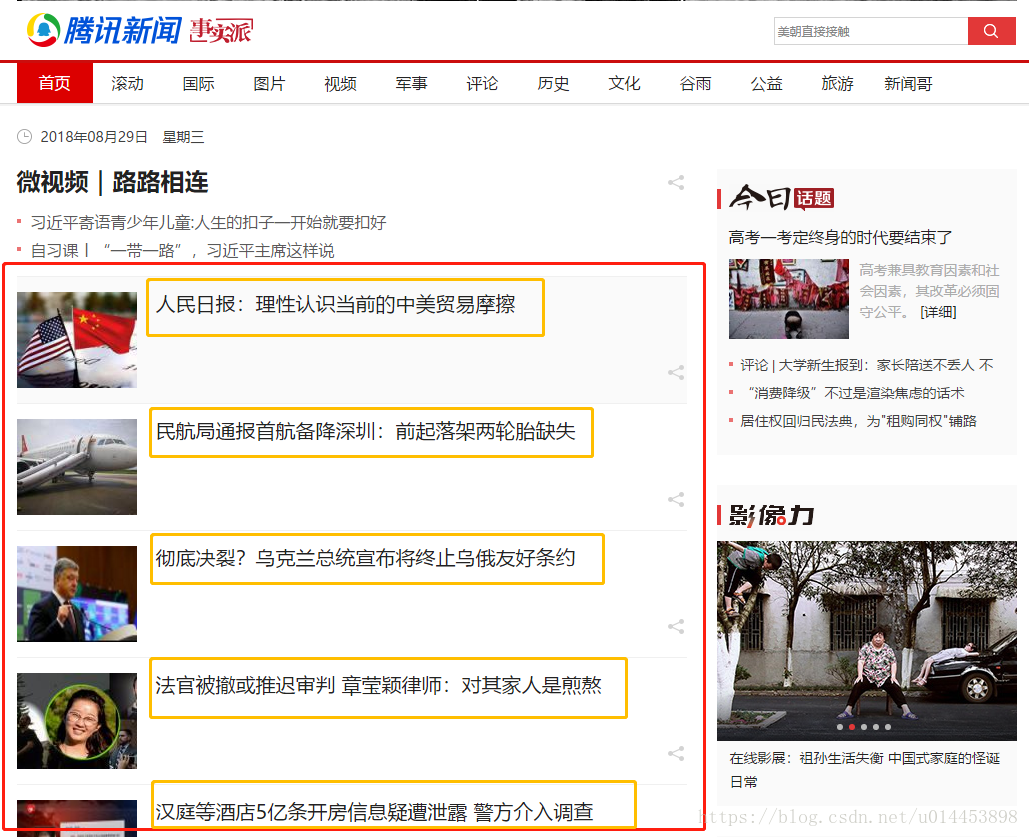
若我们要抓取黄色框内的标题,要怎么做呢?(以谷歌浏览器为例)
首先要在浏览器中,右键-->检查 。我们看到下图右边的框:

右边的代码看起身不太懂的也没关系。当我们把鼠标放到上图红色框那里的时候,可以看到网页中有地方会变蓝,变蓝的就是鼠标点的代码所控制的地方。于是,我们按一下代码最左边的图标以展开代码:

代码展开后看上去很恐怖,但也没关系,我们用鼠标顺着代码从上而下滑,但鼠标指到红色框那行时,可以看到,我们需要提取的文章标题(需要的部分)被包含到蓝色区域中。因此我们展开右面红色框的代码....。重复这个步骤直到:

直到我们需要的被蓝色区域包括起来,如上图。(这样做的原因是,我们需要了解我们需要提取的部分在html中是如何被描述的)
我们继续展开后:

终于看到html代码中出现网页文章的标题以及该文章的链接(红色框中href后面的就是链接)!没错,这就是我们要提取的东西。
从上图中我们可以看到,我们需要的东西是被包含在<a>标签中的class="linkto"中的。(一般来说,只要是同一类的东西,如网页中各个文章的标题,他在html中的描述方式都是一样的) 因此我们就可以写代码了。
---------------------------------------------------------------------------------------------------------------------
写代码之前,先简单介绍一下代码中容易用到的库。(requests 和 beautifulsoup4).
前者用于向网页发送请求,提取网页的html。后者用于对html进行信息过滤,提取有用的信息。
---------------------------------------------------------------------------------------------------------------------
代码:
import requests
from bs4 import BeautifulSoup # Beautiful Soup是一个可以从HTML或XML文件中提取结构化数据的Python库
#要爬的网页
url = "http://www.news.qq.com/"
# 构造头文件,模拟浏览器访问,否则访问个别网页会出现403错误,headers可以随便复制一个即可我的前第一篇爬虫文章中有些如何获取headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
#用requests库中的gete方法向网页发送请求
page = requests.get(url)
#获取html
html=page.text
#print(html)
# 将获取到的内容转换成BeautifulSoup格式,并将html.parser作为解析器
soup = BeautifulSoup(html, 'html.parser')
# 查找html中所有a标签中class='linkto'的语句,所查找到的内容返回到变量titles中
titles = soup.find_all('a', 'linkto')
# open()是读写文件的函数,with语句会自动close()已打开文件
with open(r"D:\aaa.txt", "w",encoding='utf-8') as file: # 在D盘中打开/创建一个名为 aaa 的txt文件
for title in titles: #遍历titles中的每个元素
file.write(title.string+'\n') #向文件中写入title的字符串(即文章的标题),并换行
file.write(title.get('href') + '\n\n') #向文件中写入文章的链接,并两次换行
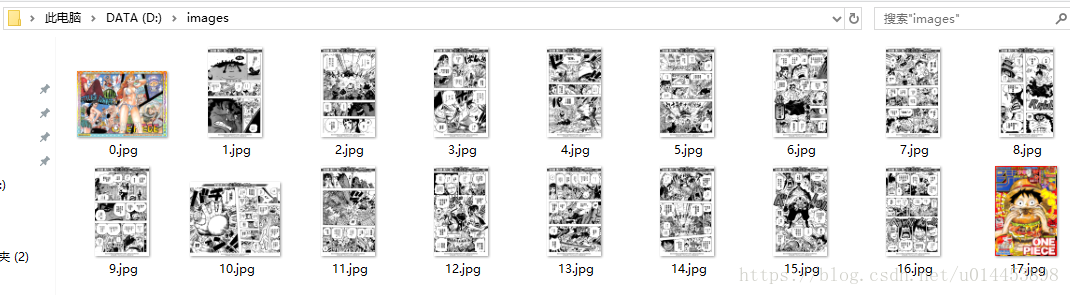
效果:打开D盘中的aaa.txt

即可爬取网页的文章标题和链接
接下来是爬单个网页图片:
以https://tieba.baidu.com/p/5862601928#121759386310l为例,主要方法如上,一步步从html中找到自己要爬取的东西的信息。
代码如下:
import requests
import re
from urllib import request
from bs4 import BeautifulSoup # Beautiful Soup是一个可以从HTML或XML文件中提取结构化数据的Python库
#要爬的网页
url = "https://tieba.baidu.com/p/5862601928#121759386310l"
# 构造头文件,模拟浏览器访问,否则访问个别网页会出现403错误,headers可以随便复制一个即可我的前第一篇爬虫文章中有些如何获取headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
#用requests库中的gete方法向网页发送请求
page = requests.get(url)
#获取html
html=page.text
#print(html)
# 将获取到的内容转换成BeautifulSoup格式,并将html.parser作为解析器
soup = BeautifulSoup(html, 'html.parser')
# 查找html中所有img标签中class='BDE_Image'并且src中的内容以“.jpg”结尾的语句,所查找到的内容返回到变量links中
links = soup.find_all('img','BDE_Image',src=re.compile(r'.jpg$')) #src的内容一般都是图片的链接
# open()是读写文件的函数,with语句会自动close()已打开文件
path=r'D:\images'
n=0
for link in links:
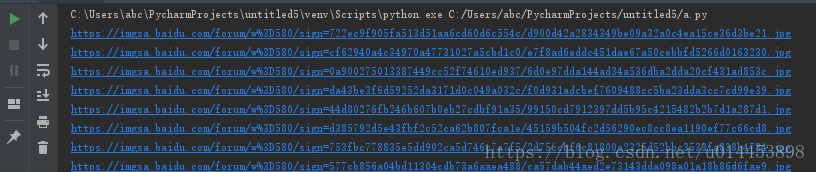
print(link.attrs['src']) #打印图片的链接
request.urlretrieve(link.attrs['src'],path+'\%s.jpg' %n) #用urlretrieve下载到本地
n+=1效果:
控制台打印信息:
文件夹爬取的图片: